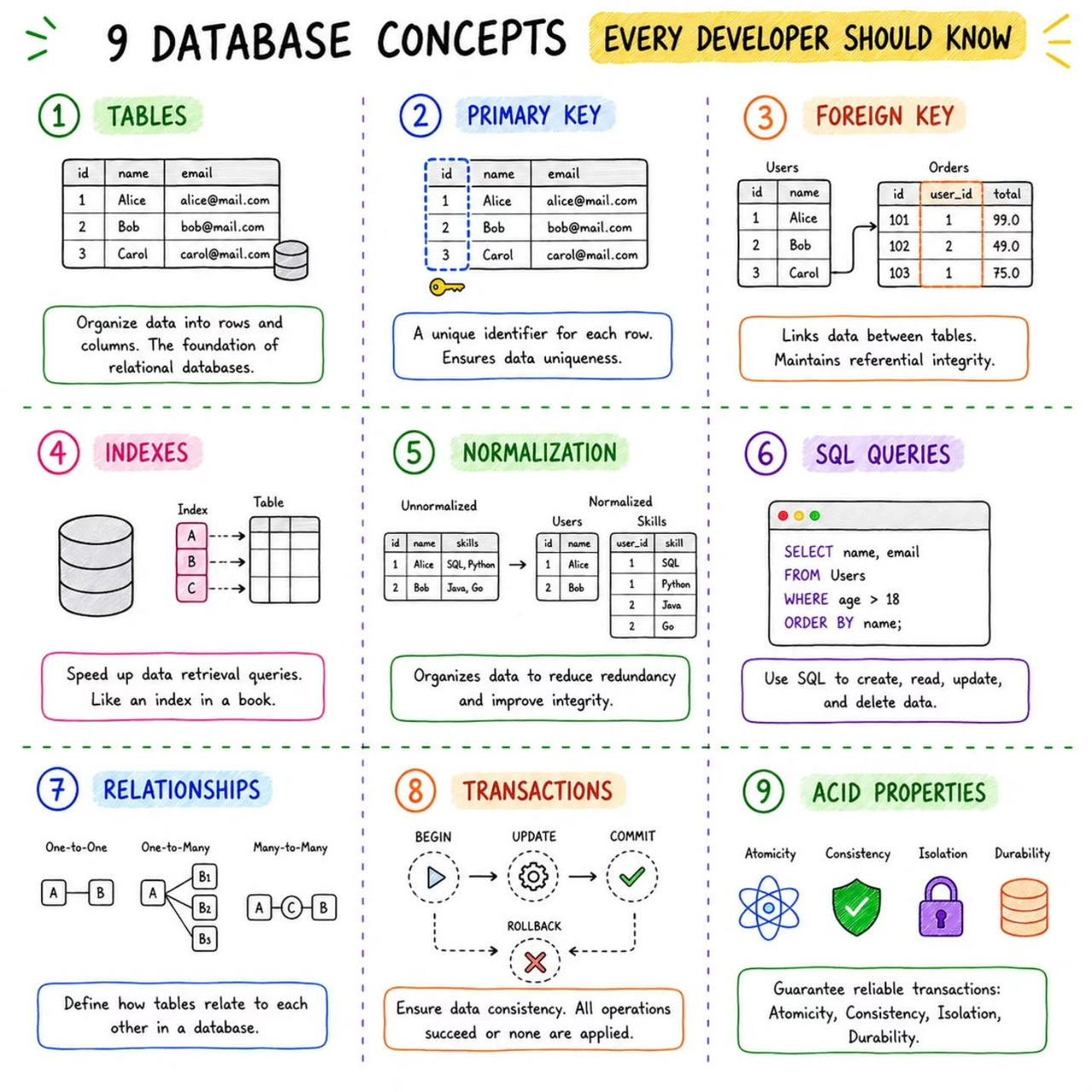
databases
Redis Use Cases
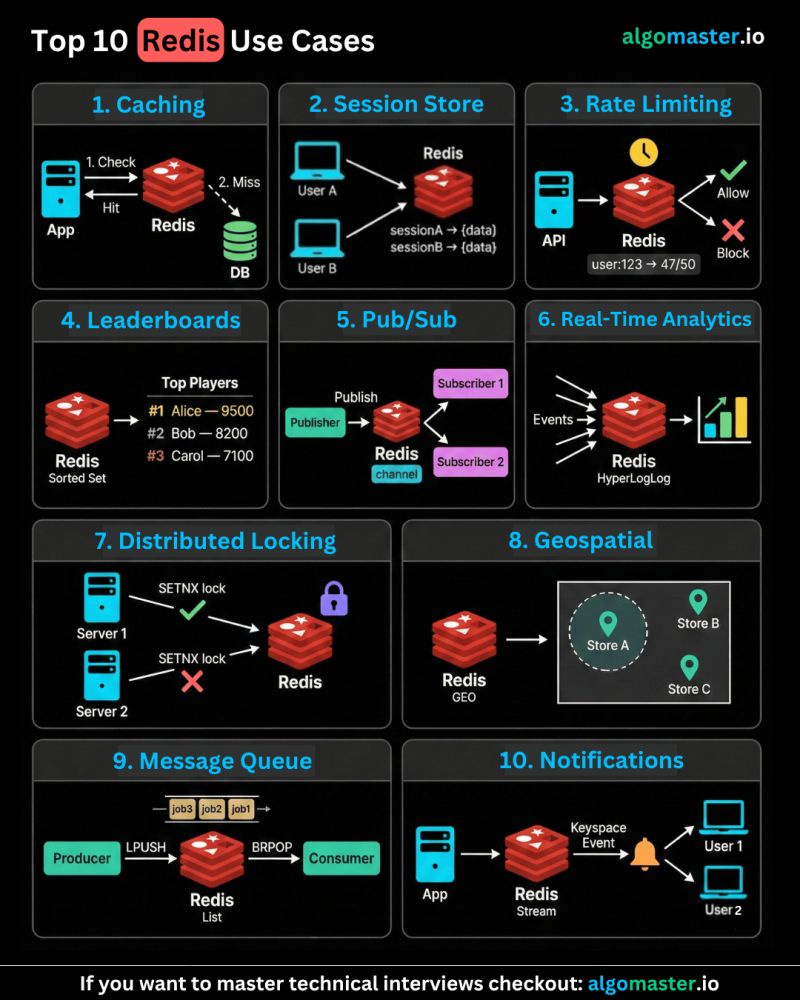
1. 𝐂𝐚𝐜𝐡𝐢𝐧𝐠 The most common use case. Your app checks Redis before hitting the database. If the key exists, return it instantly. If not, query the DB, store the result in Redis, and serve it.
2. 𝐒𝐞𝐬𝐬𝐢𝐨𝐧 𝐒𝐭𝐨𝐫𝐞 When a user logs in, store their session data (user ID, roles, preferences) in Redis. Every subsequent request just looks up the session key.
3. 𝐑𝐚𝐭𝐞 𝐋𝐢𝐦𝐢𝐭𝐢𝐧𝐠 Redis makes rate limiting trivial. Use INCR to increment a request counter and EXPIRE to reset it after a fixed window. If the count exceeds the limit, throttle or block the request.
4. 𝐋𝐞𝐚𝐝𝐞𝐫𝐛𝐨𝐚𝐫𝐝𝐬 Redis Sorted Sets keep users ranked by score in real time. You can update scores, fetch the top N users, and find a user’s rank efficiently in O(log N) operations.
5. 𝐏𝐮𝐛/𝐒𝐮𝐛 𝐌𝐞𝐬𝐬𝐚𝐠𝐢𝐧𝐠 Publishers send messages to a channel, and subscribers receive them instantly. Great for chat, live notifications, and dashboards. Trade-off: messages are fire-and-forget.
6. 𝐑𝐞𝐚𝐥-𝐓𝐢𝐦𝐞 𝐀𝐧𝐚𝐥𝐲𝐭𝐢𝐜𝐬 Use counters and HyperLogLog to track clicks, views, searches, unique visitors, and active users with very low memory usage.
7. 𝐃𝐢𝐬𝐭𝐫𝐢𝐛𝐮𝐭𝐞𝐝 𝐋𝐨𝐜𝐤𝐢𝐧𝐠 Redis SETNX (SET if Not eXists) lets you acquire a lock atomically. Set it with a TTL so locks auto-release if a process crashes. For stronger guarantees, use the Redlock algorithm.
8. 𝐆𝐞𝐨𝐬𝐩𝐚𝐭𝐢𝐚𝐥 𝐐𝐮𝐞𝐫𝐢𝐞𝐬 Redis GEO commands let you store coordinates and query nearby locations, such as restaurants within 5 km or drivers near a user. It uses sorted sets with geohash encoding under the hood.
9. 𝐌𝐞𝐬𝐬𝐚𝐠𝐞 𝐐𝐮𝐞𝐮𝐞 Redis Lists with LPUSH and BRPOP can act as a lightweight queue for simple background jobs. For more advanced use cases, Redis Streams are a better fit.
10. 𝐑𝐞𝐚𝐥-𝐓𝐢𝐦𝐞 𝐍𝐨𝐭𝐢𝐟𝐢𝐜𝐚𝐭𝐢𝐨𝐧𝐬 Redis Streams provide an append-only log with consumer groups. Keyspace Notifications let you subscribe to changes on specific keys. Useful for notifications, activity feeds, background processing, and real-time pipelines.
How Databases Work
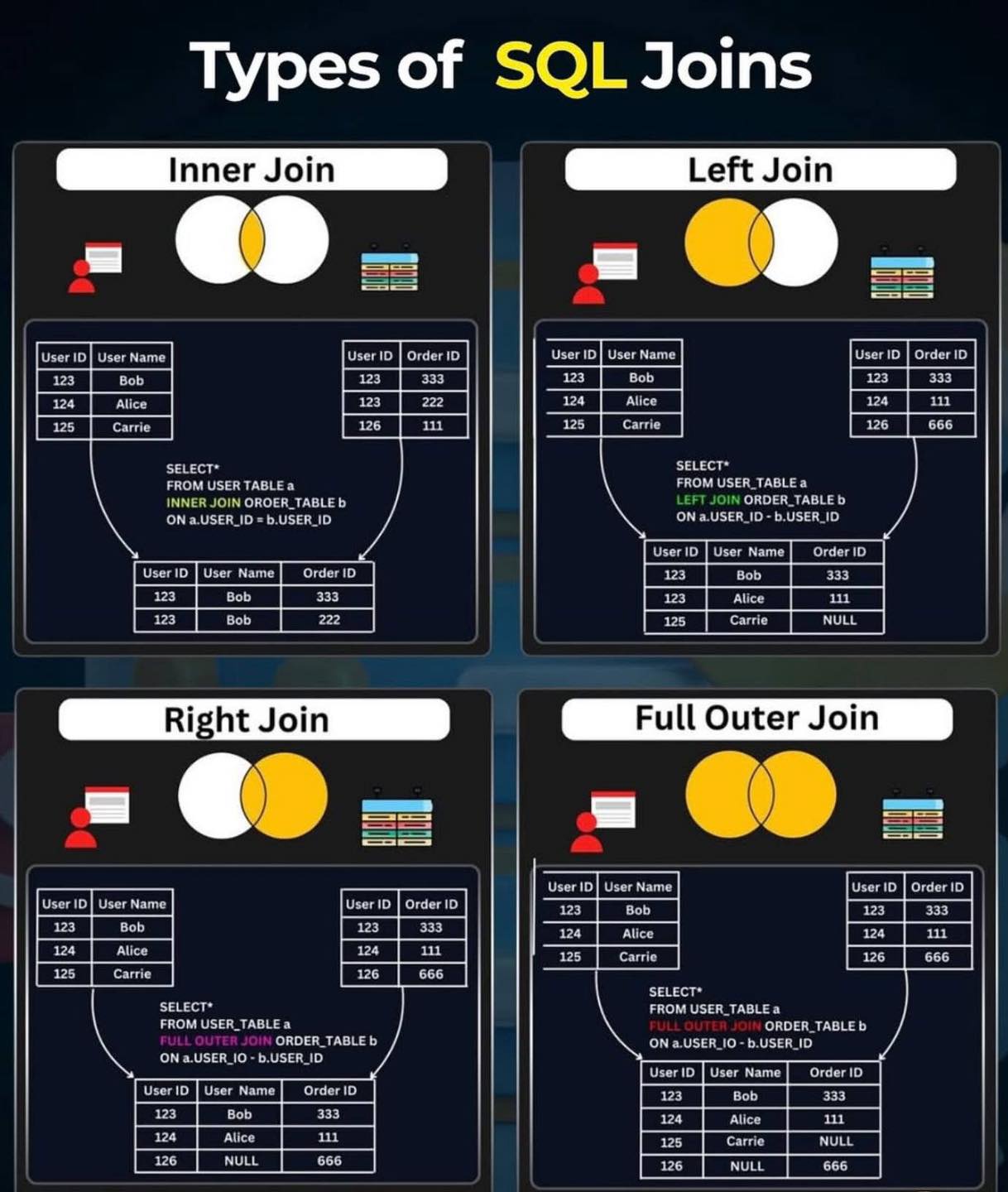
SQL Joins
Back-End Tech Stack
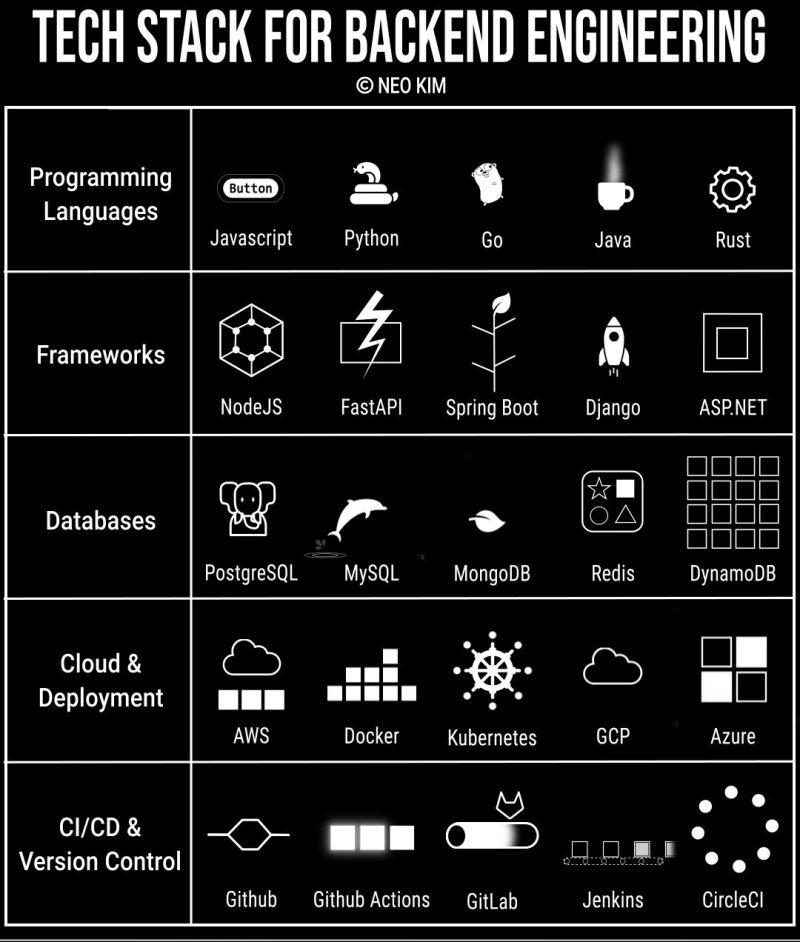
#back-end #tech-stack #programming #ci-cd #databases #cloud
Here are 5 best Tech Stack & Resources
A strong backend foundation often includes:
Node.js— for scalable server-side applications
PostgreSQL / MongoDB— for structured and flexible data handling
Redis— for caching and performance optimization
RabbitMQ —for event-driven communication
AWS— for scalable infrastructure.
- Focus on real-world system design case studies. Study how large-scale systems handle traffic and failures
- Build small projects that simulate real-world load
- Backend engineering is not just about making systems work.It is about making sure they continue to work as usage grows and complexity increases.
- The difference between a stable system and a failing one often comes down to early design decisions.
- If you are building or scaling backend systems, or looking to improve your system design approach let's discuss share your challenges.
- Let’s build systems that are designed to last.
Database Locks

Database Sharding
Your database was fine – until it wasn't.
One day the queries slow down. Writes start backing up. The single node can't keep up anymore. And suddenly, sharding isn't optional.
But sharding done wrong is worse than not sharding at all 👇
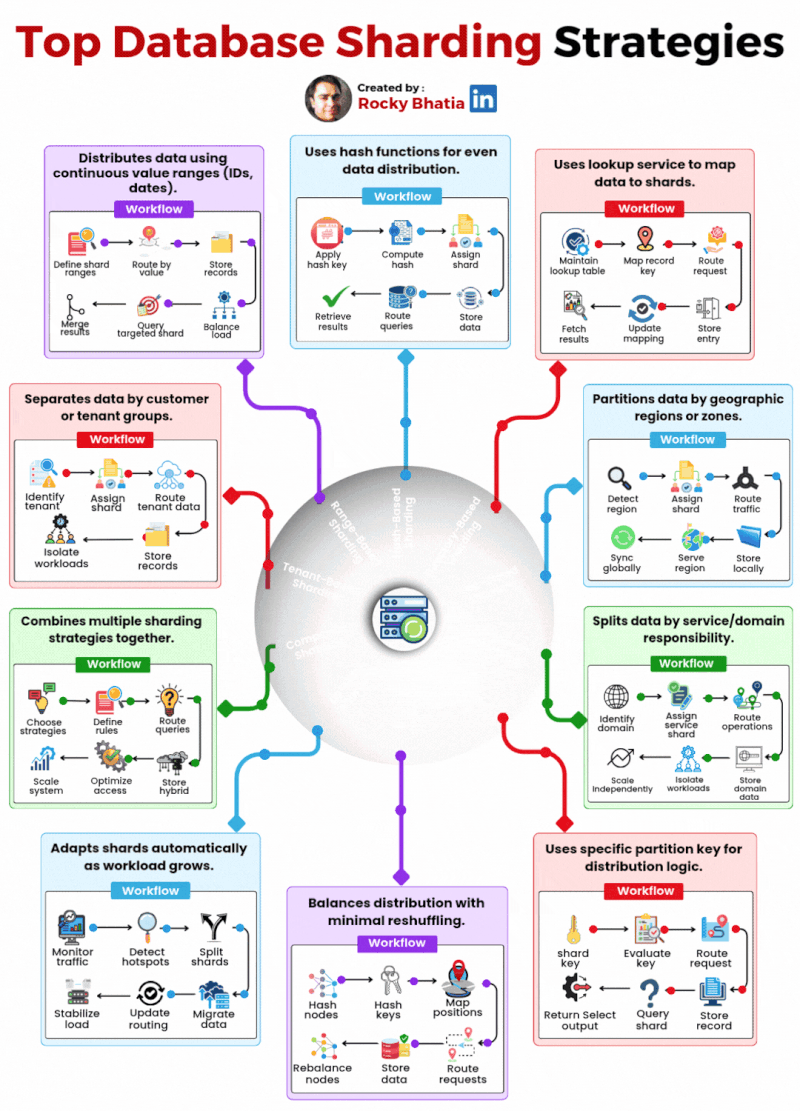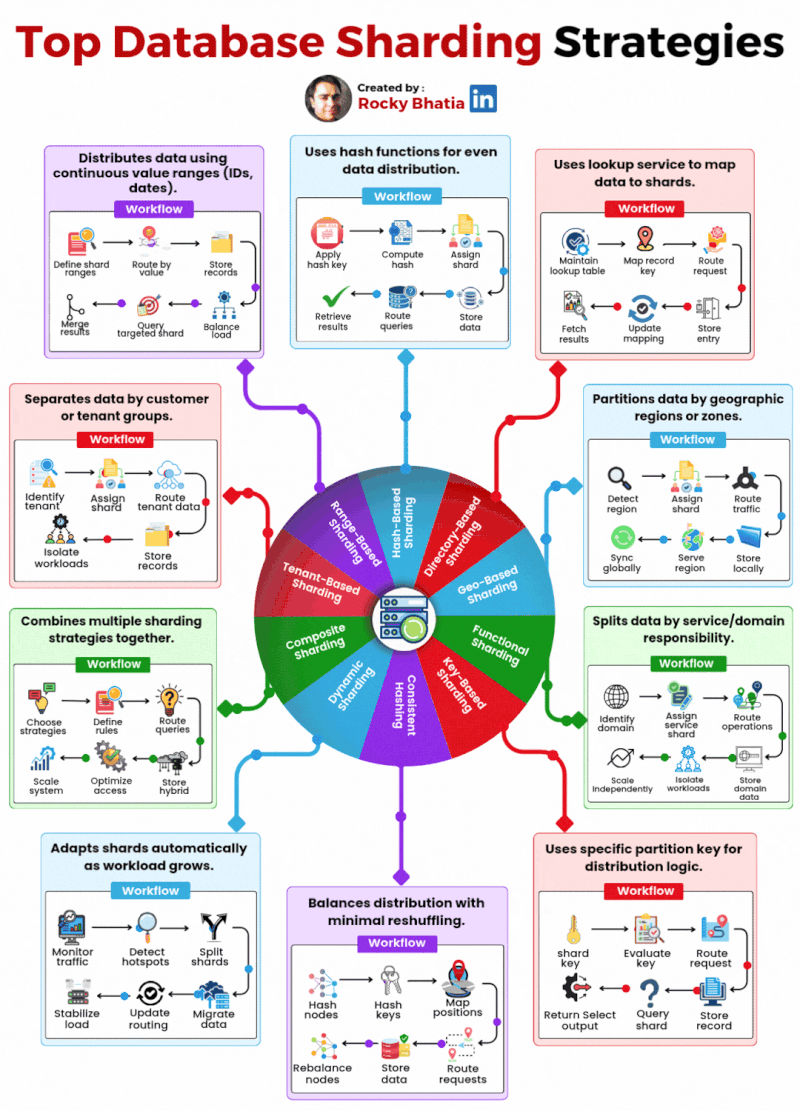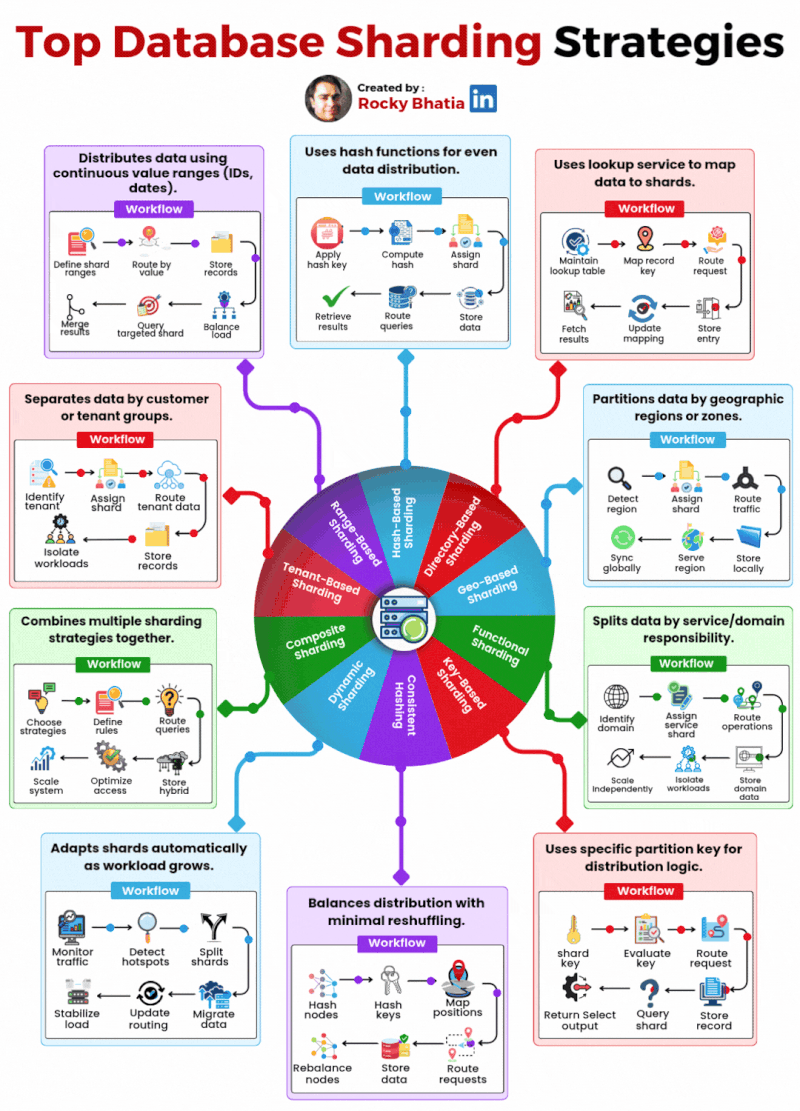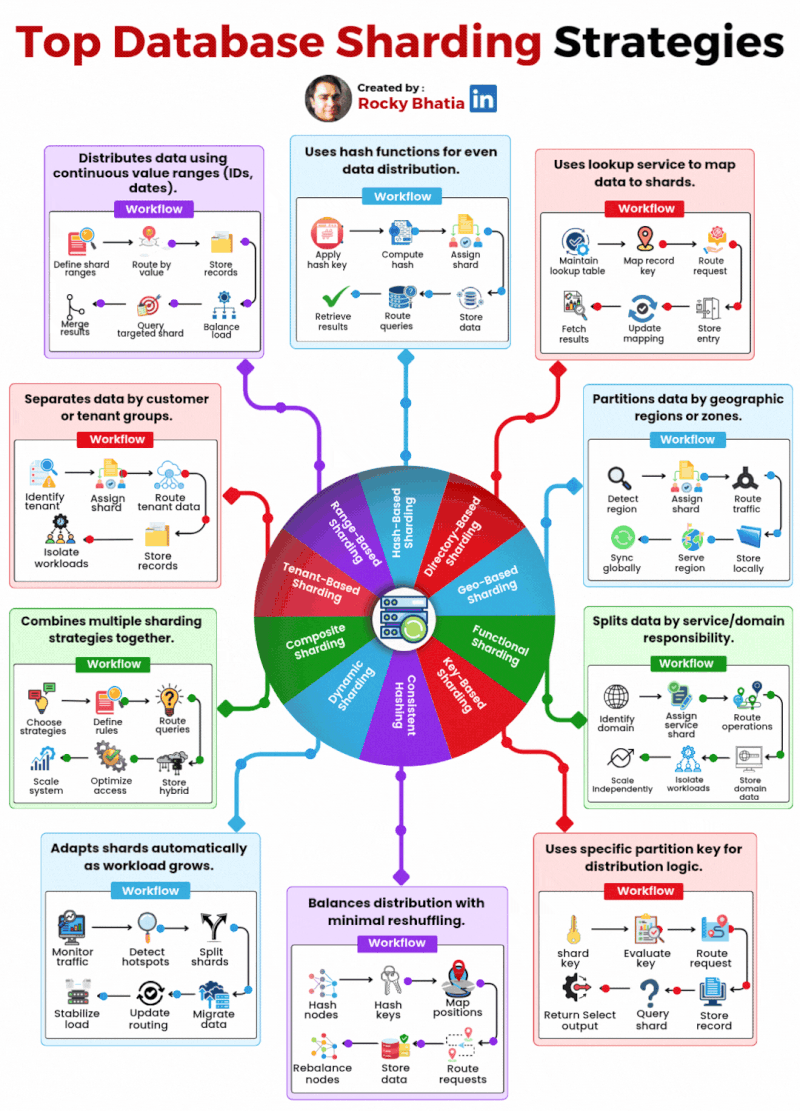
Here are the 10 database sharding strategies powering production systems today:
Range-Based – Distributes data using continuous value ranges like IDs or dates. Simple but can create hot spots.
Hash-Based – Uses hash functions for even data distribution across shards. Great balance, harder to range query.
Directory-Based – A lookup service maps data to shards. Flexible but adds a dependency.
Geo-Based – Partitions data by geographic region. Essential for latency-sensitive global systems.
Functional – Splits data by service or domain responsibility. Clean boundaries, scales independently.
Key-Based – Uses a specific partition key for distribution logic. Predictable and straightforward.
Consistent Hashing – Balances distribution with minimal reshuffling when nodes are added or removed.
Dynamic Sharding – Adapts shards automatically as workload grows. Operationally complex but powerful.
Composite – Combines multiple strategies together. Maximum flexibility, maximum complexity.
Tenant-Based – Separates data by customer or tenant. Perfect for multi-tenant SaaS architectures.
The rule most engineers learn too late: There's no universally correct sharding strategy. The right one depends on your query patterns, scale requirements, and team's operational maturity.
Start with the simplest approach that solves your problem.
Optimize when the bottleneck proves it.
12 Essential Programmer Concepts

#programmingconcepts #systemdesign #security #coding #datastructures #algorithms #networking #versioncontrol #git #databases #api #agile
These comprehensive set of concepts forms a strong foundation for programmers, covering a range of skills from programming fundamentals to system design and security considerations.
1. Introduction to Programming Languages: A foundational understanding of at least one programming language (e.g., Python, Java, C++), enabling the ability to comprehend and switch between languages as needed.
2. Data Structures Mastery: Proficiency in fundamental data structures such as arrays, linked lists, stacks, queues, trees, and graphs, essential for effective algorithmic problem solving.
3. Algorithms Proficiency: Familiarity with common algorithms and problem solving techniques, including sorting, searching, and dynamic programming, to optimise code efficiency. ** 4. Database Systems Knowledge:** Understanding of database systems, covering relational databases (e.g., SQL) and NoSQL databases (e.g., MongoDB), crucial for efficient data storage and retrieval.
5. Version Control Mastery: Proficiency with version control systems like Git, encompassing skills in branching, merging, and collaboration workflows for effective team development.
6. Agile Methodology Understanding: Knowledge of the Agile Software Development Life Cycle (Agile SDLC) principles, emphasizing iterative development, Scrum, and Kanban for adaptable project management.
7. Web Development Basics (Networking): Fundamental understanding of networking concepts, including protocols, IP addressing, and HTTP, essential for web development and communication between systems.
8. APIs (Application Programming Interfaces) Expertise: Understanding how to use and create APIs, critical for integrating different software systems and enabling seamless communication between applications.
9. Testing and Debugging Skills: Proficiency in testing methodologies, unit testing, and debugging techniques to ensure code quality and identify and fix errors effectively.
10. Design Patterns Familiarity: Knowledge of common design patterns in object-oriented programming, aiding in solving recurring design problems and enhancing code maintainability.
11. System Design Principles: Understanding of system design, including architectural patterns, scalability, and reliability, to create robust and efficient software systems.
12. Security Awareness: Fundamental knowledge of security principles, including encryption, authentication, and best practices for securing applications and data.
Other areas could be OS, containers, concurrency and parallelism , basic web development etc.
SQL CheatSheet
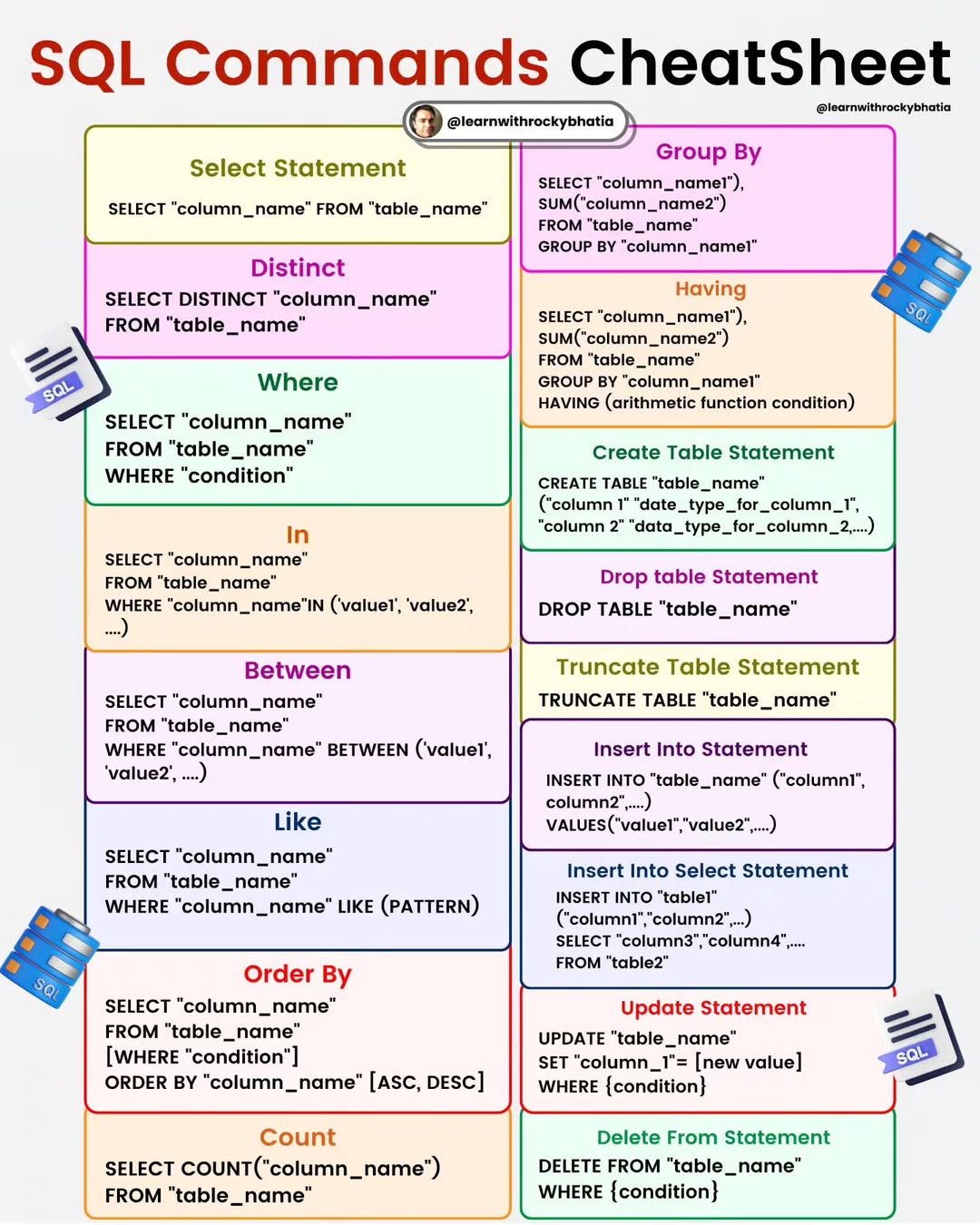
To embark on your journey into the realm of SQL mastery, Please follow following guide:
- Understand what databases are and how they store and organise data.
- Learn about the difference between relational databases and other types of databases. - Familiarise yourself with the basic syntax of SQL queries. -Learn how to use SQL to retrieve data from a database using the SELECT statement.
- Explore different clauses like WHERE, ORDER BY, GROUP BY, and HAVING to filter, sort, and group data.
- Learn how to use aggregate functions like COUNT, SUM, AVG, MIN, and MAX.
- Understand how to use INSERT, UPDATE, and DELETE statements to modify data in a database.
- Learn about constraints and how to maintain data integrity.
- Study different types of joins (INNER JOIN, LEFT JOIN, RIGHT JOIN, FULL JOIN) to combine data from multiple tables.
- Learn about primary keys, foreign keys, and how to establish relationships between tables.
- Dive into subqueries and how they can be used within other queries.
- Learn about common table expressions (CTEs) for creating temporary result sets.
- Explore window functions for advanced data analysis.
- Understand more advanced DML concepts like MERGE (UPSERT) statements.
- Learn about transactions and how to manage them using BEGIN, COMMIT, and ROLLBACK.
- Learn about creating, altering, and dropping tables using DDL statements.
- Explore data types, constraints, and indexes.
Remember that learning SQL is an ongoing process. Practice is key, so work on real-world examples and projects to solidify your skills.
PostgreSQL Uses
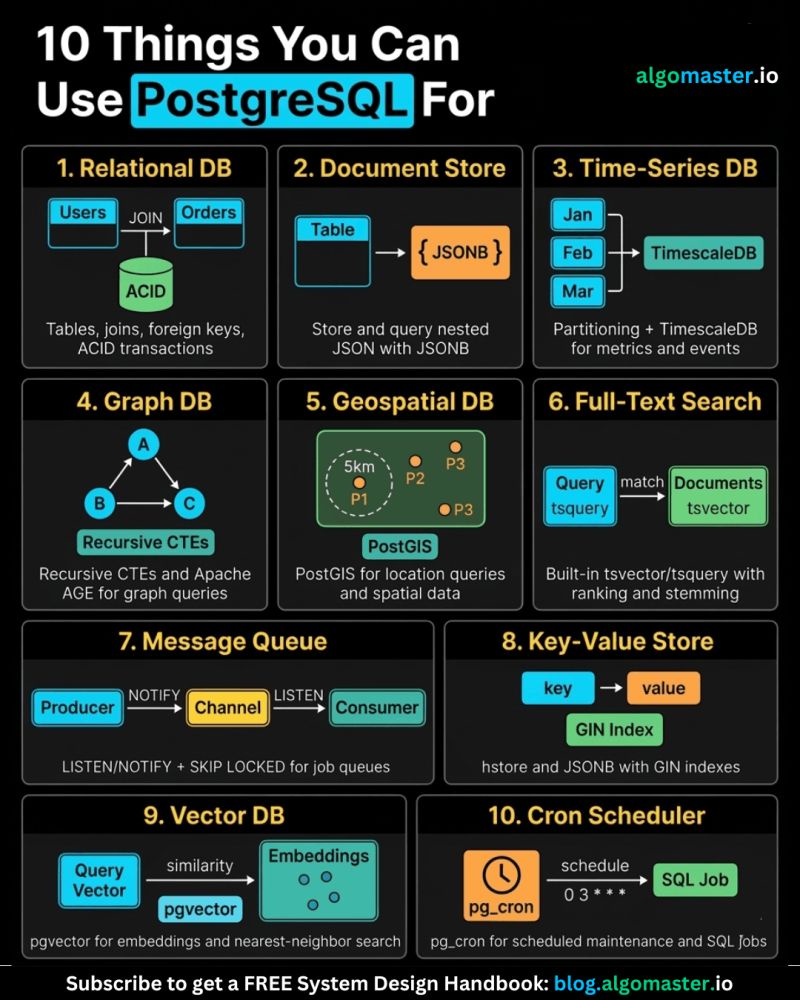
1. 𝐑𝐞𝐥𝐚𝐭𝐢𝐨𝐧𝐚𝐥 𝐃𝐚𝐭𝐚𝐛𝐚𝐬𝐞 The classic use case. PostgreSQL excels at managing structured data with tables, relationships, joins, constraints, and fully ACID-compliant transactions.
2. 𝐃𝐨𝐜𝐮𝐦𝐞𝐧𝐭 𝐒𝐭𝐨𝐫𝐞 PostgreSQL supports JSON and JSONB natively, so you can store and query semi-structured data with ease.
3. 𝐓𝐢𝐦𝐞-𝐒𝐞𝐫𝐢𝐞𝐬 𝐃𝐚𝐭𝐚𝐛𝐚𝐬𝐞 You can use native table partitioning for time-based data, or add TimescaleDB for features like automatic chunking, compression, and continuous aggregates.
4. 𝐆𝐫𝐚𝐩𝐡 𝐃𝐚𝐭𝐚𝐛𝐚𝐬𝐞 Recursive CTEs allow you to model and traverse hierarchies and graph-like relationships directly in SQL. For more advanced graph workloads, the Apache AGE extension brings Cypher query support to PostgreSQL.
5. 𝐆𝐞𝐨𝐬𝐩𝐚𝐭𝐢𝐚𝐥 𝐃𝐚𝐭𝐚𝐛𝐚𝐬𝐞 With PostGIS, PostgreSQL becomes a powerful geospatial database. You can store points, polygons, and other geometries, then run spatial queries like “find all restaurants within 5 km” with excellent performance.
6. 𝐅𝐮𝐥𝐥-𝐓𝐞𝐱𝐭 𝐒𝐞𝐚𝐫𝐜𝐡 𝐄𝐧𝐠𝐢𝐧𝐞 PostgreSQL includes built-in full-text search capabilities through tsvector and tsquery. You get indexing, ranking, stemming, and relevance-based search without needing a separate search engine for many use cases.
7. 𝐌𝐞𝐬𝐬𝐚𝐠𝐞 𝐐𝐮𝐞𝐮𝐞 PostgreSQL can also power lightweight messaging systems. LISTEN/NOTIFY enables pub/sub communication between connections, and SELECT ... FOR UPDATE SKIP LOCKED helps you build reliable job queues directly inside the database.
8. 𝐊𝐞𝐲-𝐕𝐚𝐥𝐮𝐞 𝐒𝐭𝐨𝐫𝐞 Using hstore or JSONB, PostgreSQL can serve as a key-value store as well. Both support indexing, which makes lookups fast. It can be a practical lightweight alternative to Redis for some workloads.
9. 𝐕𝐞𝐜𝐭𝐨𝐫 𝐃𝐚𝐭𝐚𝐛𝐚𝐬𝐞 With the pgvector extension, PostgreSQL can store embeddings and perform vector similarity search. You can create HNSW or IVFFlat indexes and run nearest-neighbor queries, making it a solid option for AI/ML applications.
10. 𝐂𝐫𝐨𝐧 𝐉𝐨𝐛 𝐒𝐜𝐡𝐞𝐝𝐮𝐥𝐞𝐫 With pg_cron, PostgreSQL can schedule recurring jobs directly from the database. This is useful for tasks like cleanup jobs, rollups, reporting, and maintenance workflows.