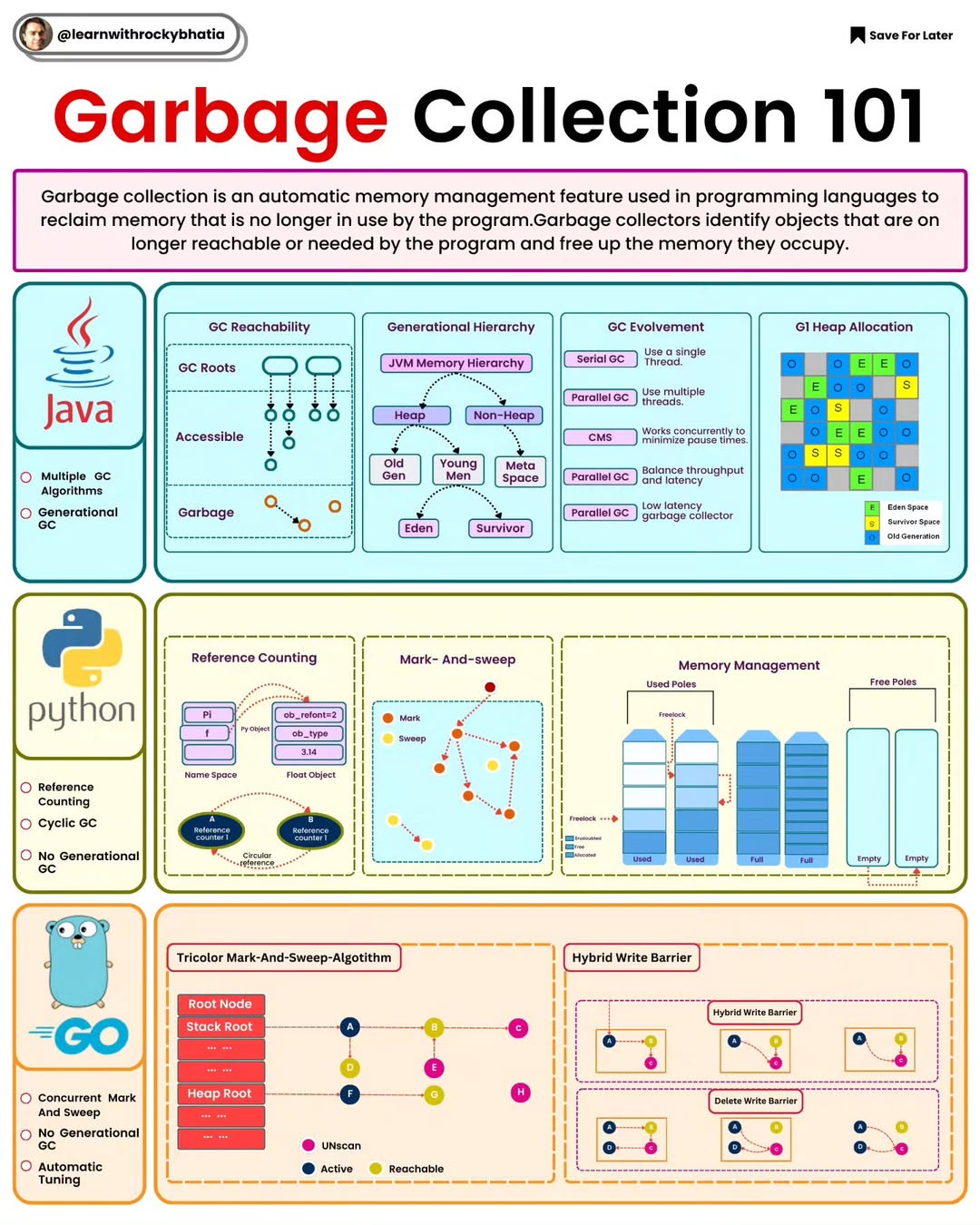
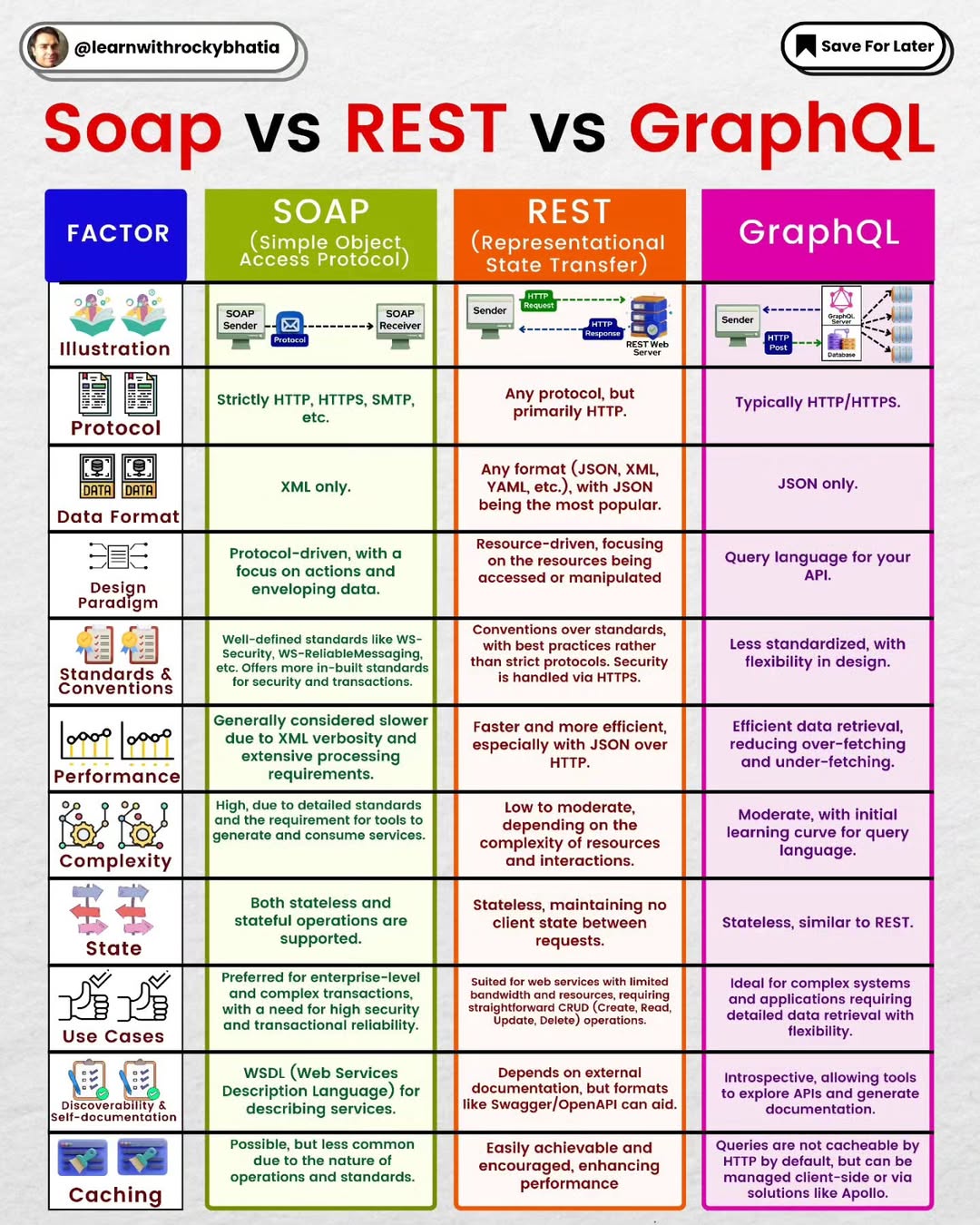
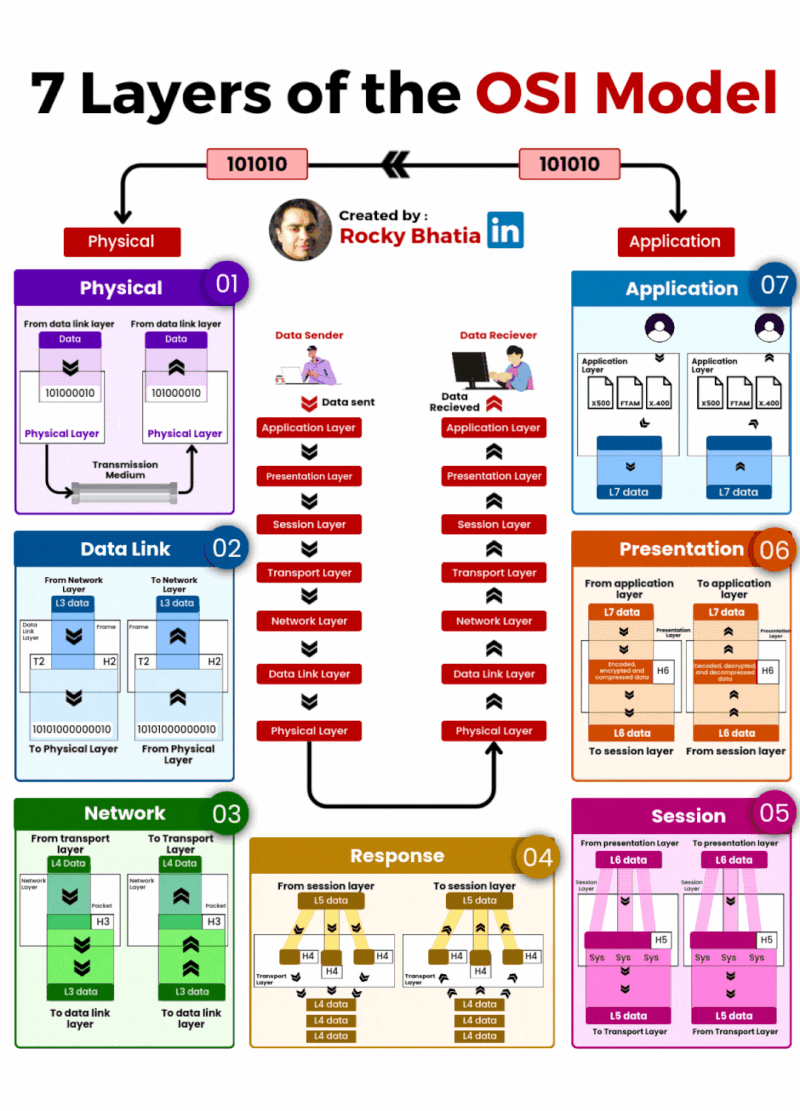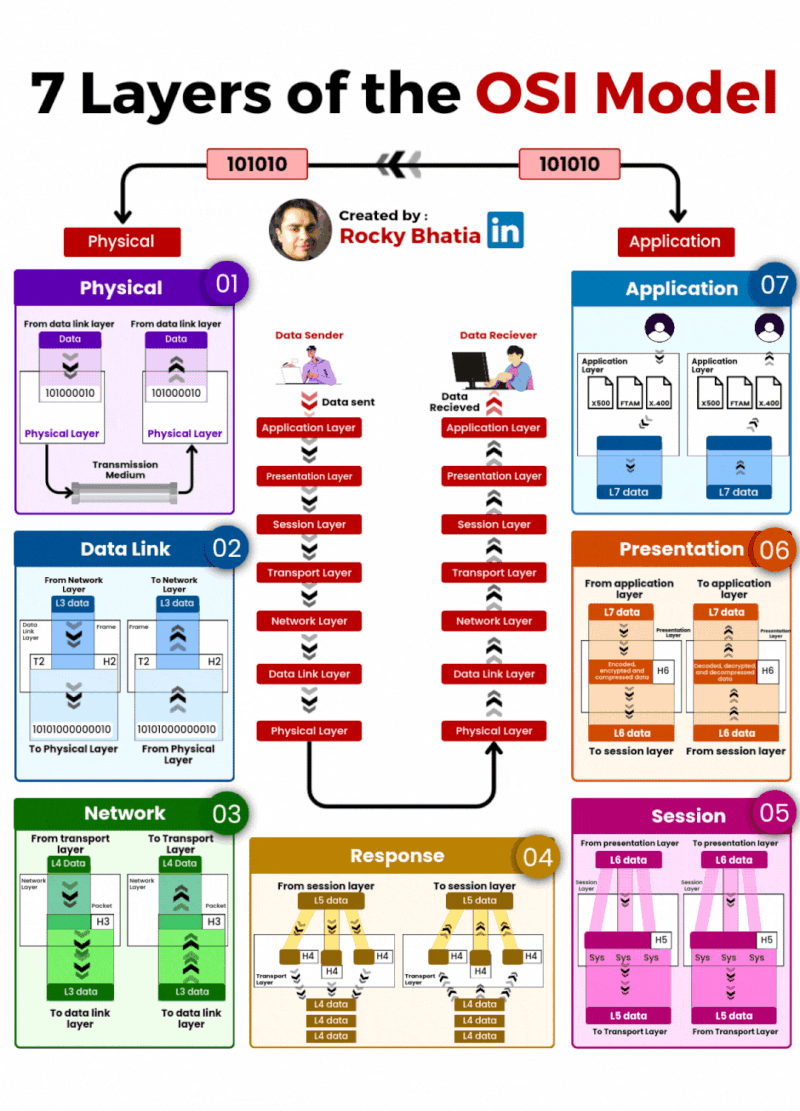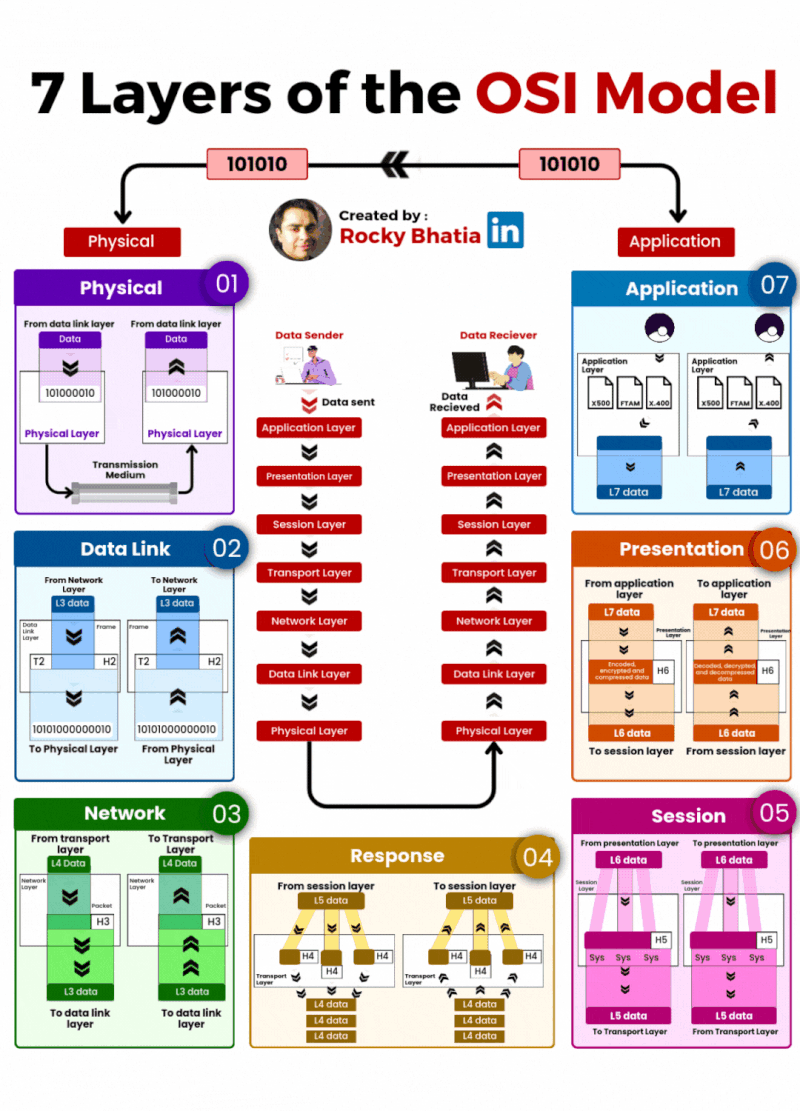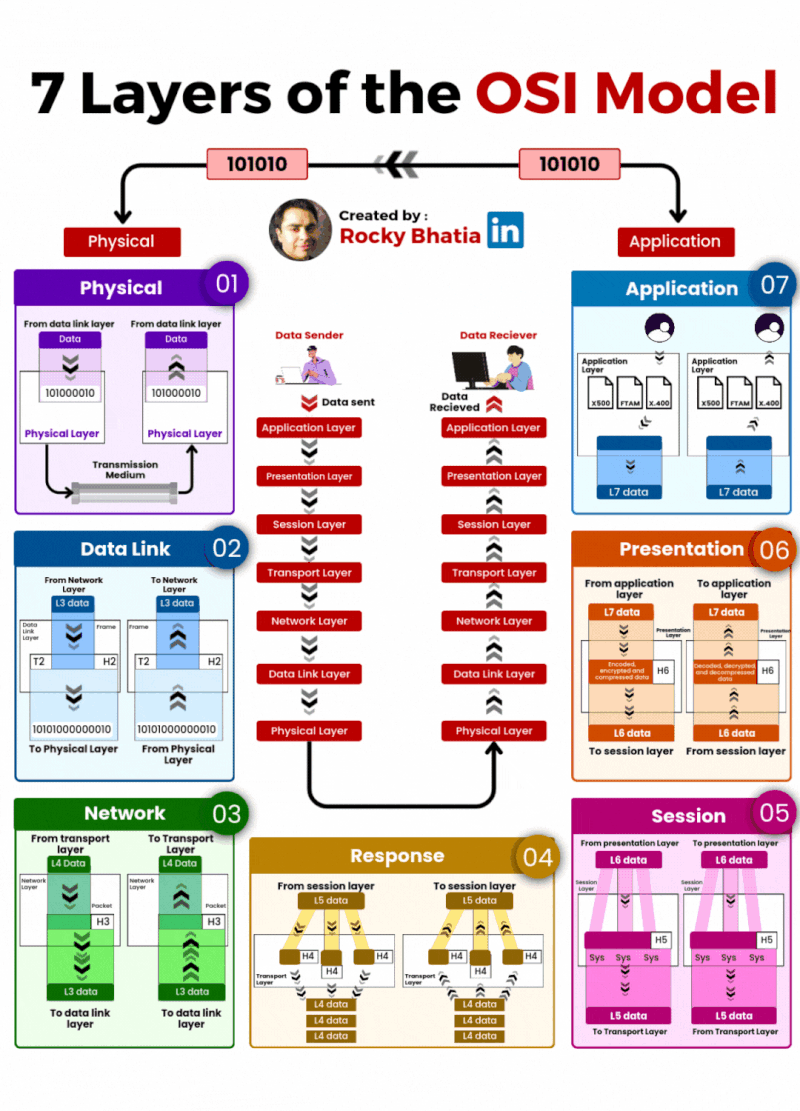
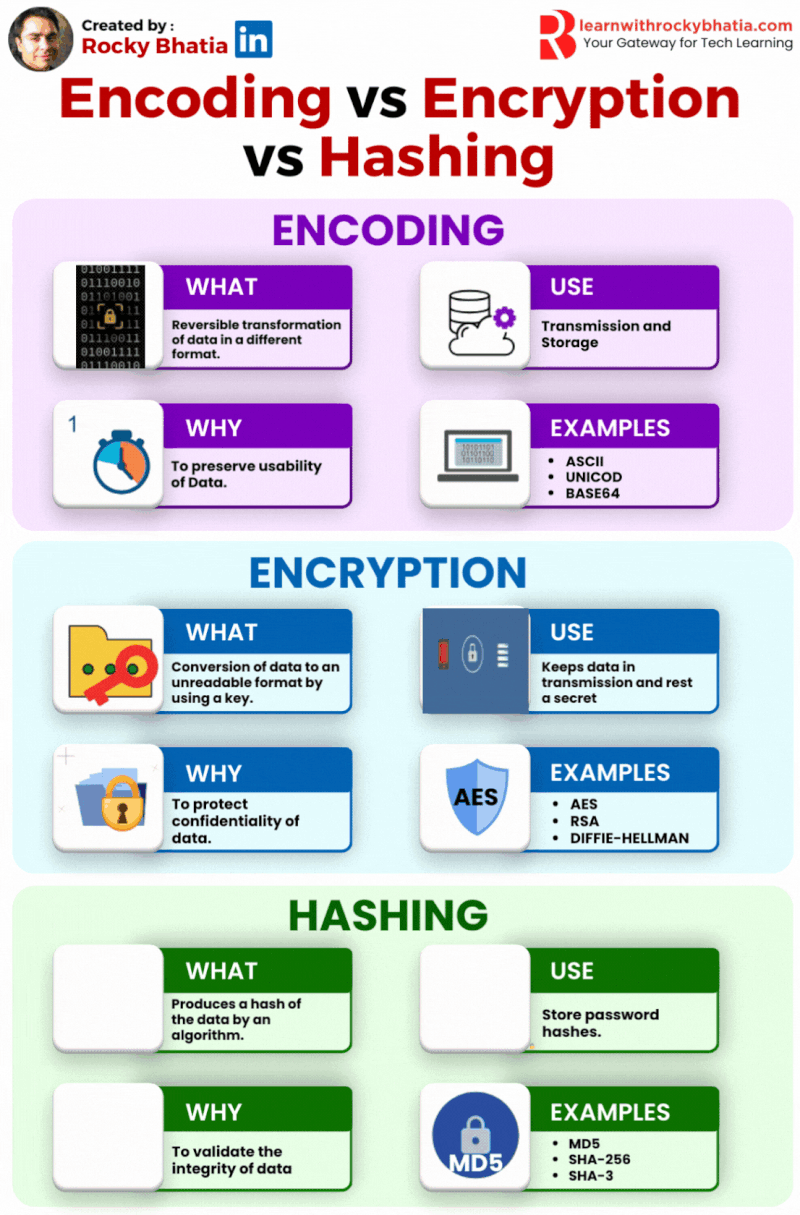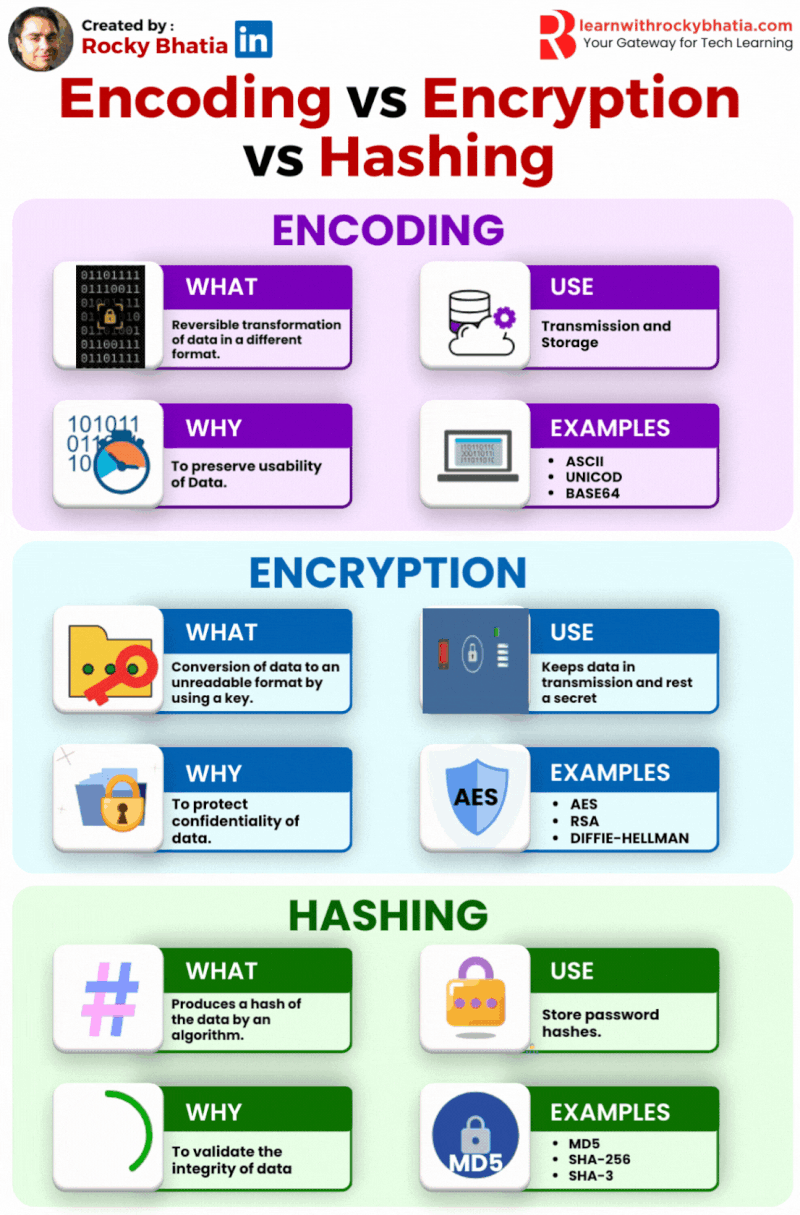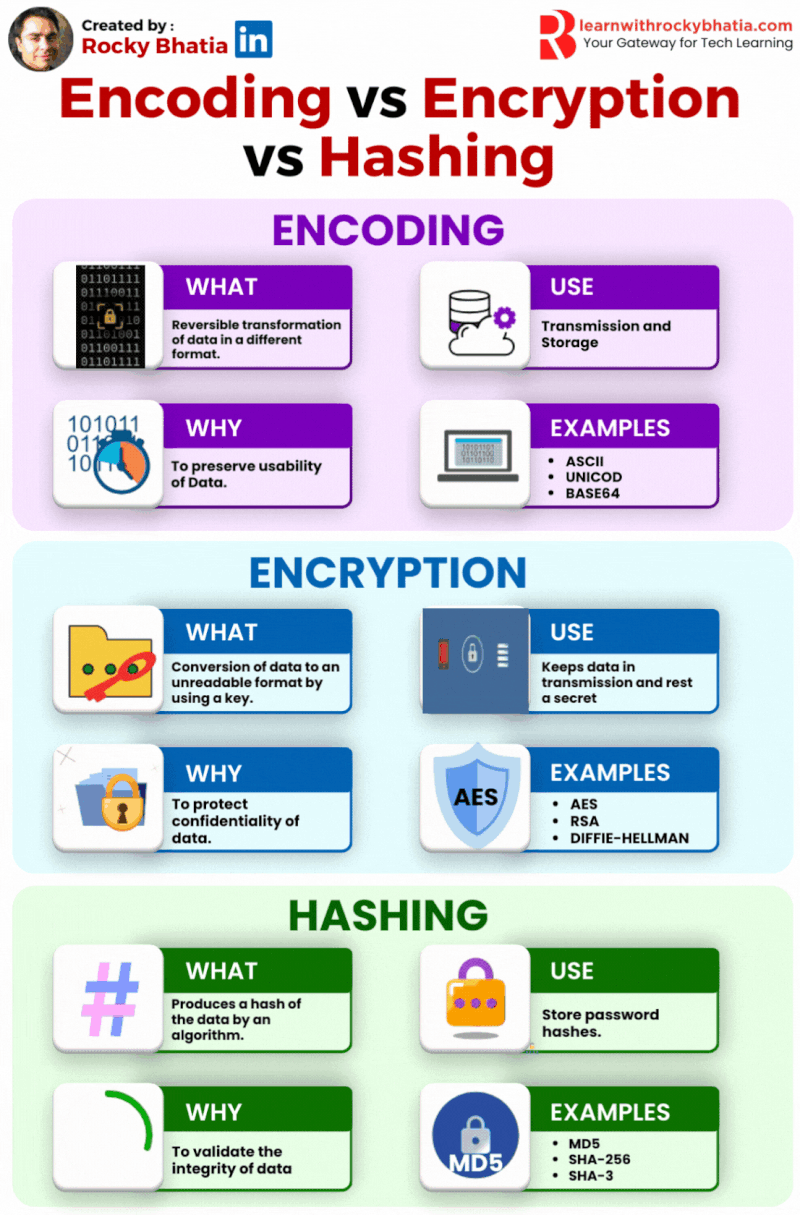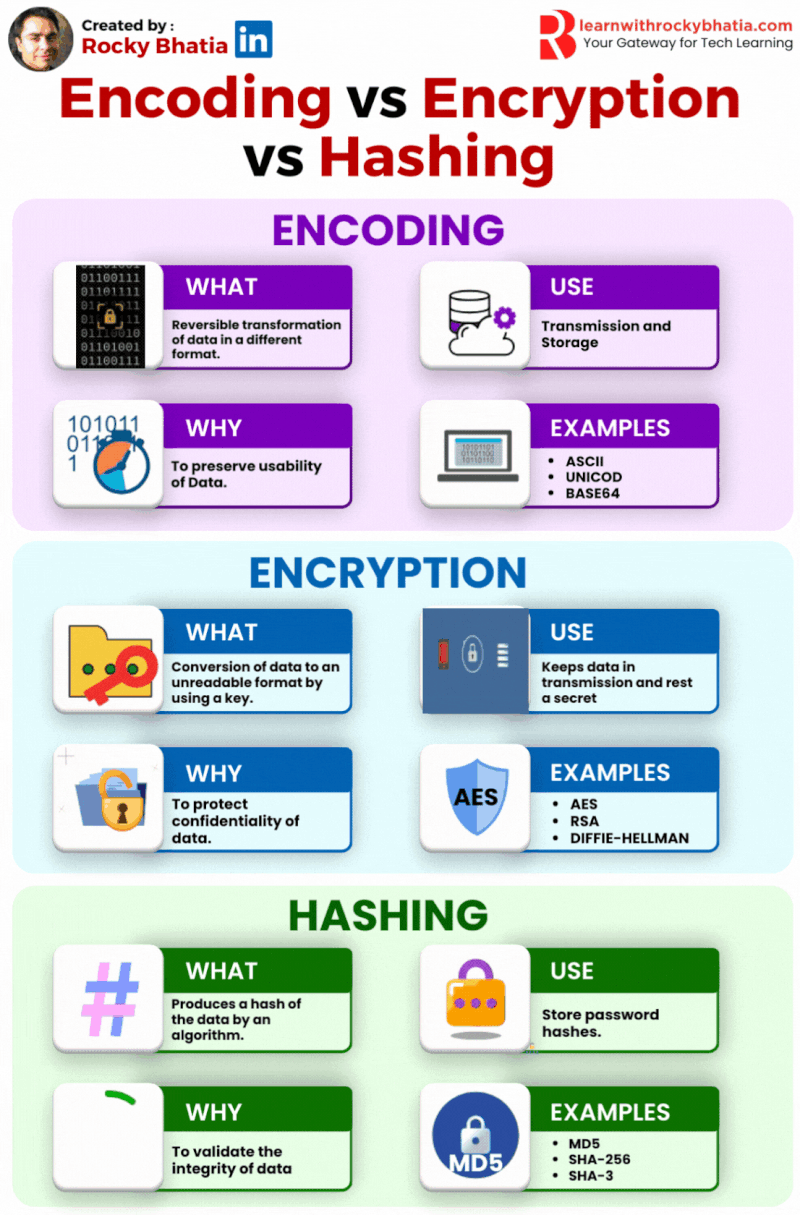
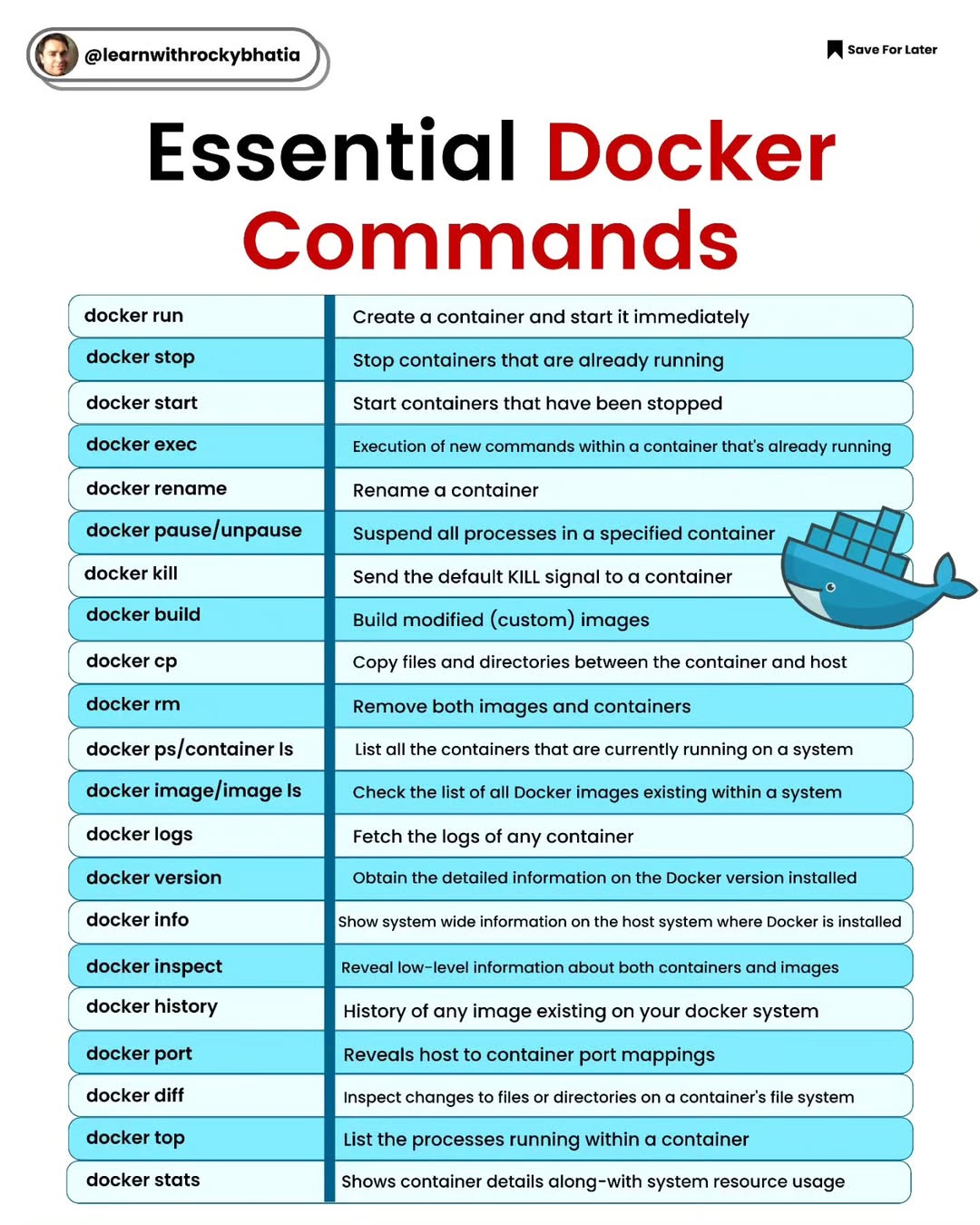
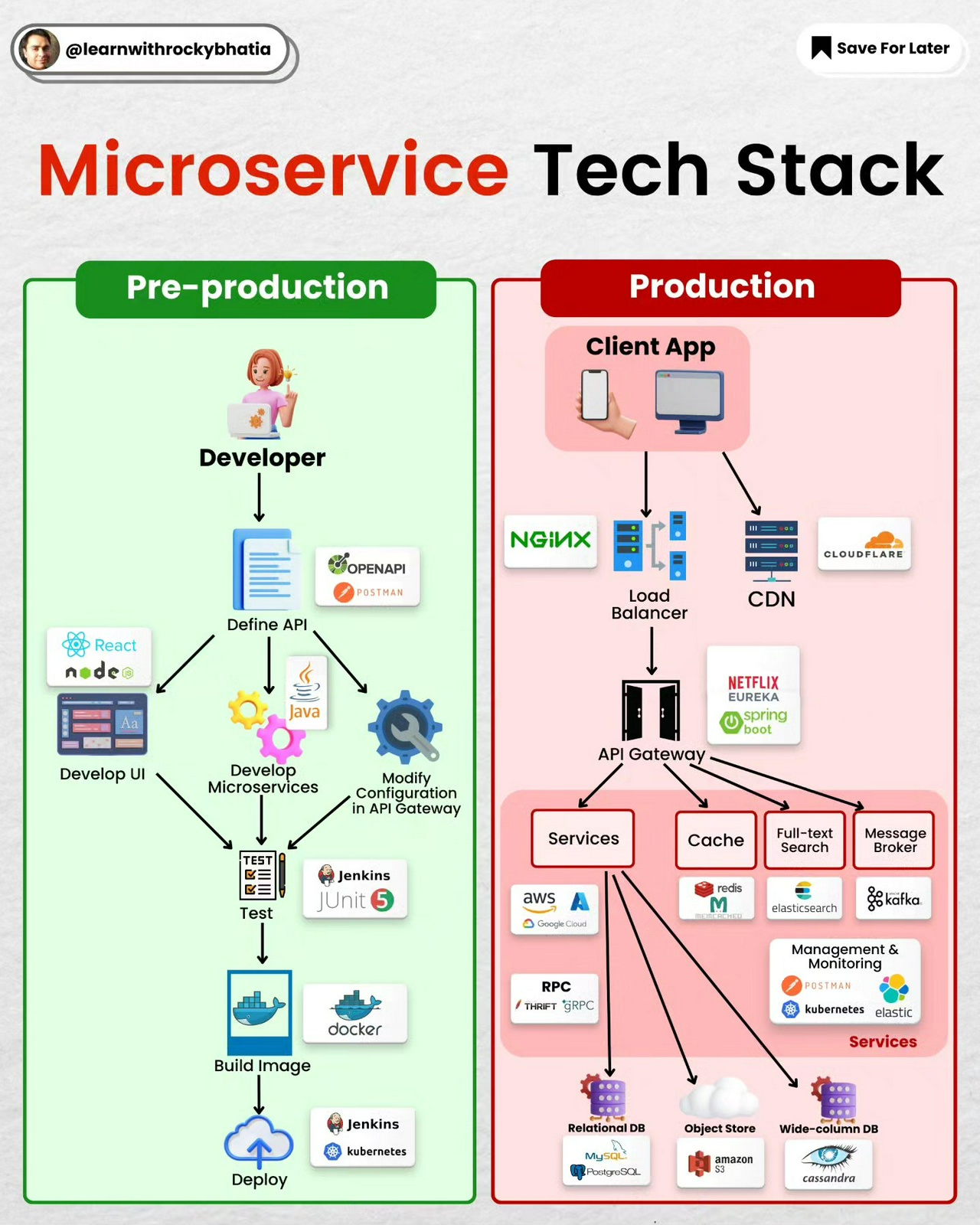
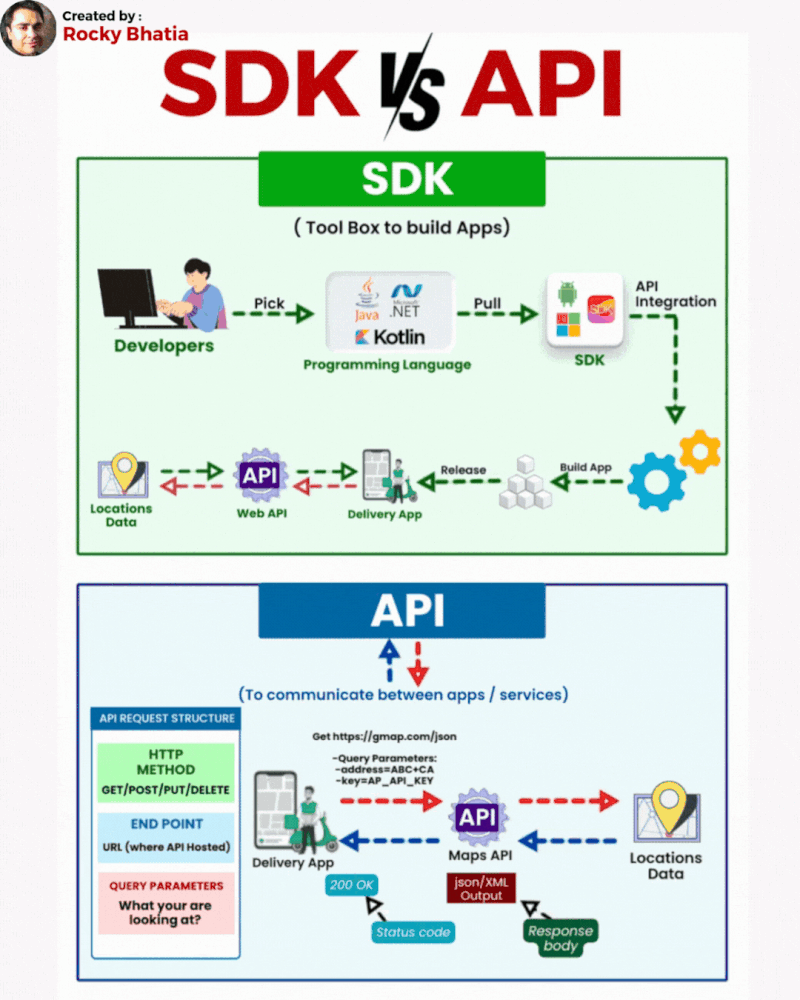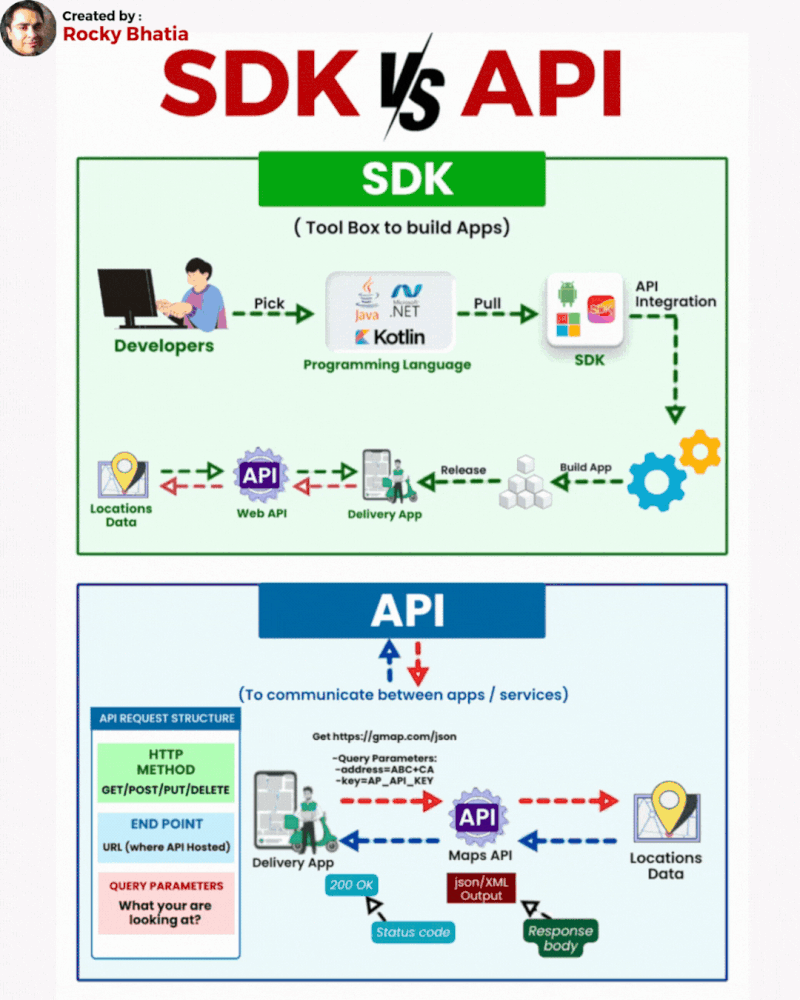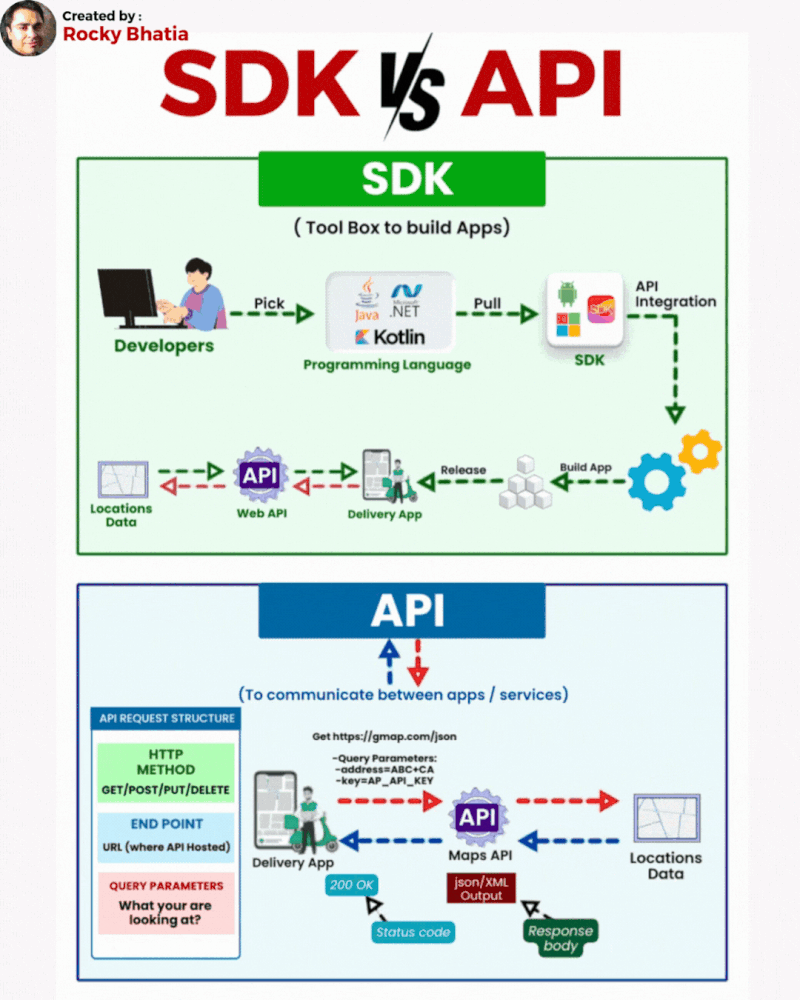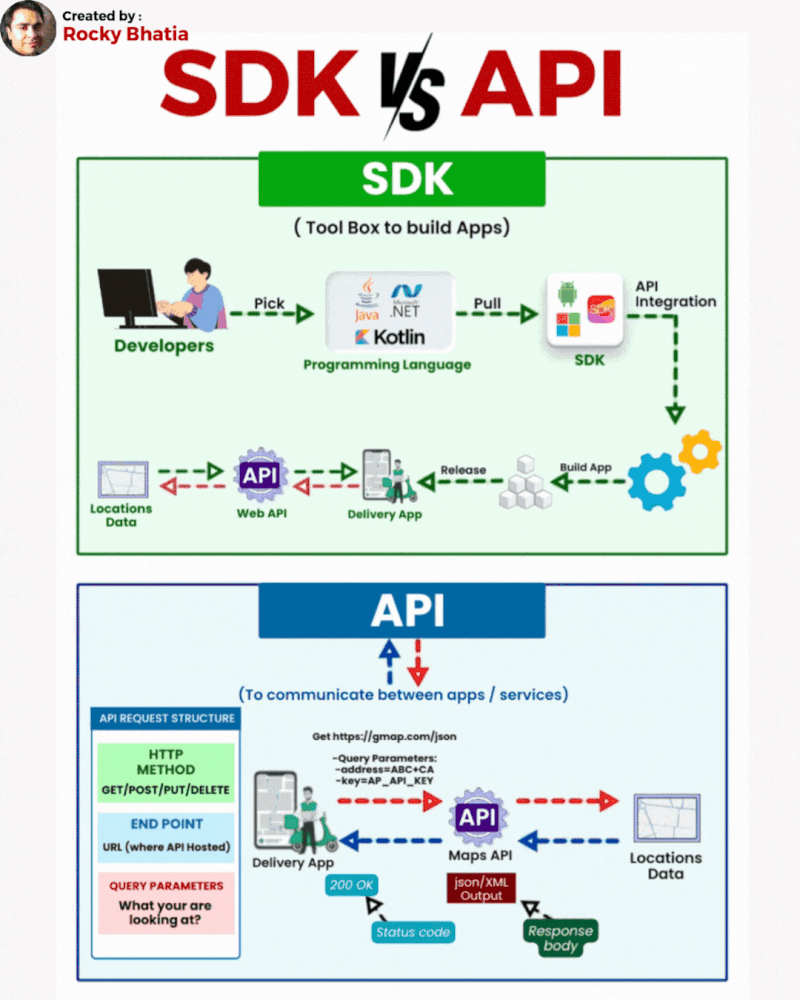
Database Sharding
Your database was fine – until it wasn't.
One day the queries slow down. Writes start backing up. The single node can't keep up anymore. And suddenly, sharding isn't optional.
But sharding done wrong is worse than not sharding at all 👇
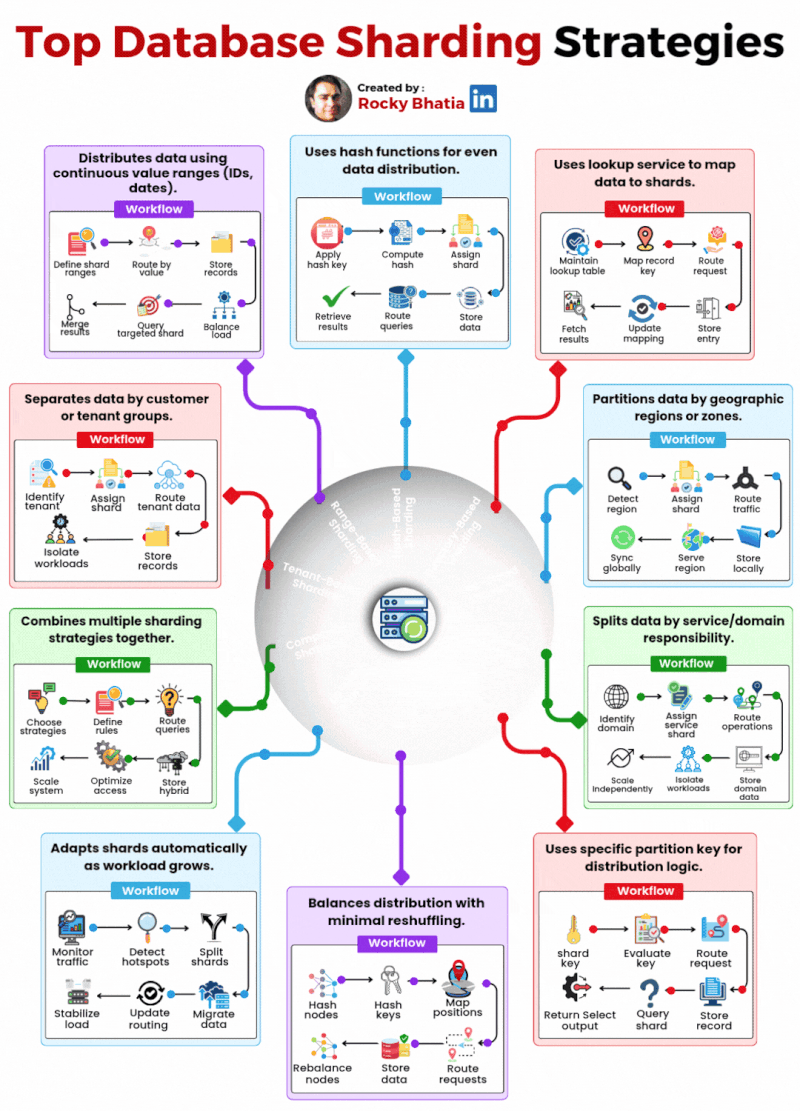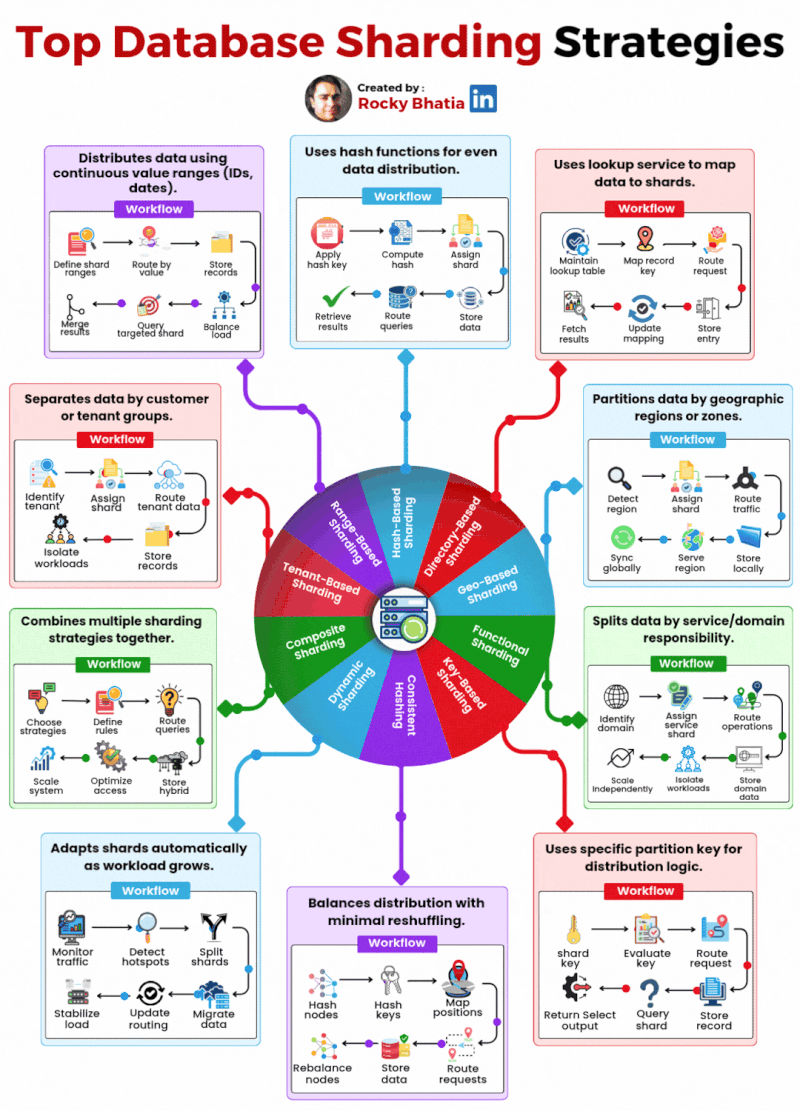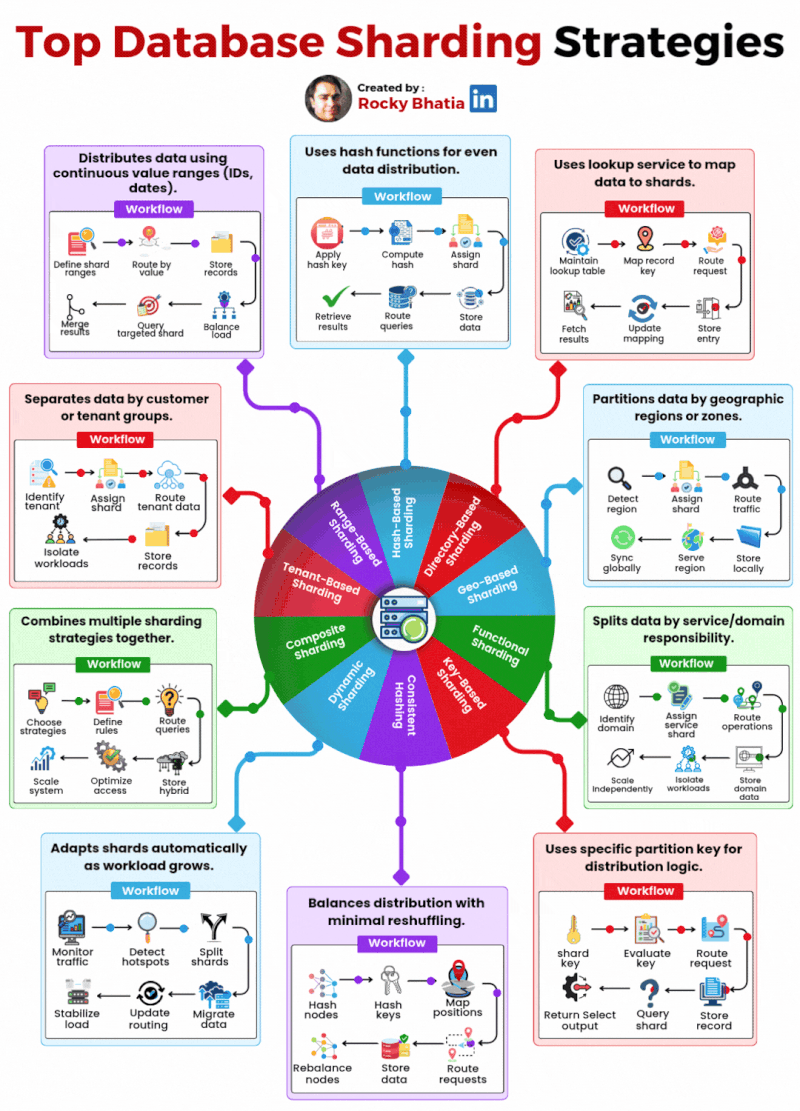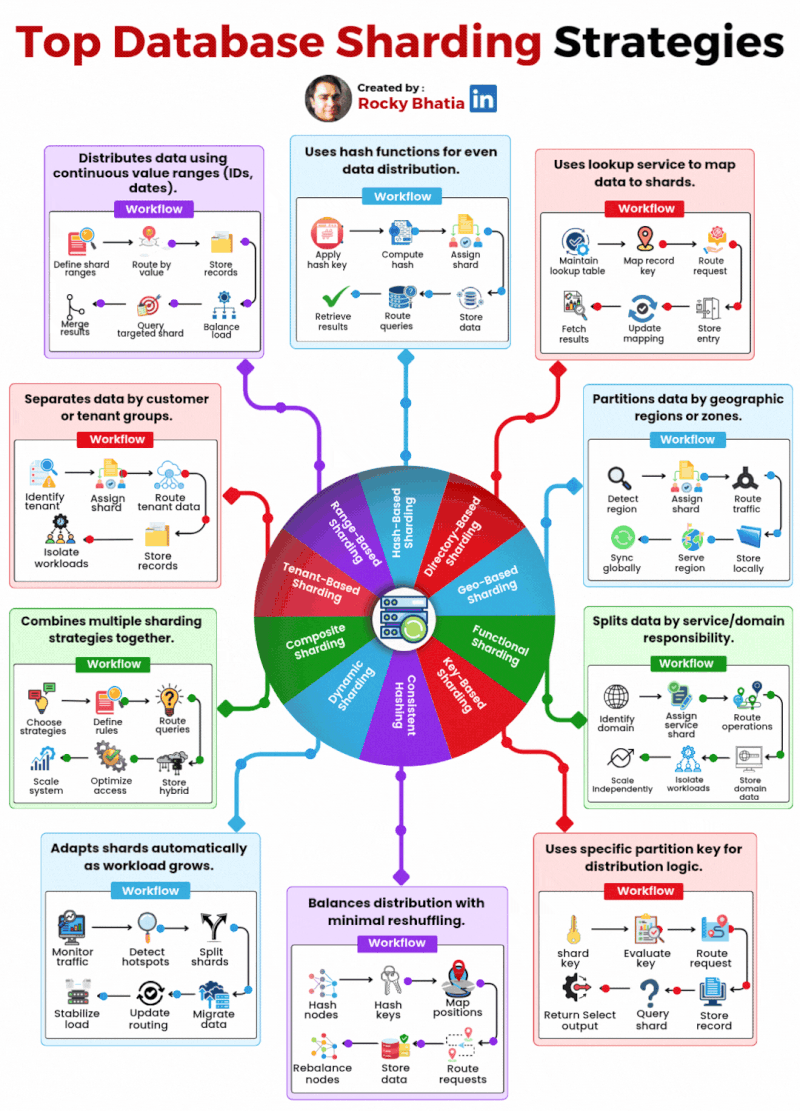
Here are the 10 database sharding strategies powering production systems today:
Range-Based – Distributes data using continuous value ranges like IDs or dates. Simple but can create hot spots.
Hash-Based – Uses hash functions for even data distribution across shards. Great balance, harder to range query.
Directory-Based – A lookup service maps data to shards. Flexible but adds a dependency.
Geo-Based – Partitions data by geographic region. Essential for latency-sensitive global systems.
Functional – Splits data by service or domain responsibility. Clean boundaries, scales independently.
Key-Based – Uses a specific partition key for distribution logic. Predictable and straightforward.
Consistent Hashing – Balances distribution with minimal reshuffling when nodes are added or removed.
Dynamic Sharding – Adapts shards automatically as workload grows. Operationally complex but powerful.
Composite – Combines multiple strategies together. Maximum flexibility, maximum complexity.
Tenant-Based – Separates data by customer or tenant. Perfect for multi-tenant SaaS architectures.
The rule most engineers learn too late: There's no universally correct sharding strategy. The right one depends on your query patterns, scale requirements, and team's operational maturity.
Start with the simplest approach that solves your problem.
Optimize when the bottleneck proves it.