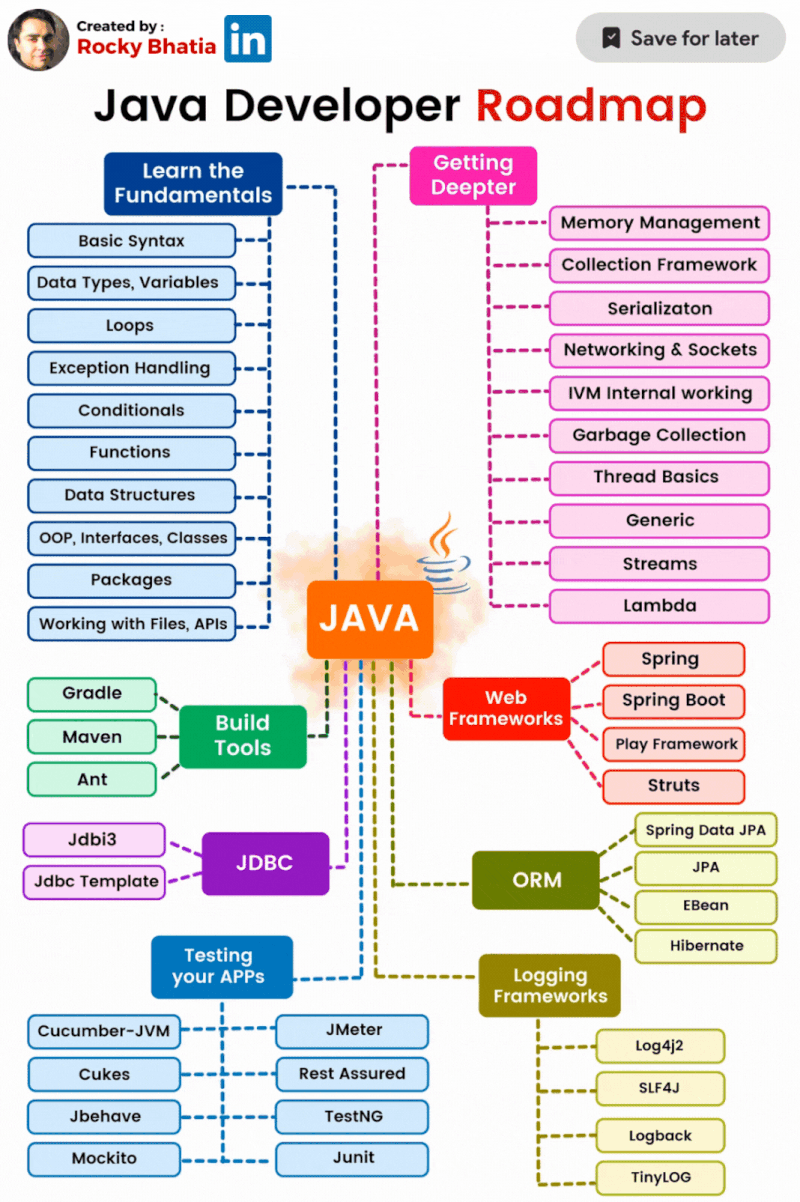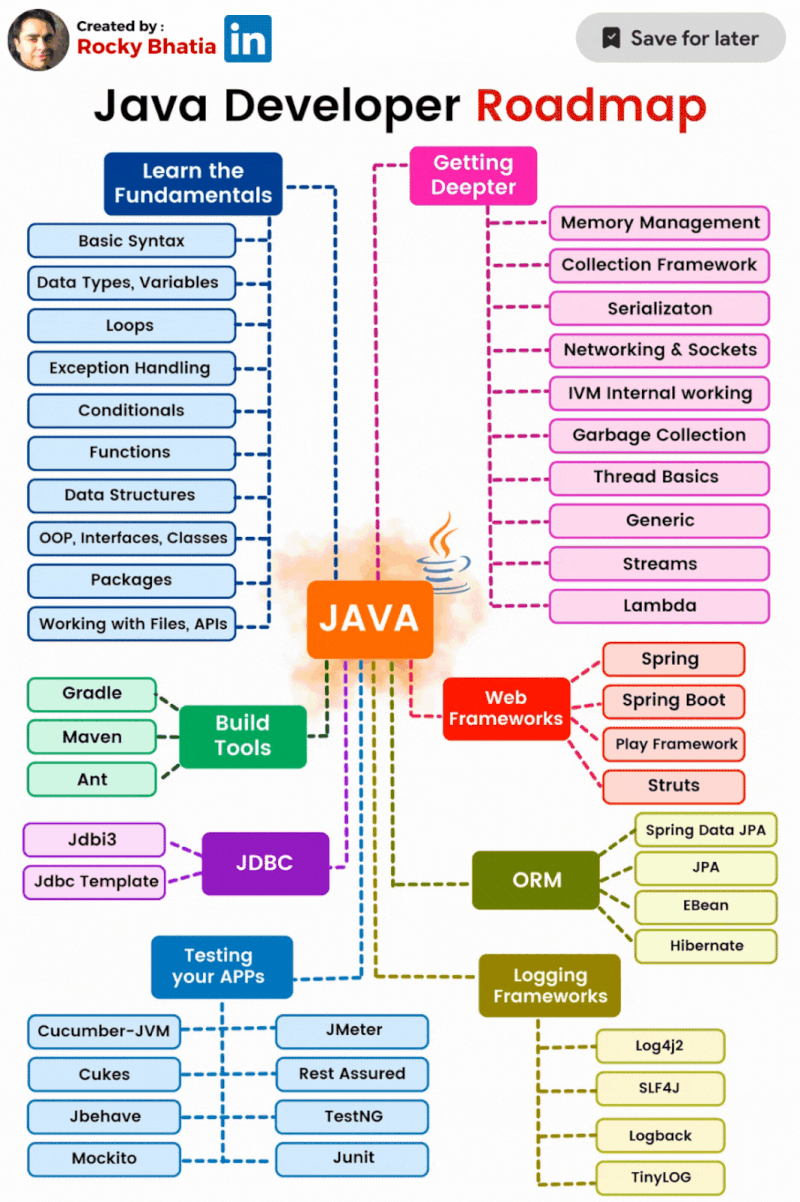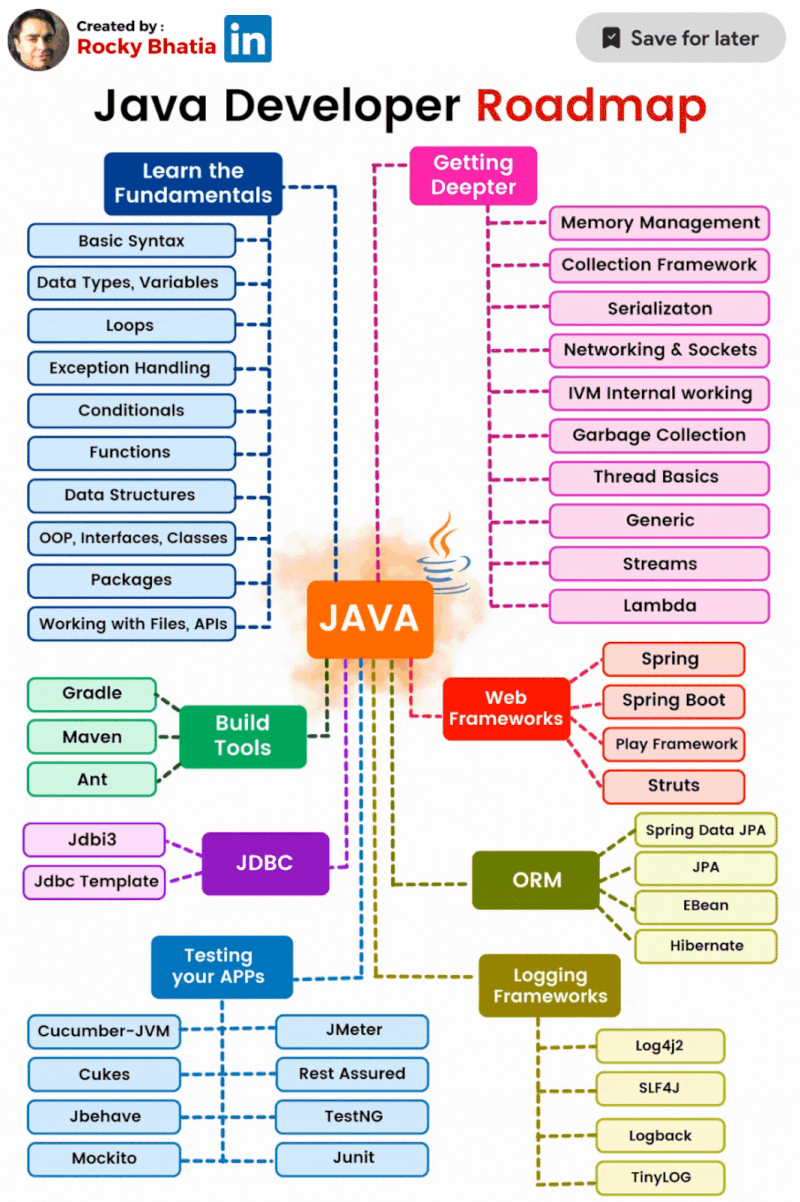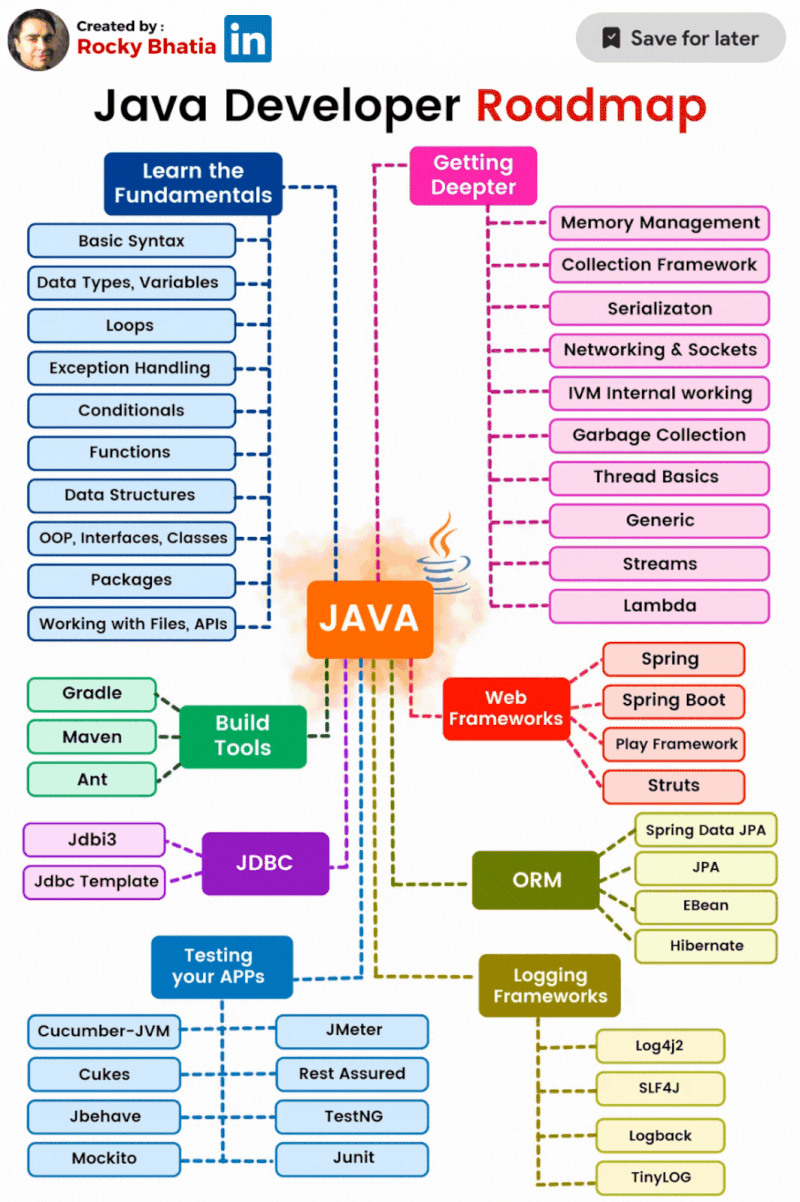
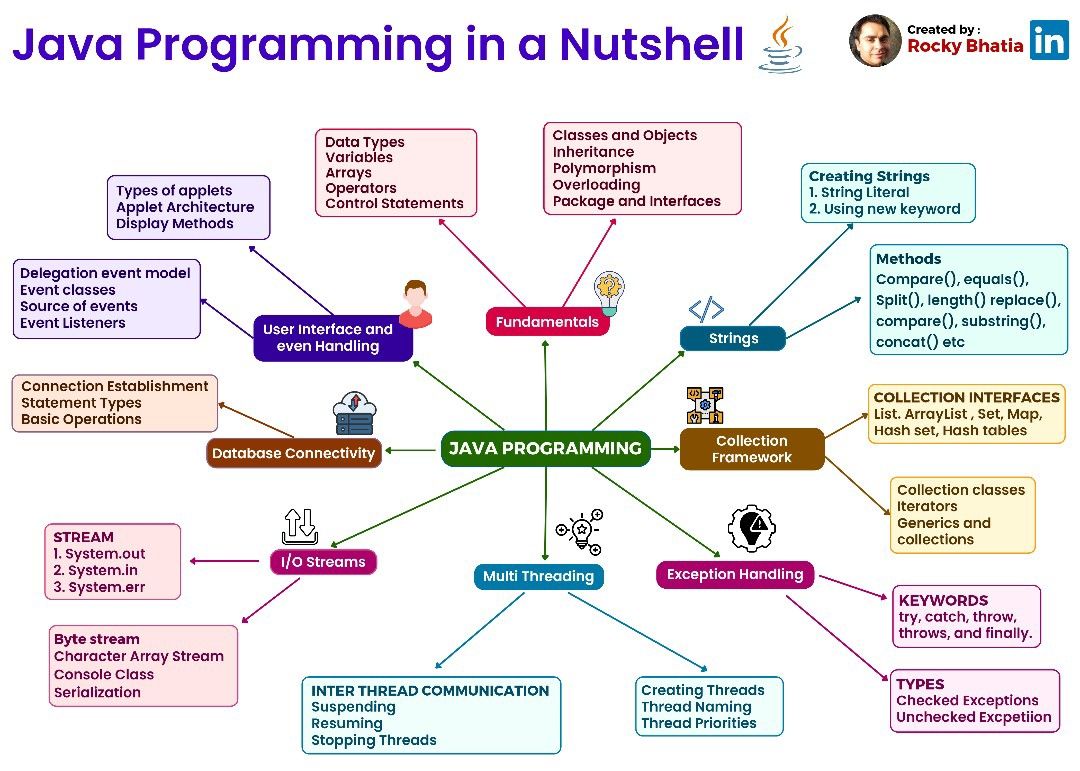
Java Programming in a Nutshell
#java #javaprogramming #javaprogramminginanutshell
1. Syntax and Data Types: – Basic syntax and structure of Java programs. – Primitive data types (int, float, boolean, etc.) and their usage. – Object-oriented programming (classes, objects, inheritance, polymorphism, etc.). – Control flow statements (if-else, loops, switch, etc.).
2. Java Libraries and APIs: – Java Standard Library: Provides a wide range of classes and methods for common programming tasks, such as handling strings, input/output operations, collections, concurrency, and networking. – Java Development Kit (JDK): Includes tools for developing, debugging, and running Java applications, such as the Java Compiler (javac), Java Virtual Machine (JVM), and Java Runtime Environment (JRE). – Java Application Programming Interface (API): A collection of pre-written classes and interfaces that developers can use to build applications.
3. Exception Handling: – Handling and managing errors and exceptions that may occur during program execution. – Using try-catch blocks to catch and handle exceptions gracefully. – Throwing and creating custom exceptions.
4. Input/Output (I/O): – Reading and writing data from/to different sources (files, streams, etc.). – Working with input and output streams, readers, and writers. – Serialization and deserialization of objects.
5. Multithreading and Concurrency: – Creating and managing multiple threads to achieve concurrent execution. – Synchronization and thread safety. – Inter-thread communication and synchronization mechanisms.
6. Collections Framework: – Built-in data structures (lists, sets, maps, queues, etc.) and algorithms for manipulating and storing collections of objects. – Iterating over collections and performing operations like sorting, searching, and filtering.
7. Java Database Connectivity (JDBC): – Connecting to databases and executing SQL queries. – Retrieving, updating, and manipulating data in relational databases.
Core Java serves as the foundation for Java development, providing the necessary tools and concepts to create robust,platform-independent applications across various domains, including web development, enterprise systems, mobile apps, and more.