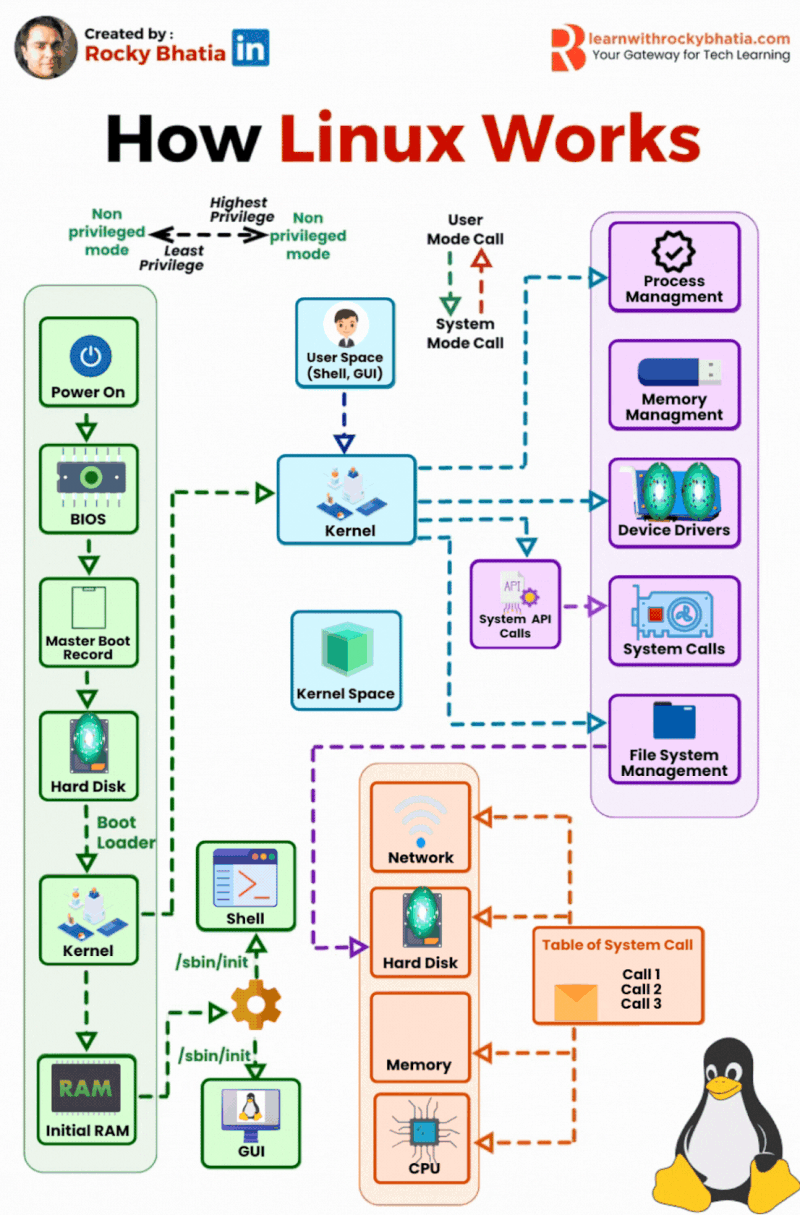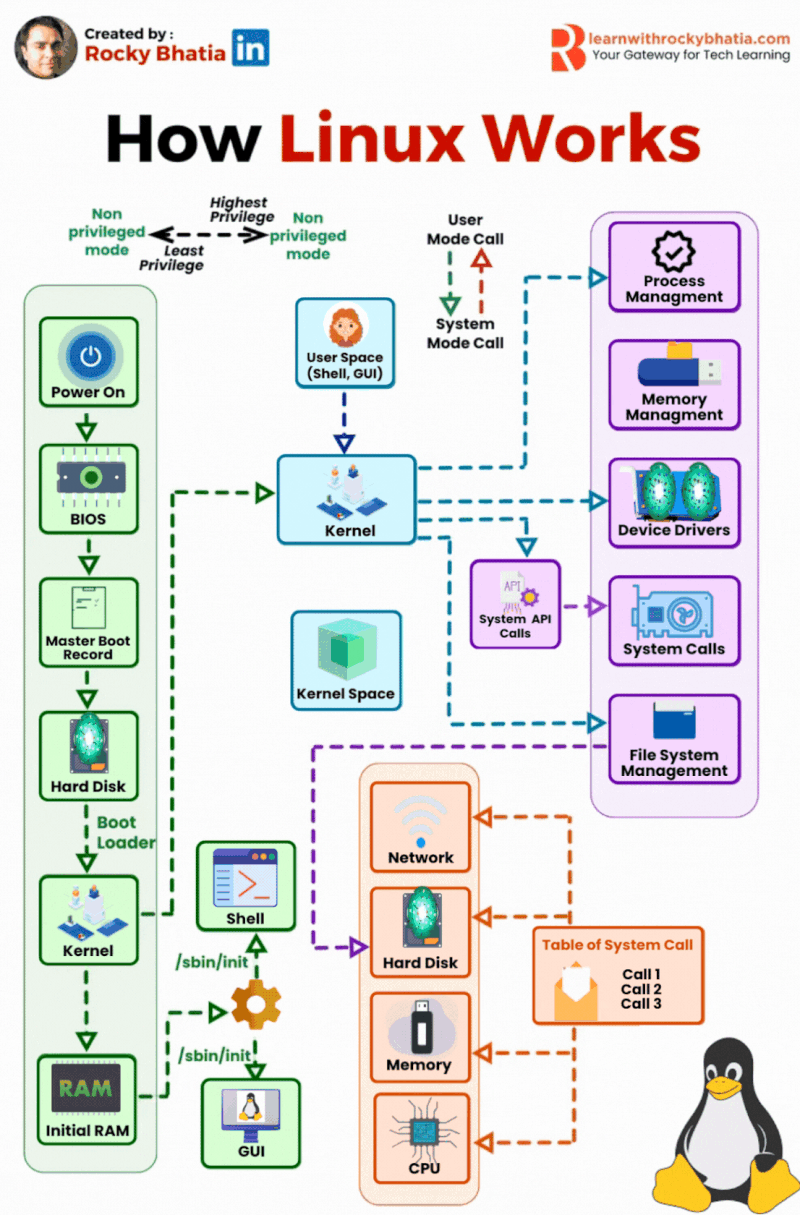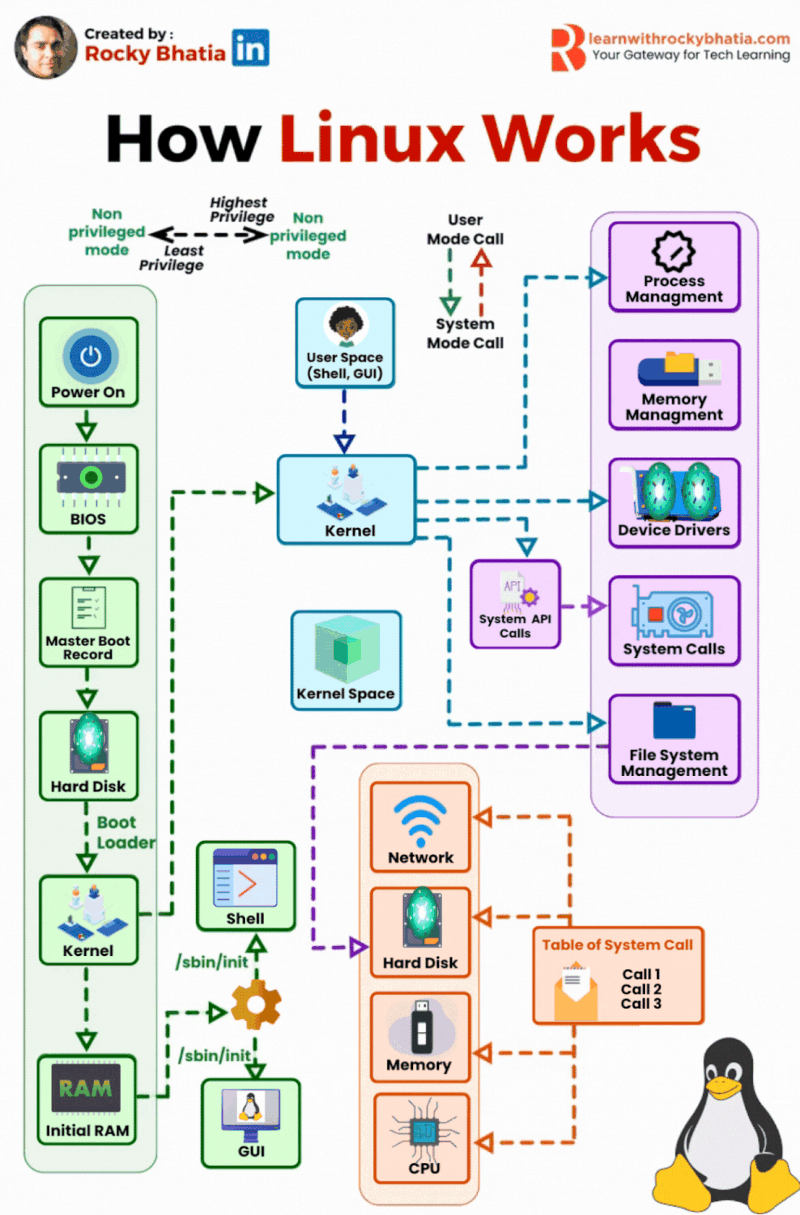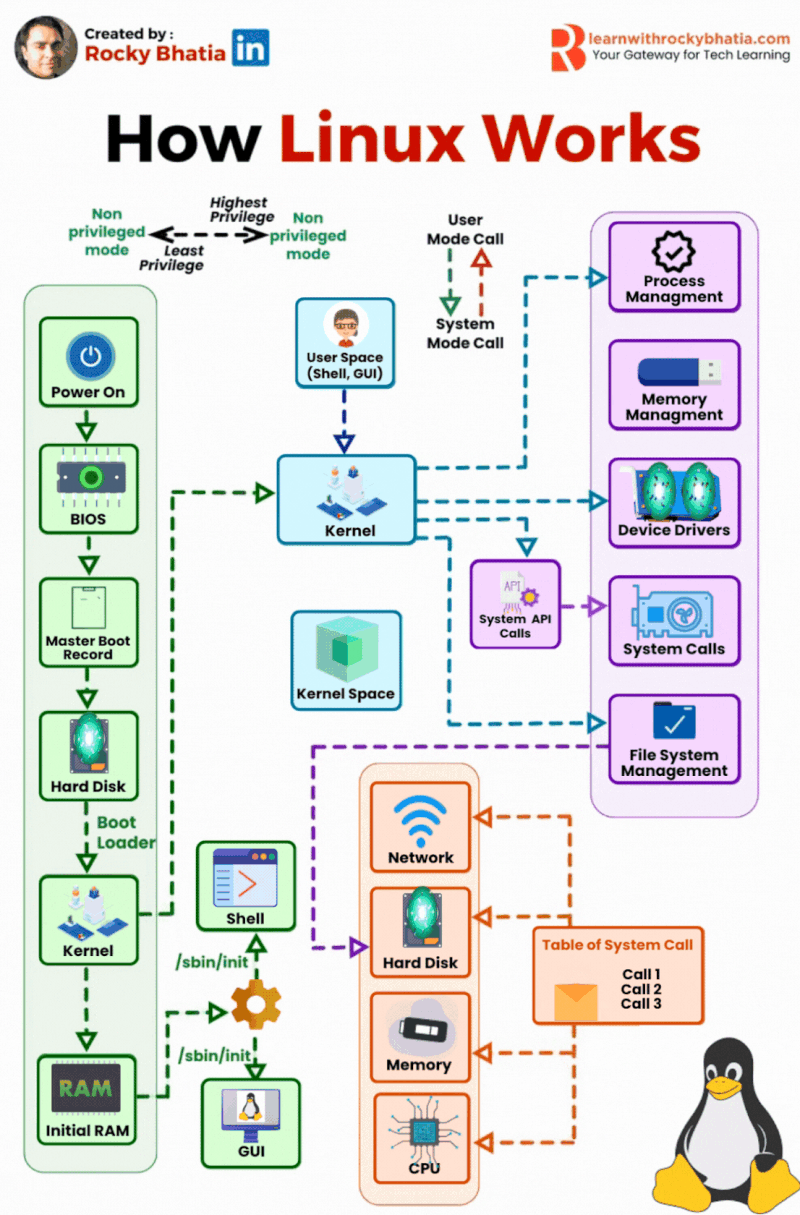
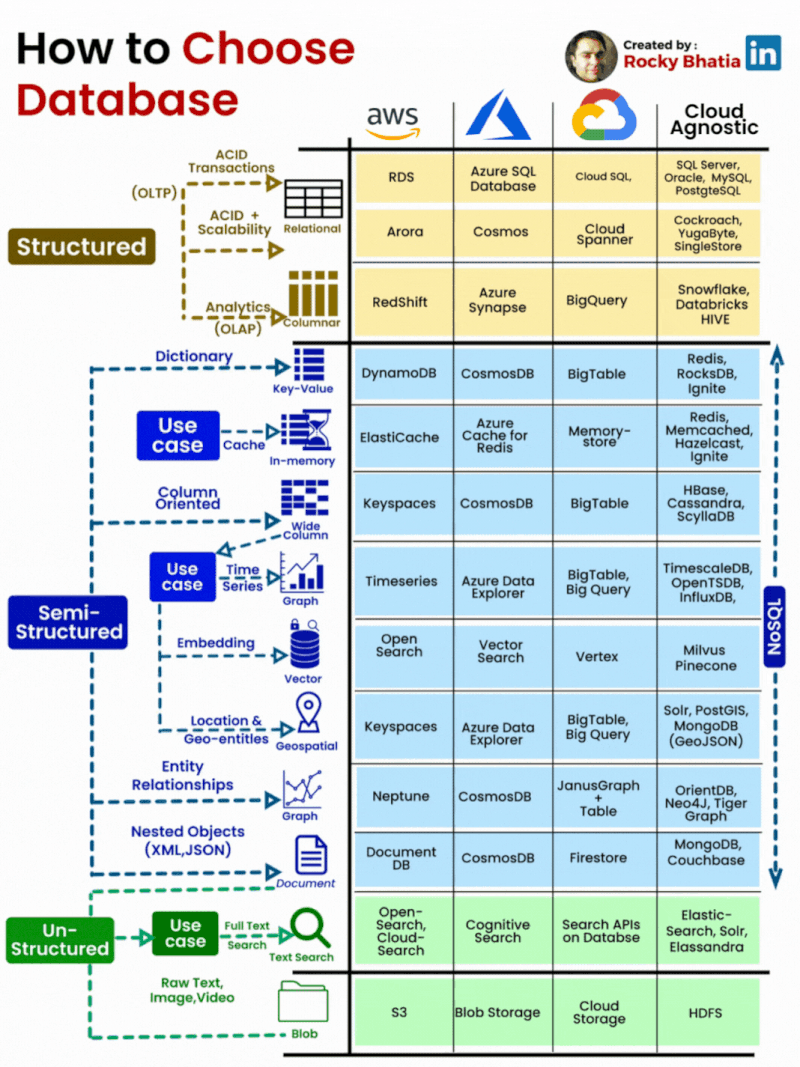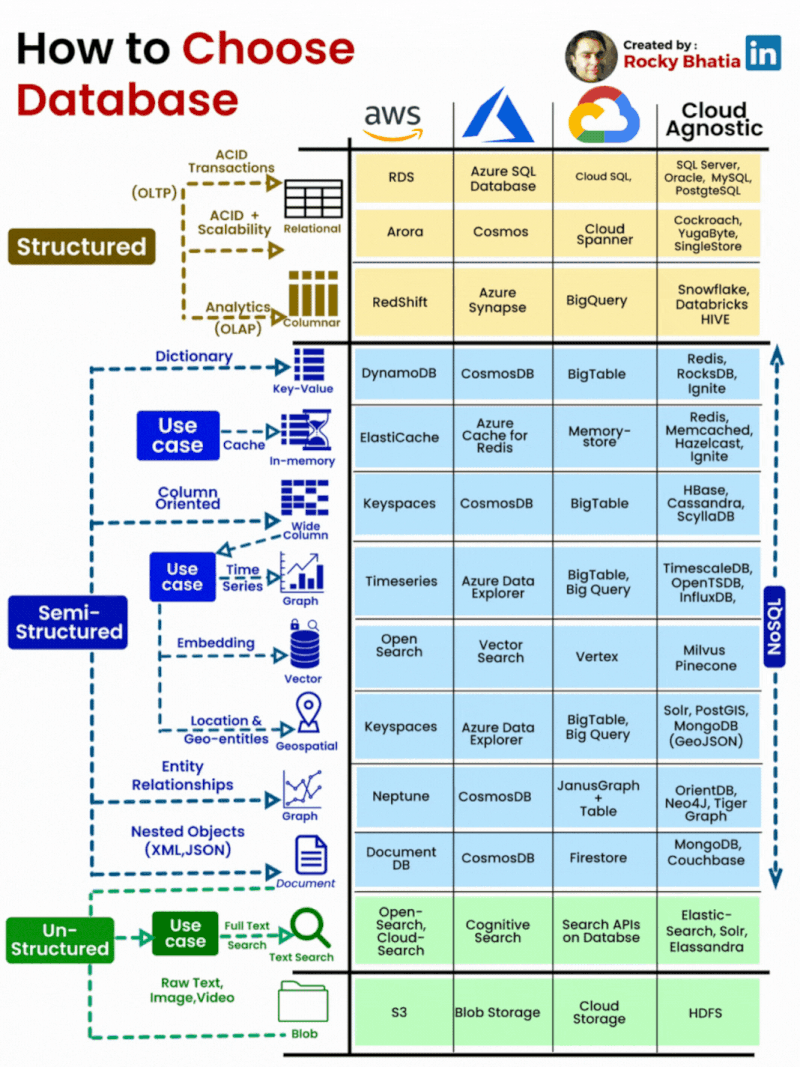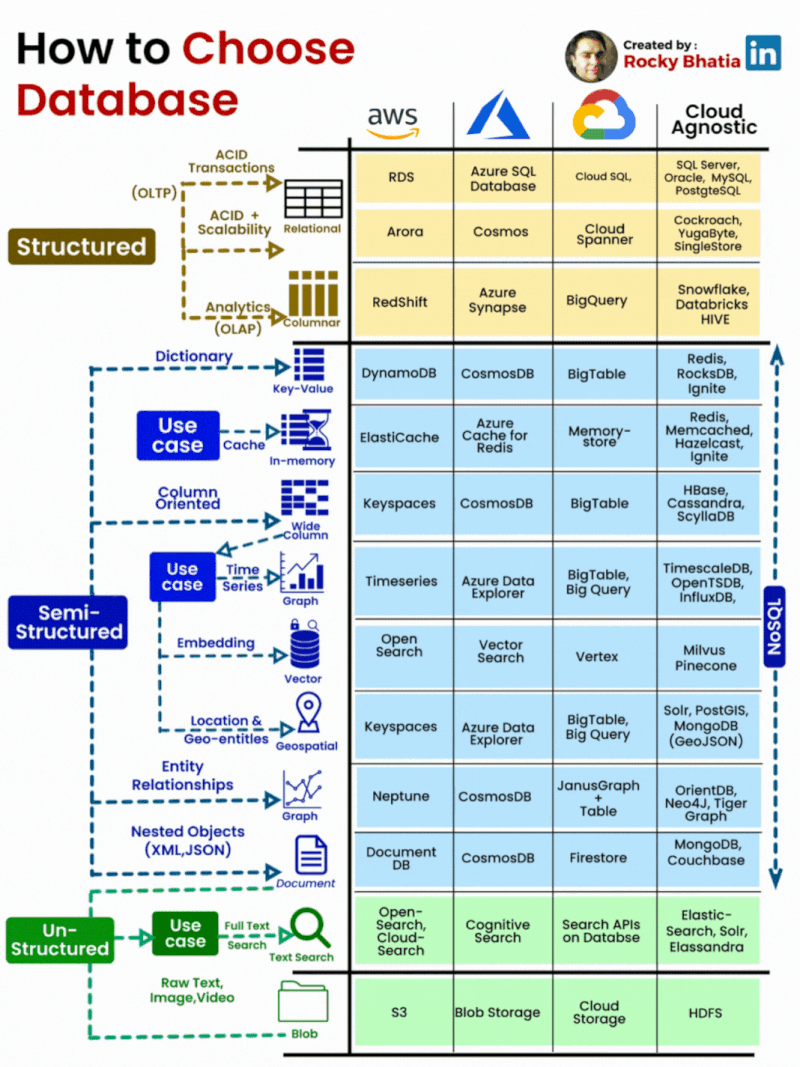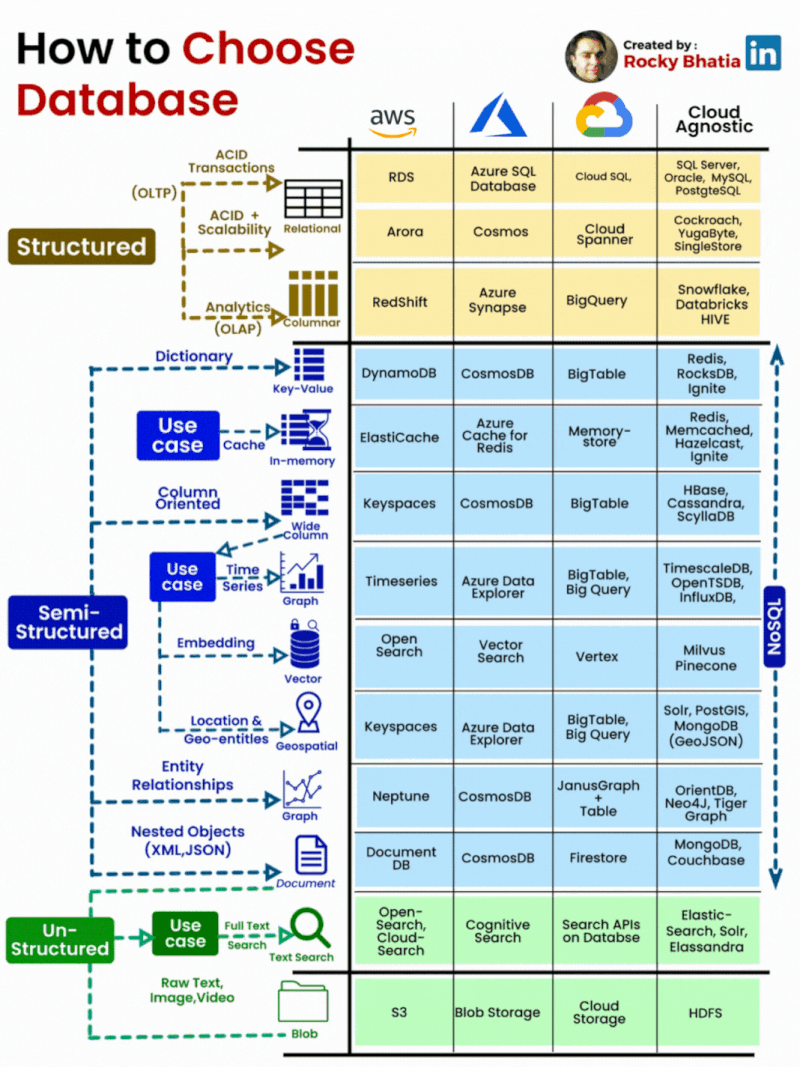
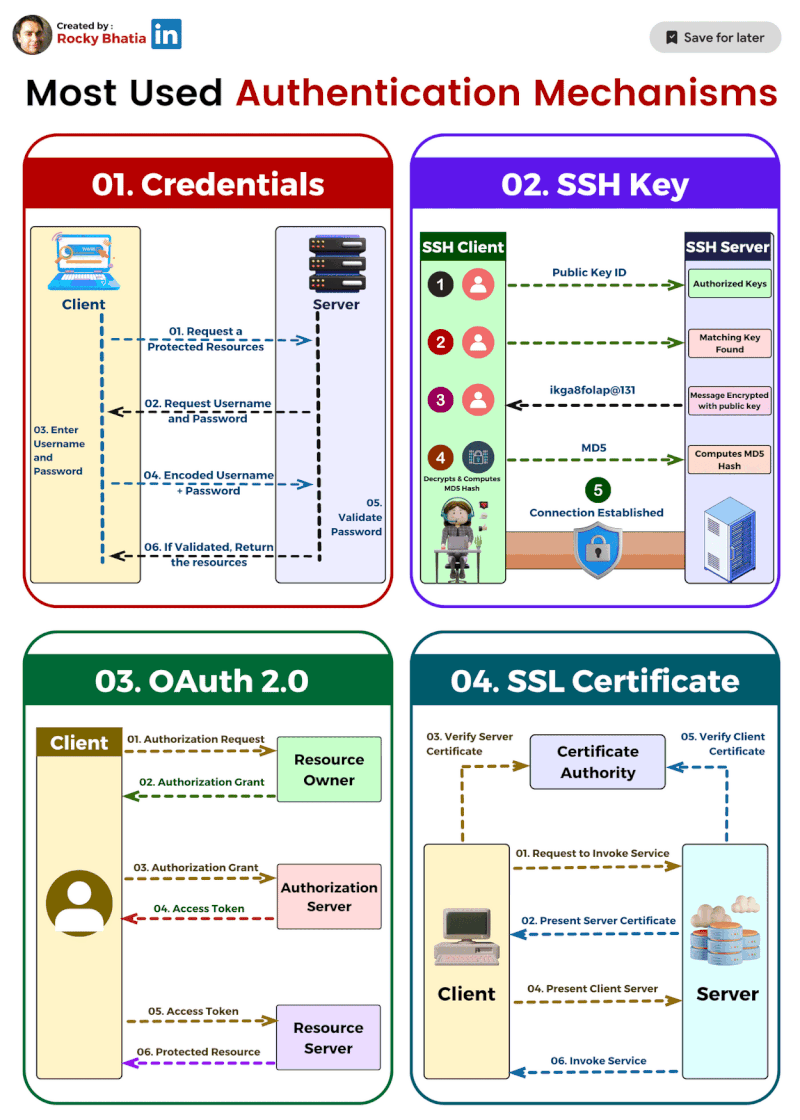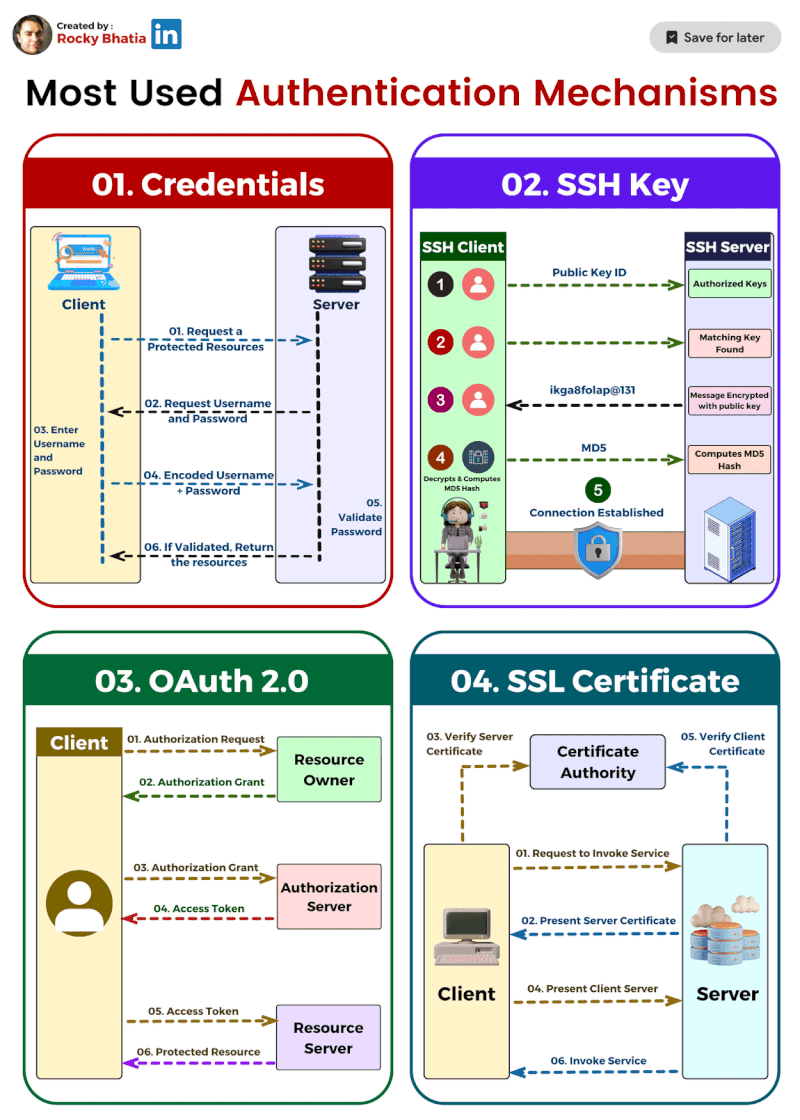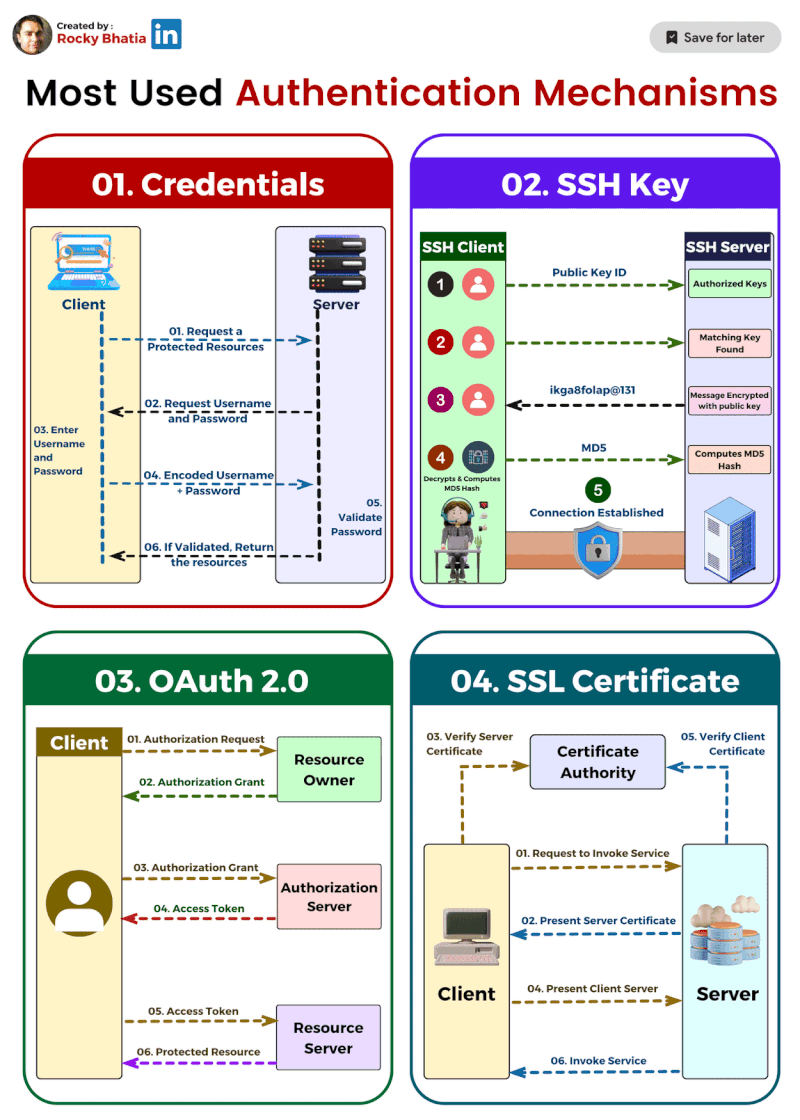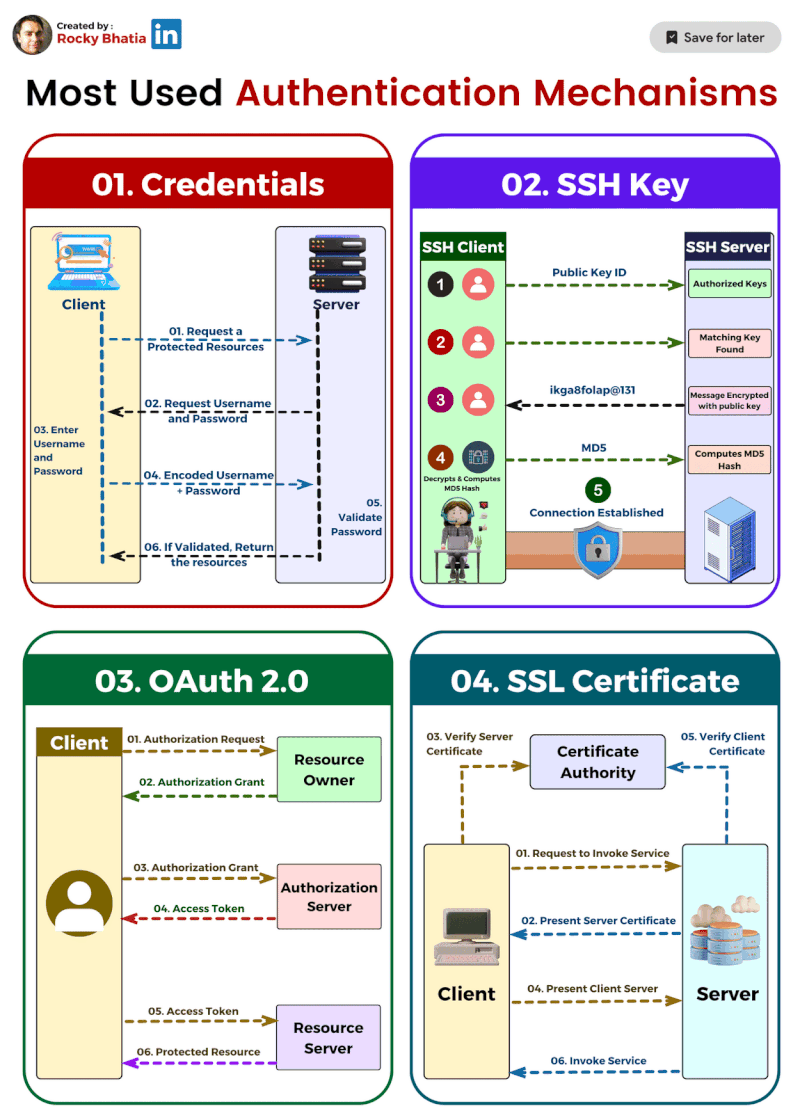
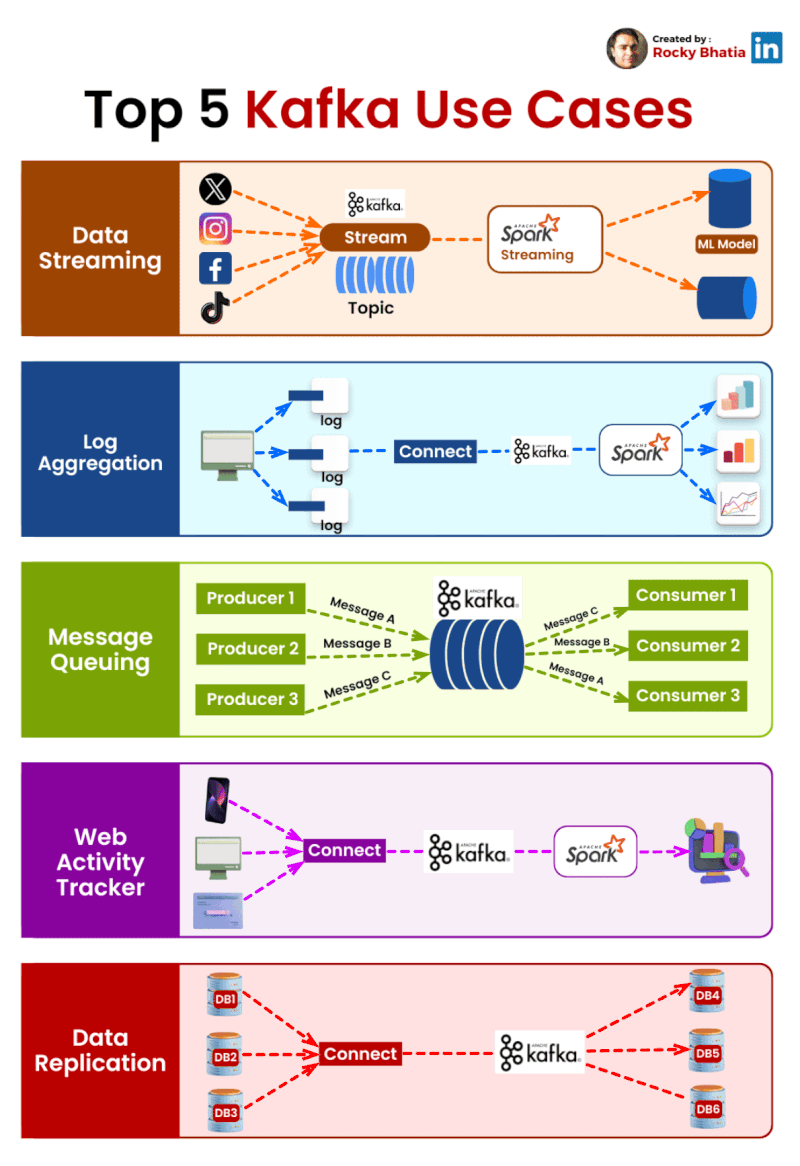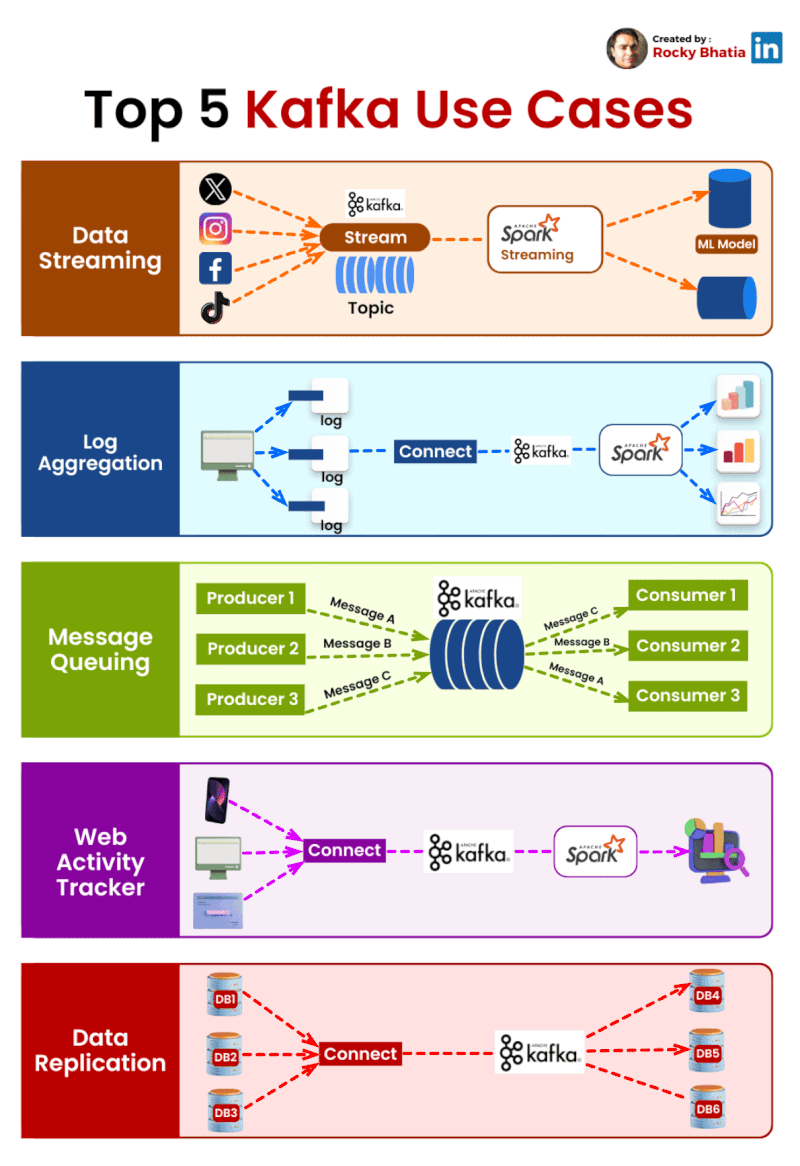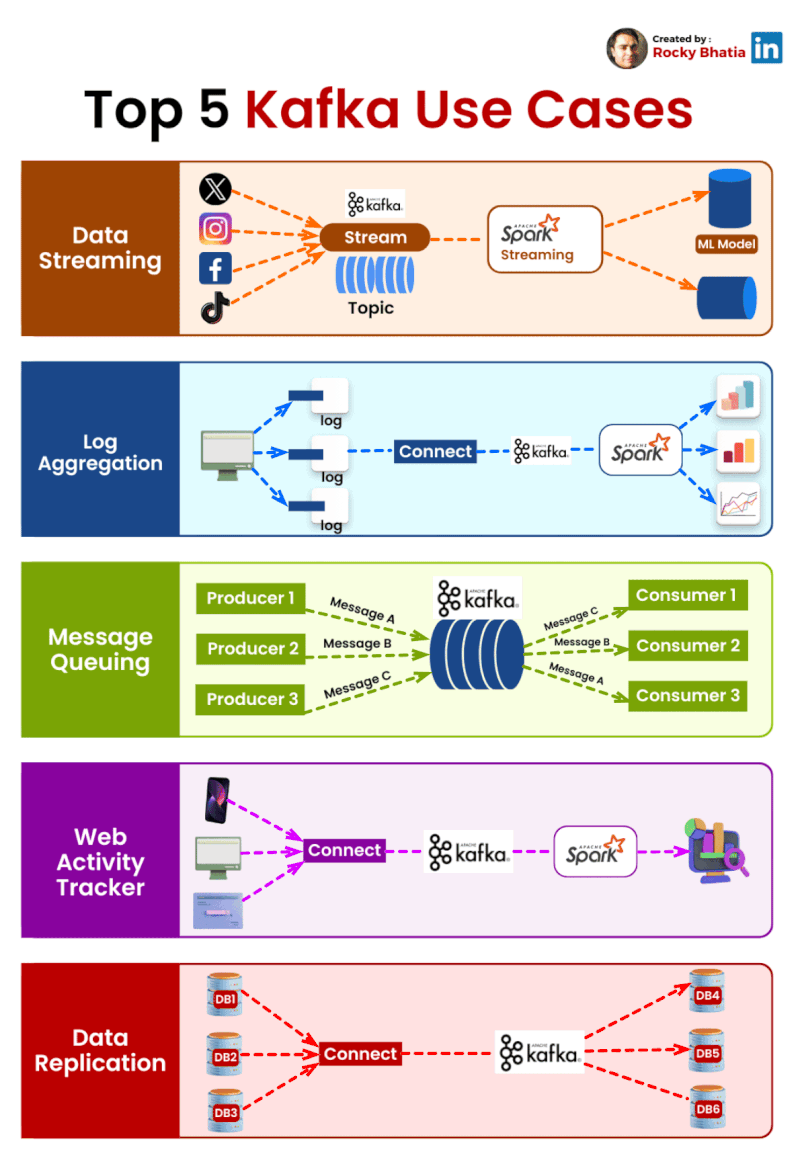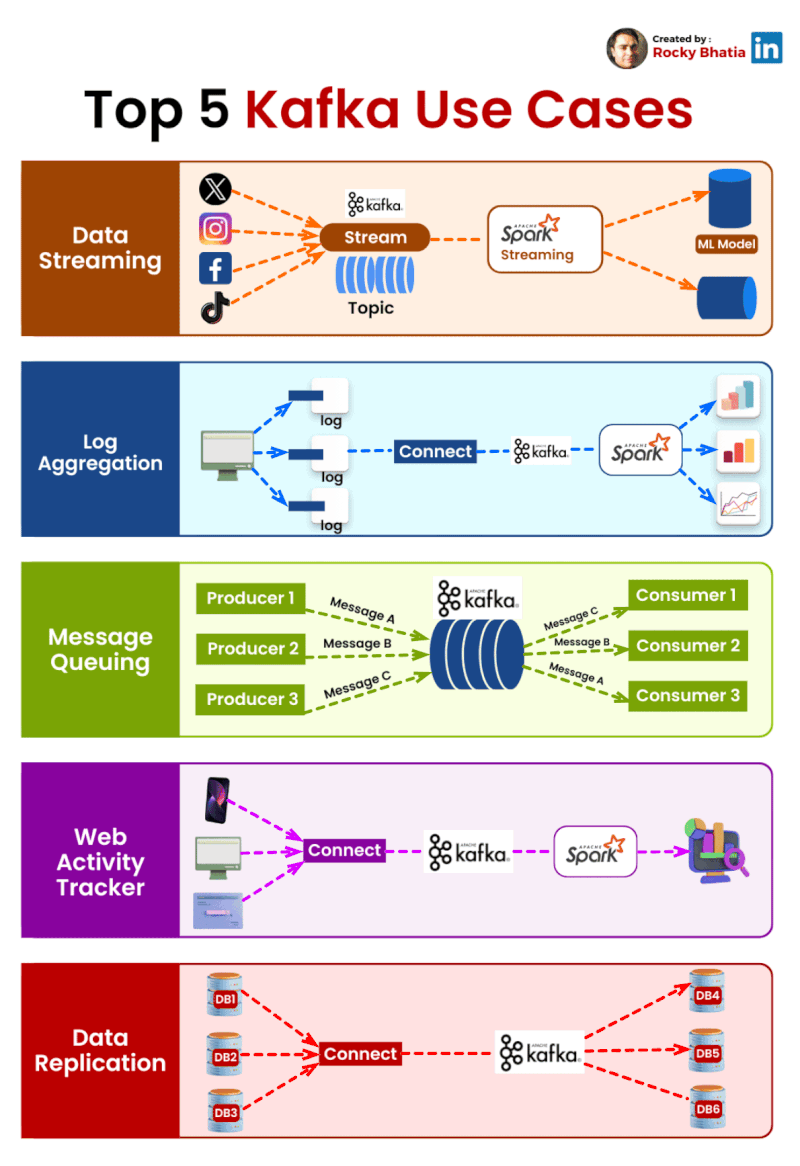
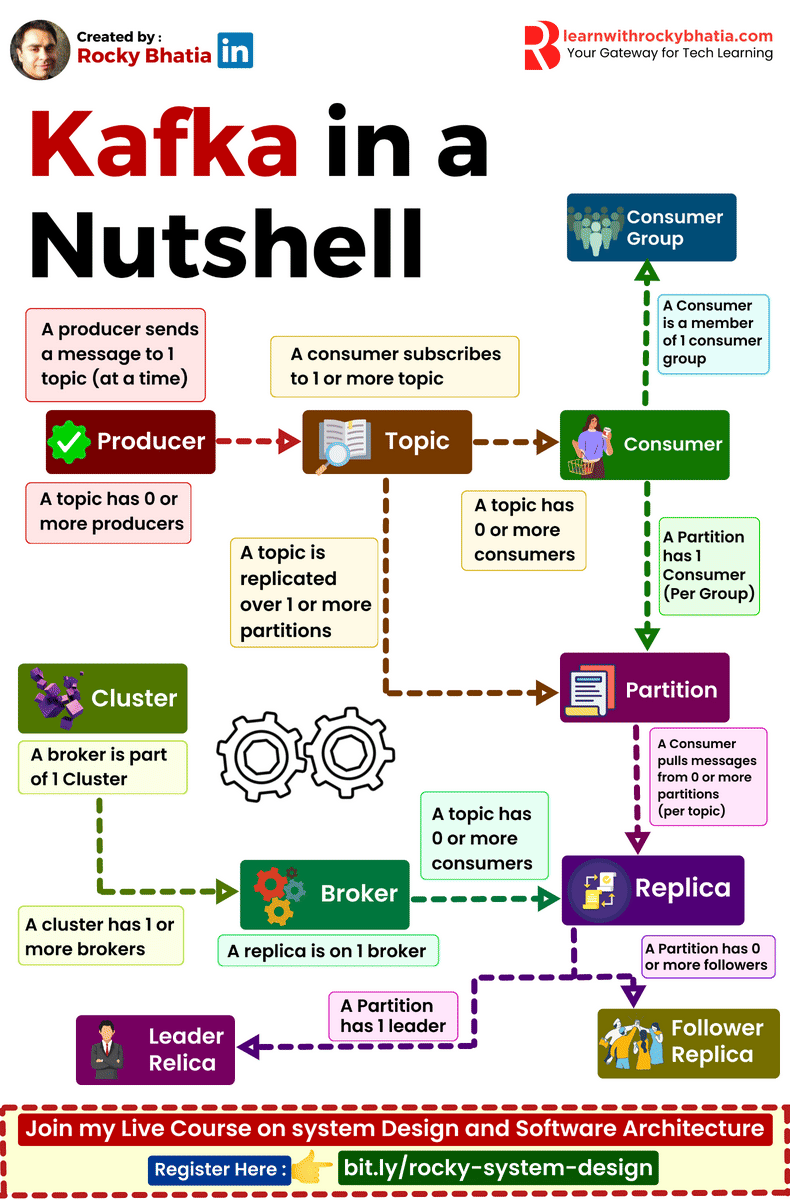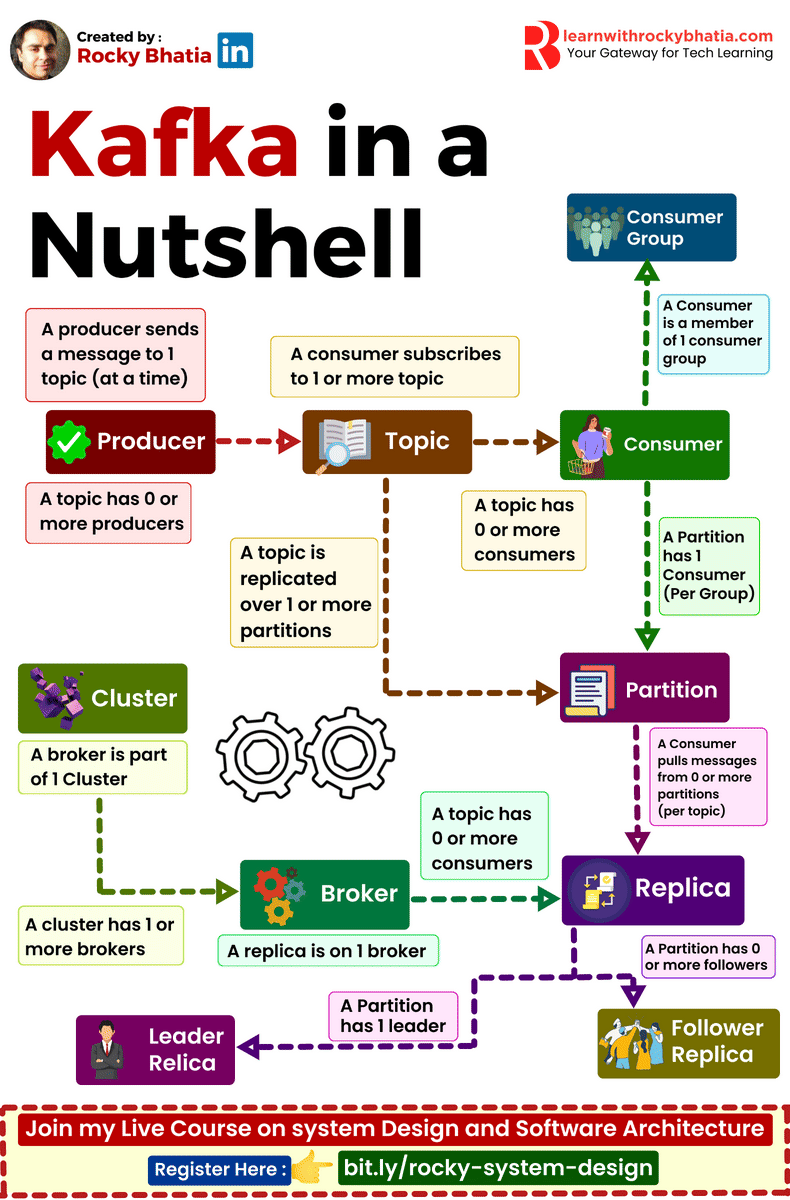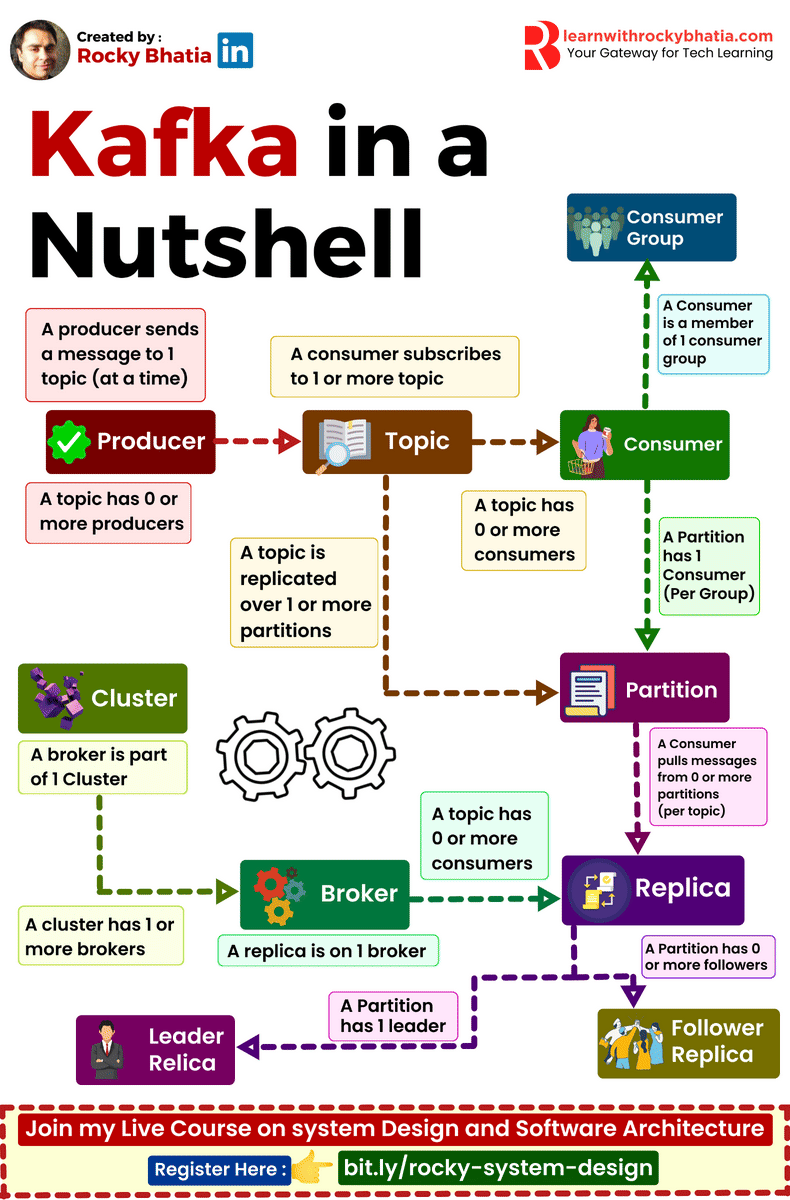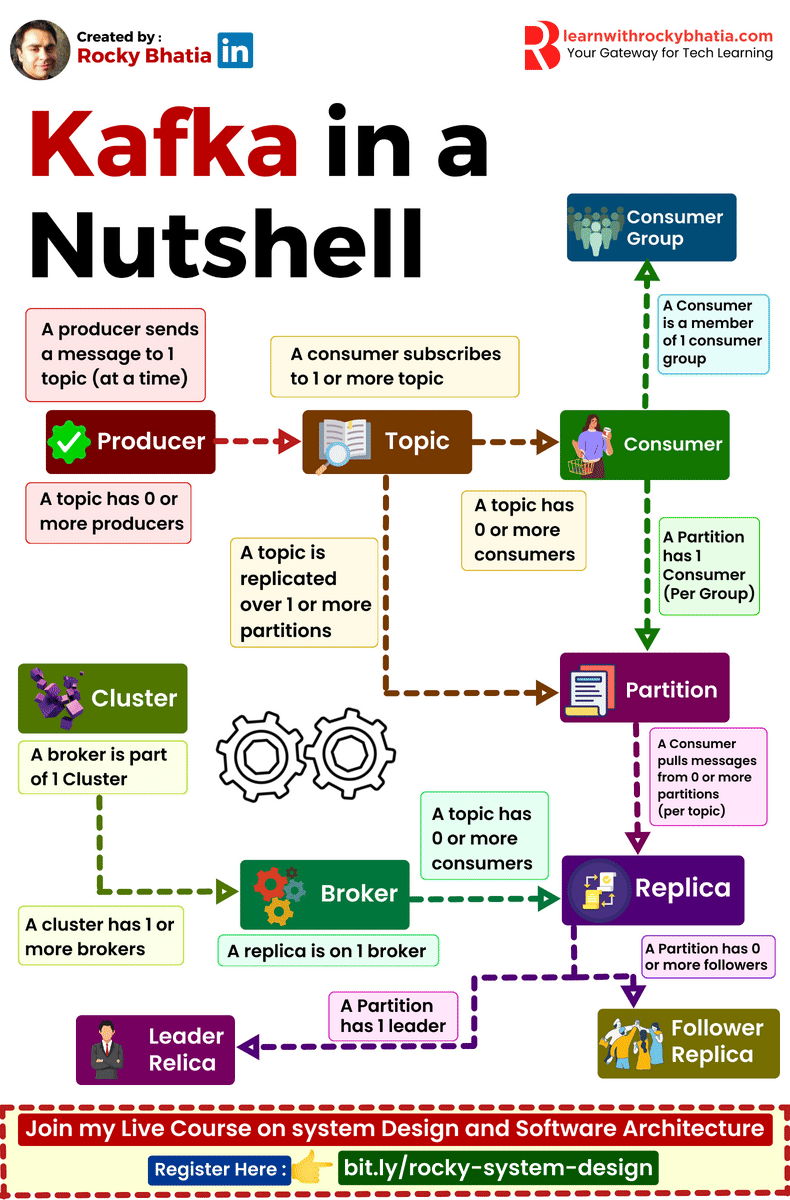
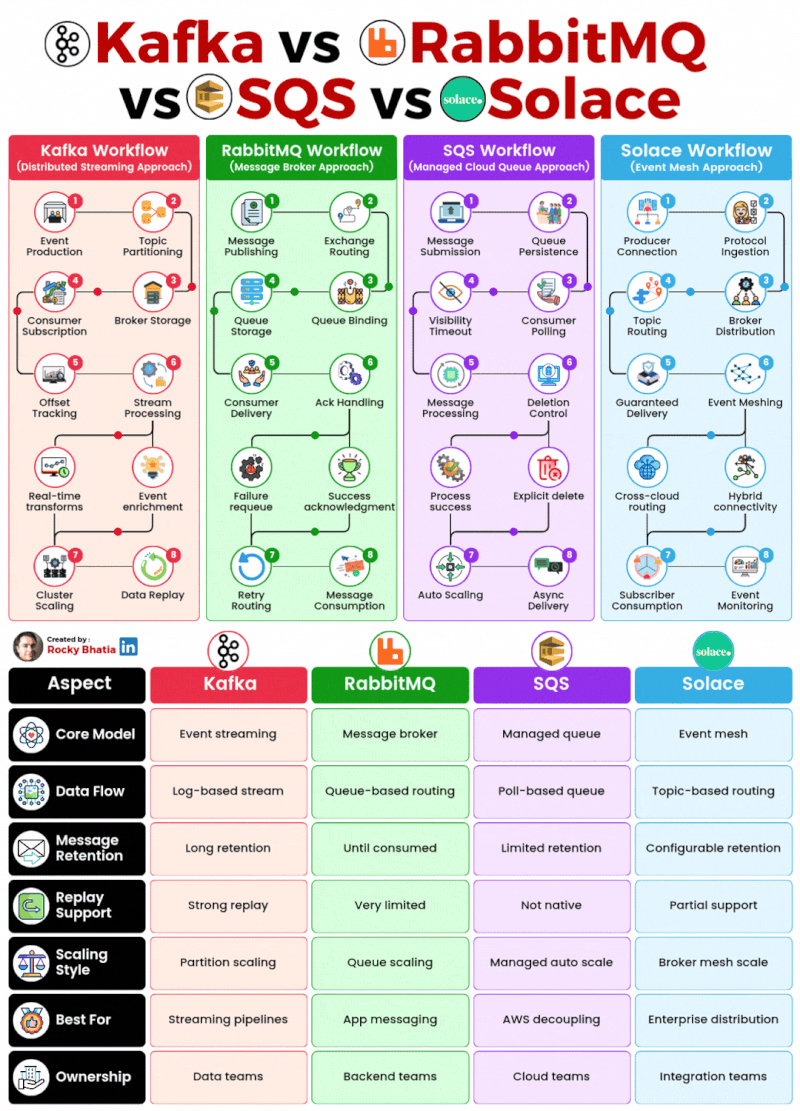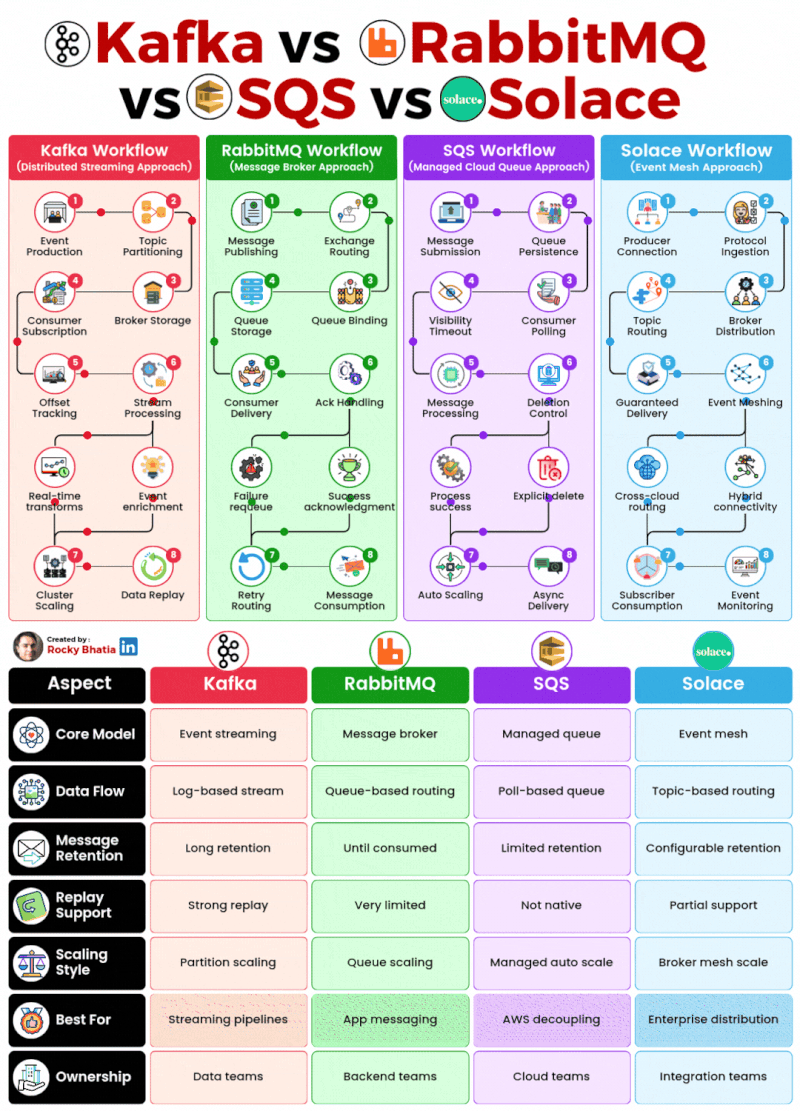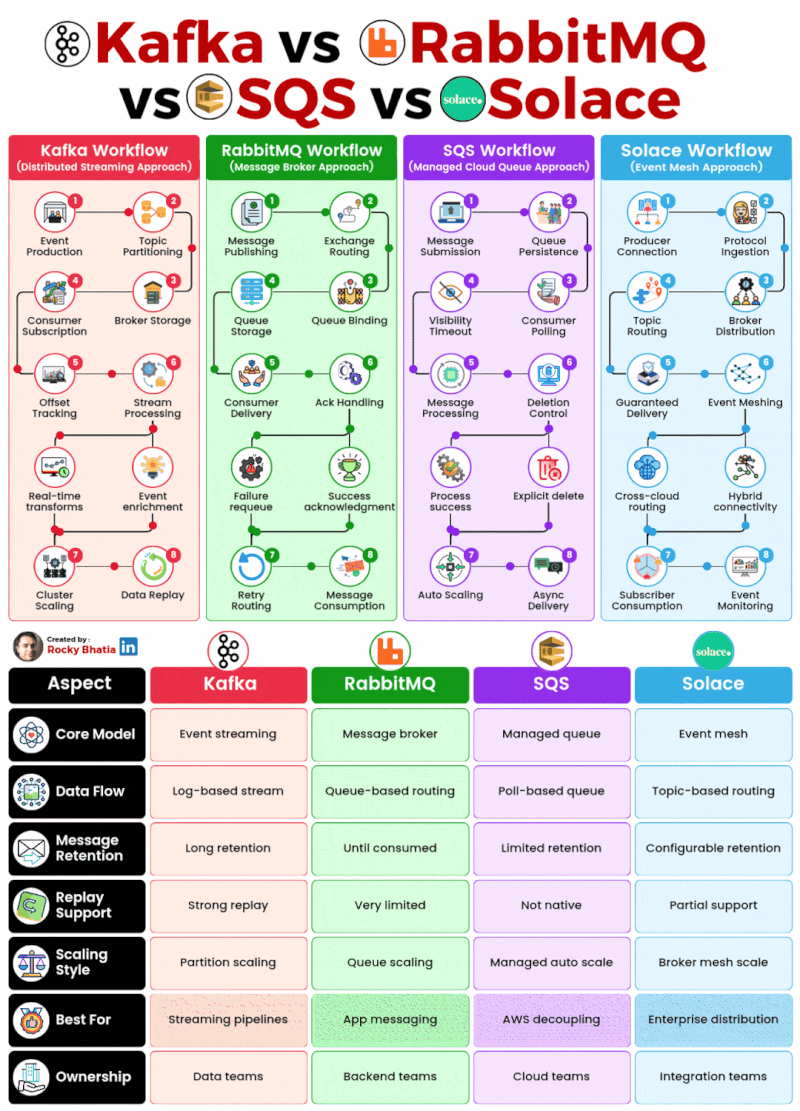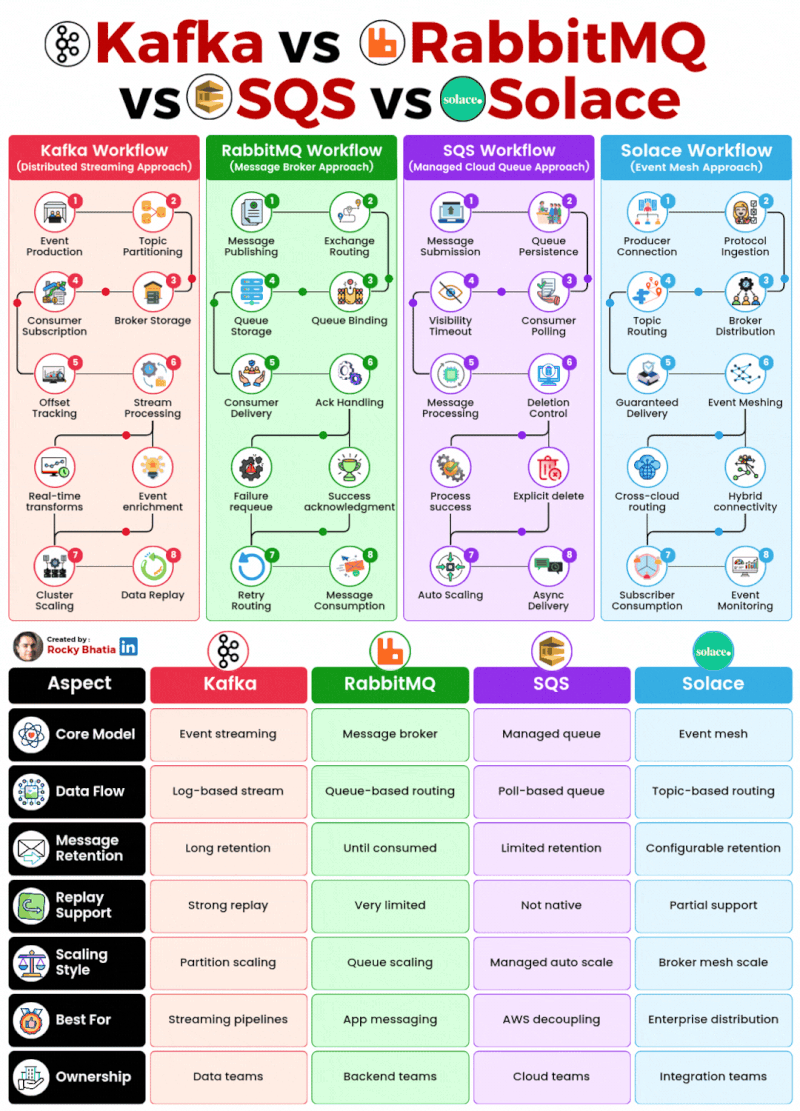
PostgreSQL Uses
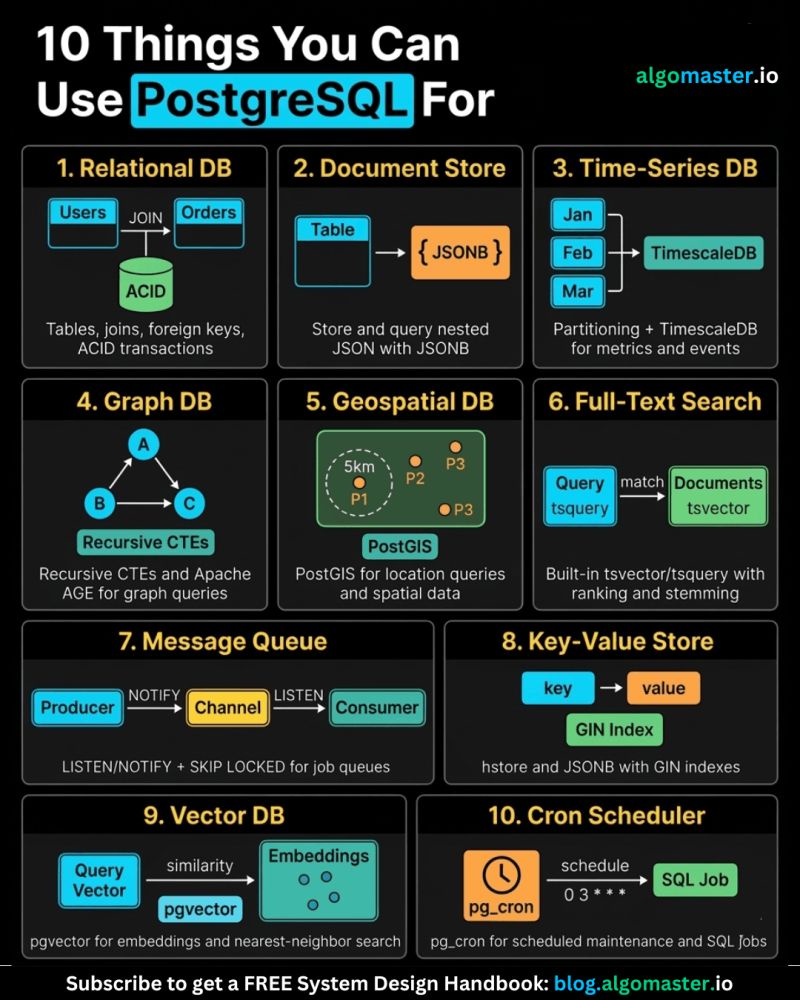
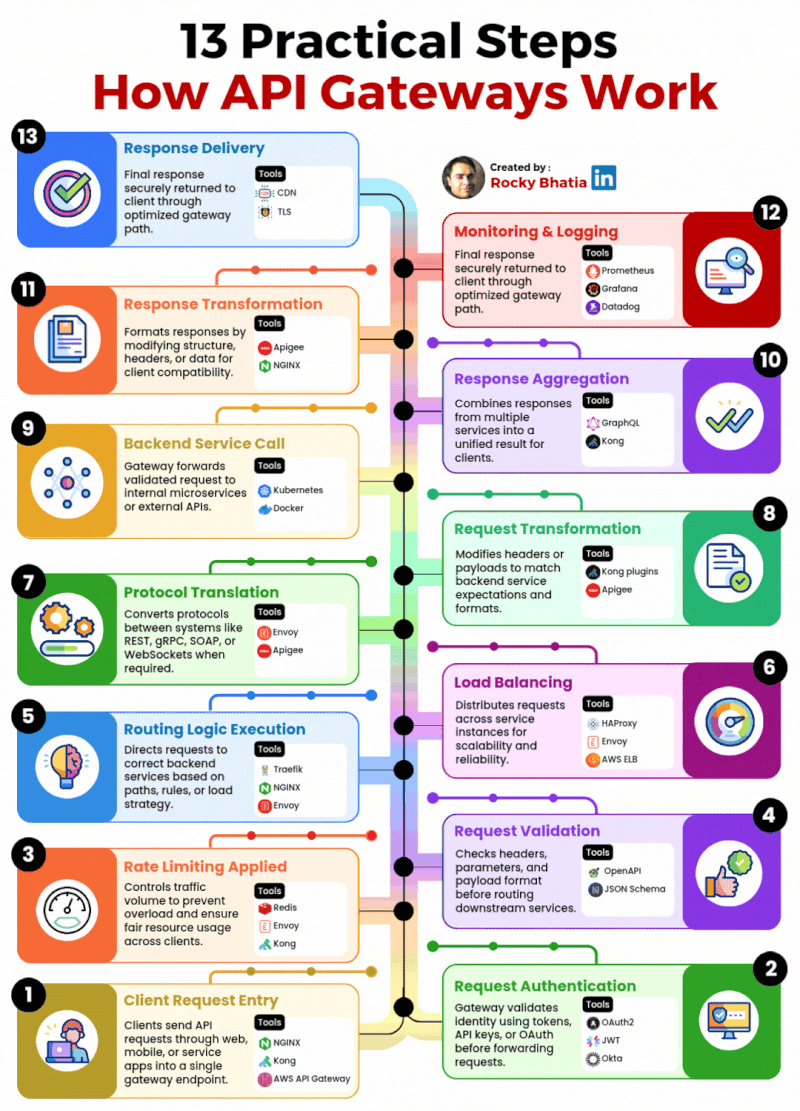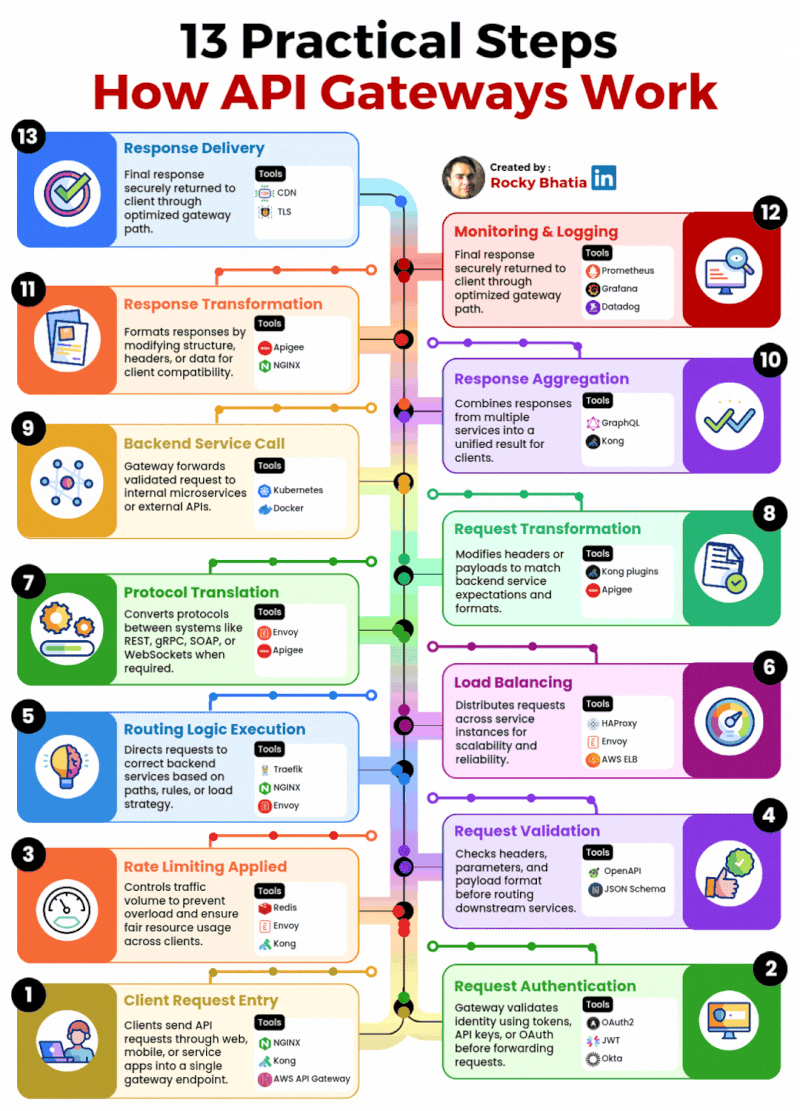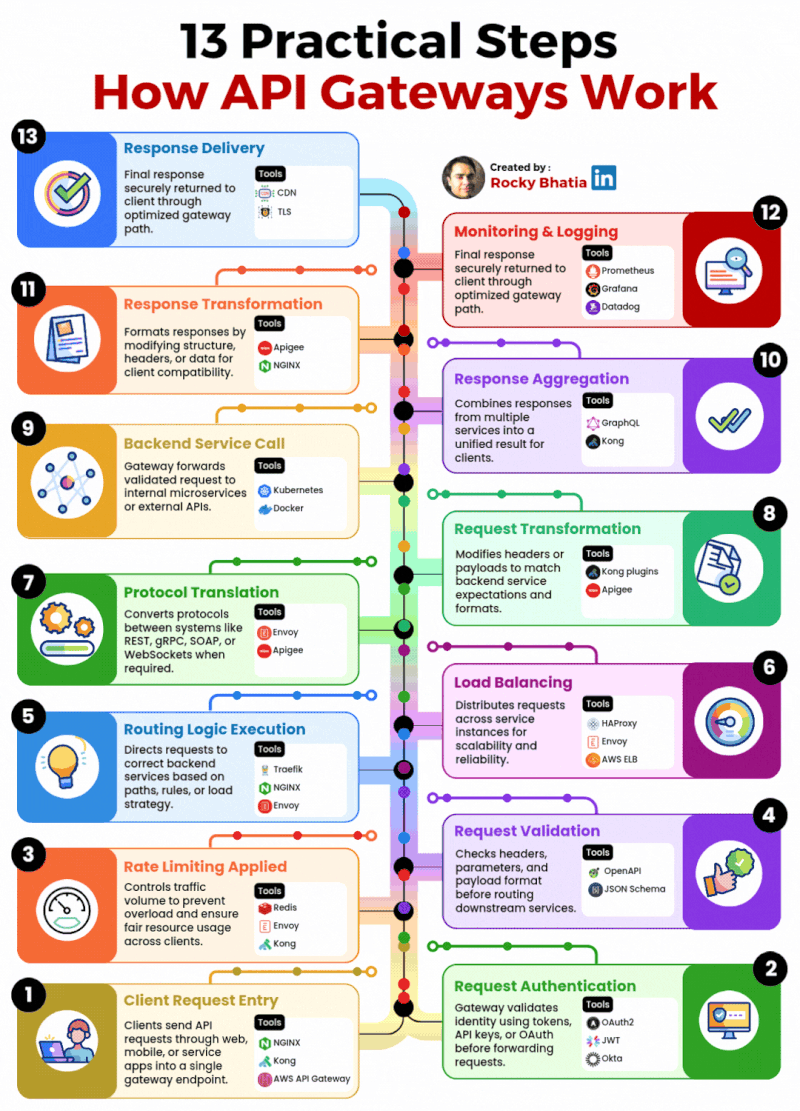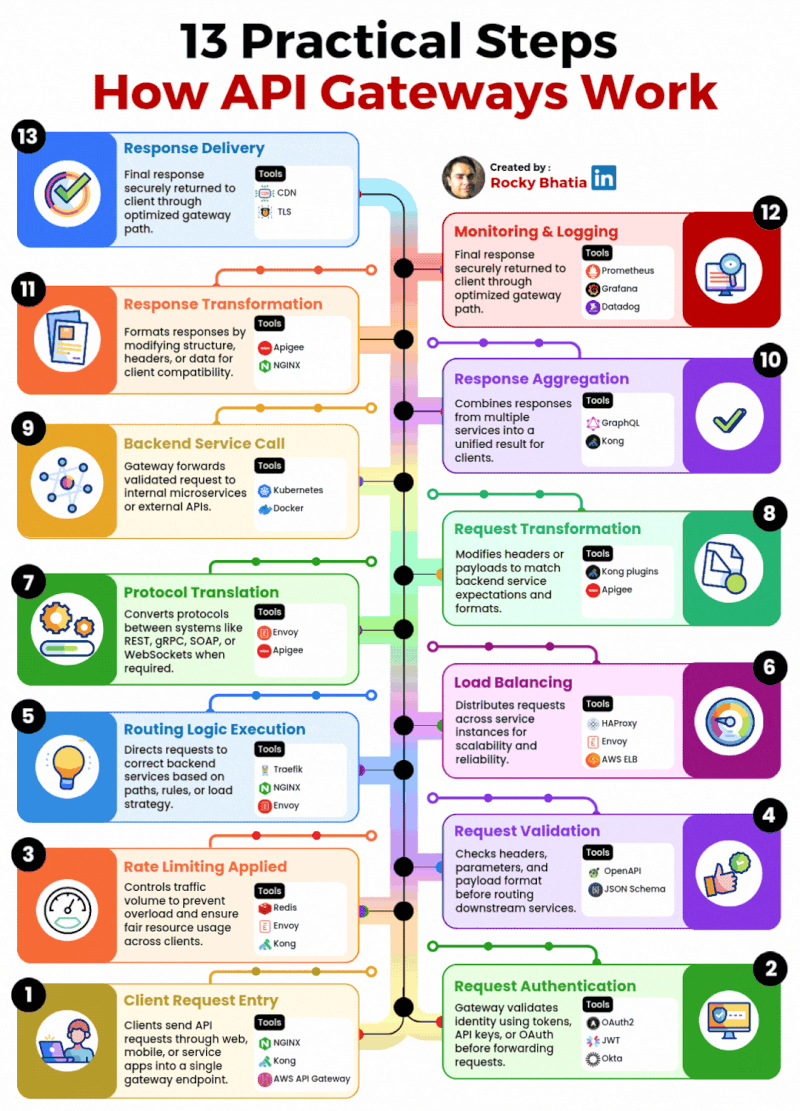
1. 𝐑𝐞𝐥𝐚𝐭𝐢𝐨𝐧𝐚𝐥 𝐃𝐚𝐭𝐚𝐛𝐚𝐬𝐞 The classic use case. PostgreSQL excels at managing structured data with tables, relationships, joins, constraints, and fully ACID-compliant transactions.
2. 𝐃𝐨𝐜𝐮𝐦𝐞𝐧𝐭 𝐒𝐭𝐨𝐫𝐞 PostgreSQL supports JSON and JSONB natively, so you can store and query semi-structured data with ease.
3. 𝐓𝐢𝐦𝐞-𝐒𝐞𝐫𝐢𝐞𝐬 𝐃𝐚𝐭𝐚𝐛𝐚𝐬𝐞 You can use native table partitioning for time-based data, or add TimescaleDB for features like automatic chunking, compression, and continuous aggregates.
4. 𝐆𝐫𝐚𝐩𝐡 𝐃𝐚𝐭𝐚𝐛𝐚𝐬𝐞 Recursive CTEs allow you to model and traverse hierarchies and graph-like relationships directly in SQL. For more advanced graph workloads, the Apache AGE extension brings Cypher query support to PostgreSQL.
5. 𝐆𝐞𝐨𝐬𝐩𝐚𝐭𝐢𝐚𝐥 𝐃𝐚𝐭𝐚𝐛𝐚𝐬𝐞 With PostGIS, PostgreSQL becomes a powerful geospatial database. You can store points, polygons, and other geometries, then run spatial queries like “find all restaurants within 5 km” with excellent performance.
6. 𝐅𝐮𝐥𝐥-𝐓𝐞𝐱𝐭 𝐒𝐞𝐚𝐫𝐜𝐡 𝐄𝐧𝐠𝐢𝐧𝐞 PostgreSQL includes built-in full-text search capabilities through tsvector and tsquery. You get indexing, ranking, stemming, and relevance-based search without needing a separate search engine for many use cases.
7. 𝐌𝐞𝐬𝐬𝐚𝐠𝐞 𝐐𝐮𝐞𝐮𝐞 PostgreSQL can also power lightweight messaging systems. LISTEN/NOTIFY enables pub/sub communication between connections, and SELECT ... FOR UPDATE SKIP LOCKED helps you build reliable job queues directly inside the database.
8. 𝐊𝐞𝐲-𝐕𝐚𝐥𝐮𝐞 𝐒𝐭𝐨𝐫𝐞 Using hstore or JSONB, PostgreSQL can serve as a key-value store as well. Both support indexing, which makes lookups fast. It can be a practical lightweight alternative to Redis for some workloads.
9. 𝐕𝐞𝐜𝐭𝐨𝐫 𝐃𝐚𝐭𝐚𝐛𝐚𝐬𝐞 With the pgvector extension, PostgreSQL can store embeddings and perform vector similarity search. You can create HNSW or IVFFlat indexes and run nearest-neighbor queries, making it a solid option for AI/ML applications.
10. 𝐂𝐫𝐨𝐧 𝐉𝐨𝐛 𝐒𝐜𝐡𝐞𝐝𝐮𝐥𝐞𝐫 With pg_cron, PostgreSQL can schedule recurring jobs directly from the database. This is useful for tasks like cleanup jobs, rollups, reporting, and maintenance workflows.
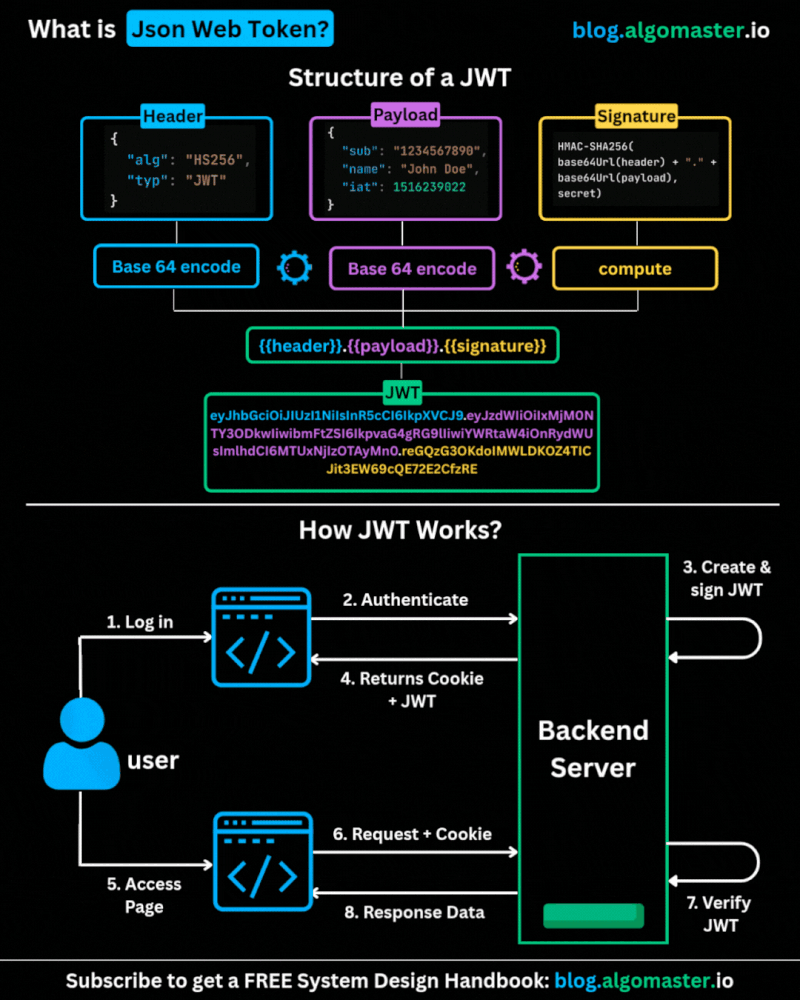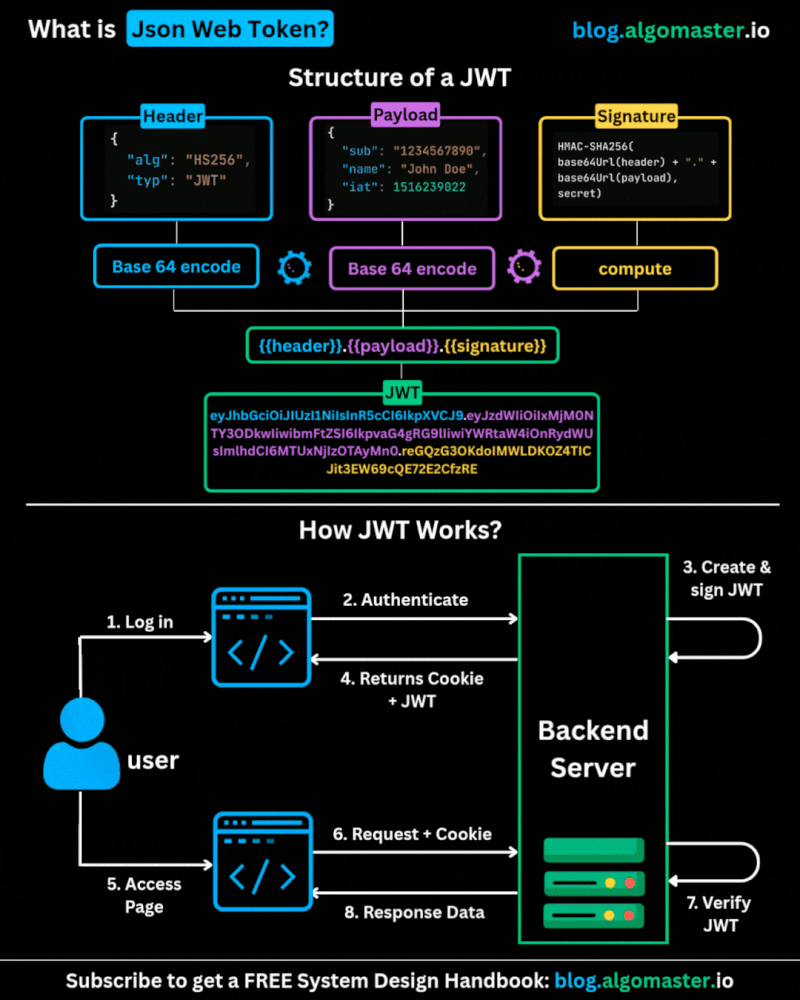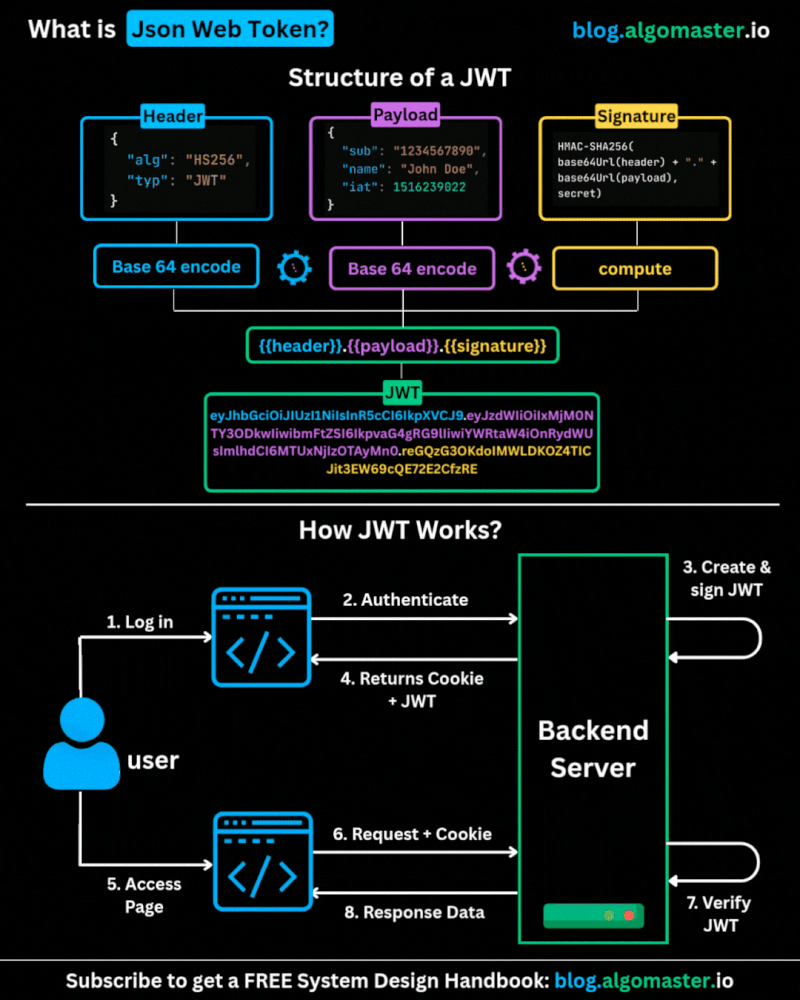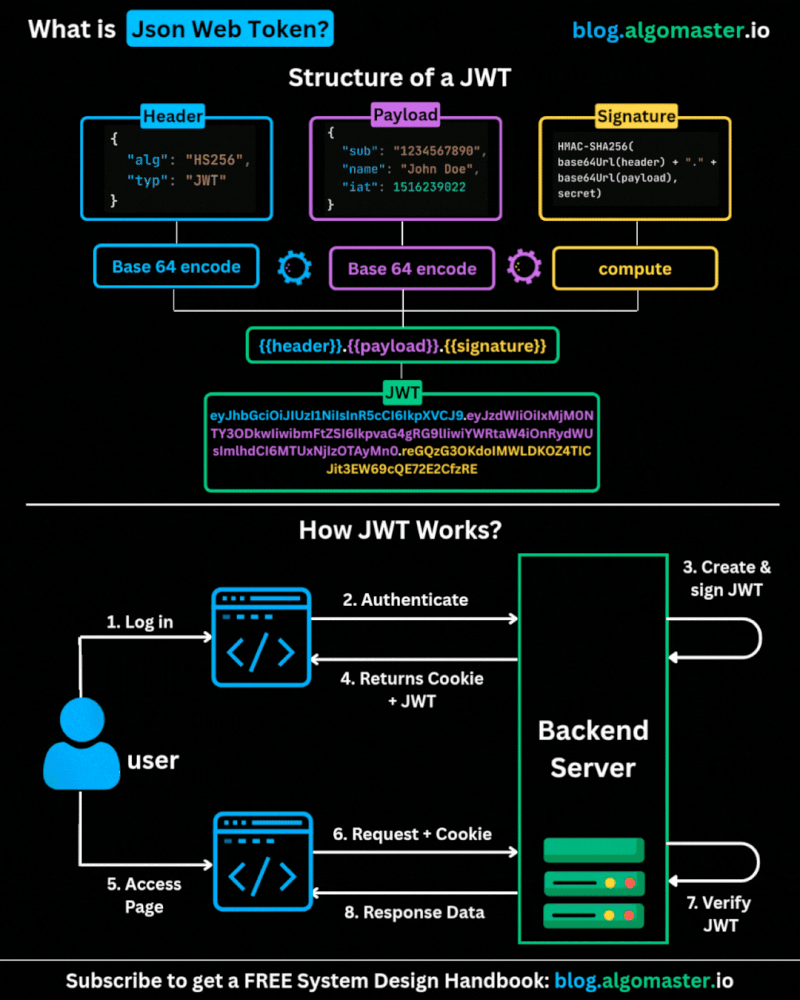
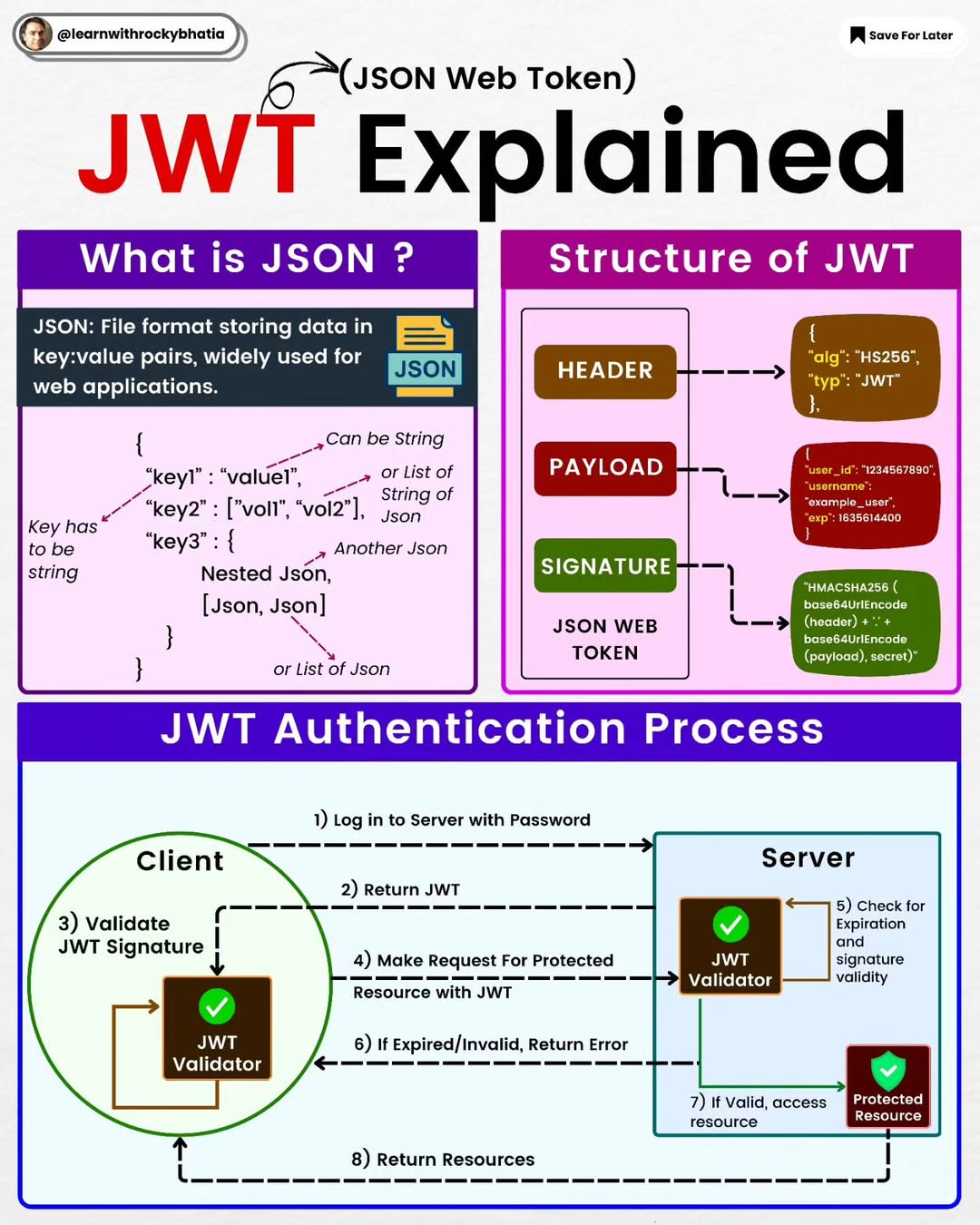
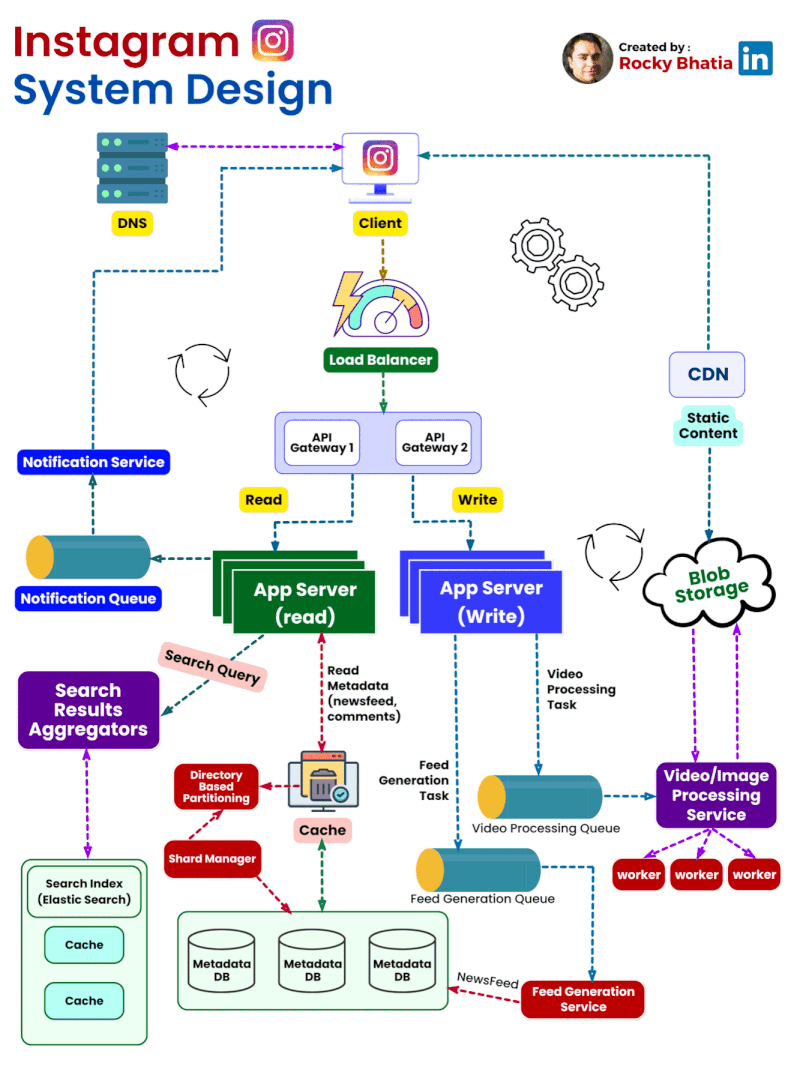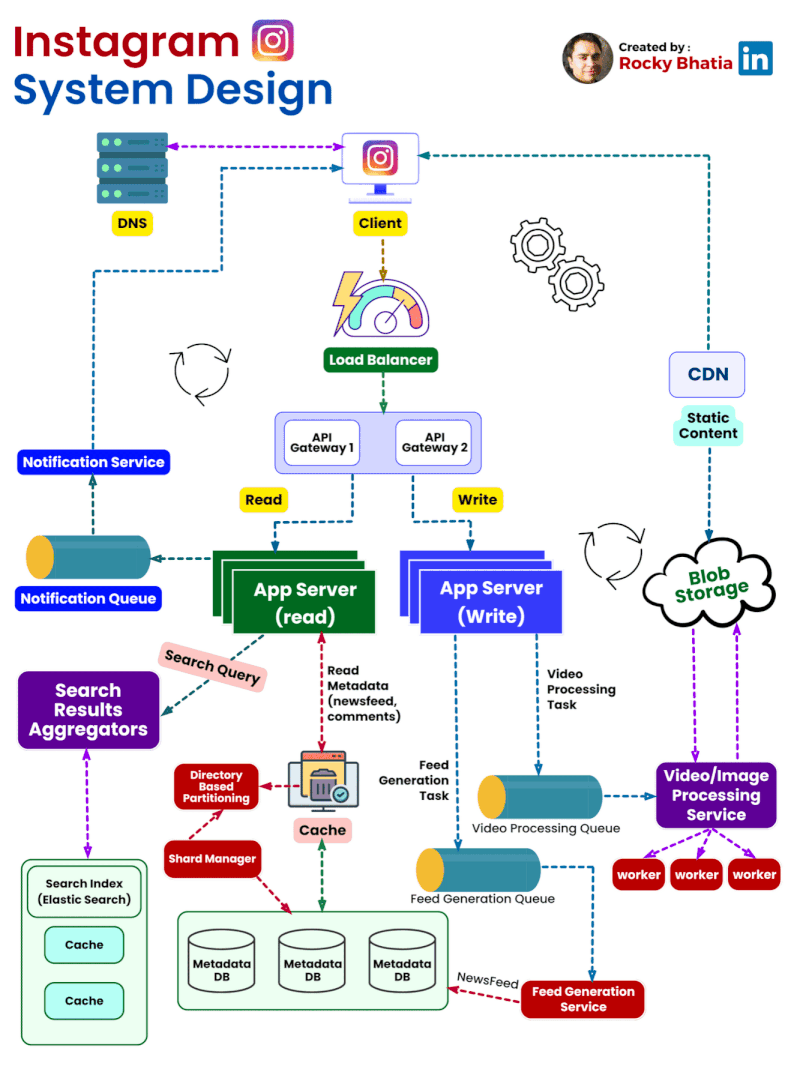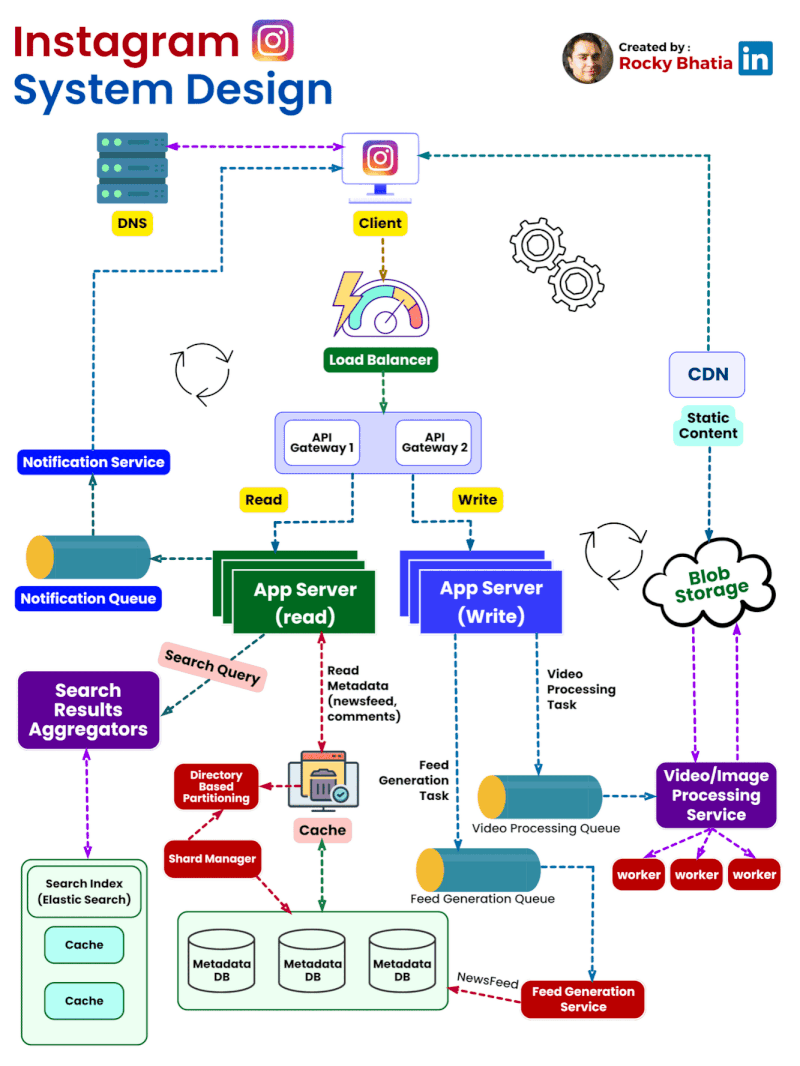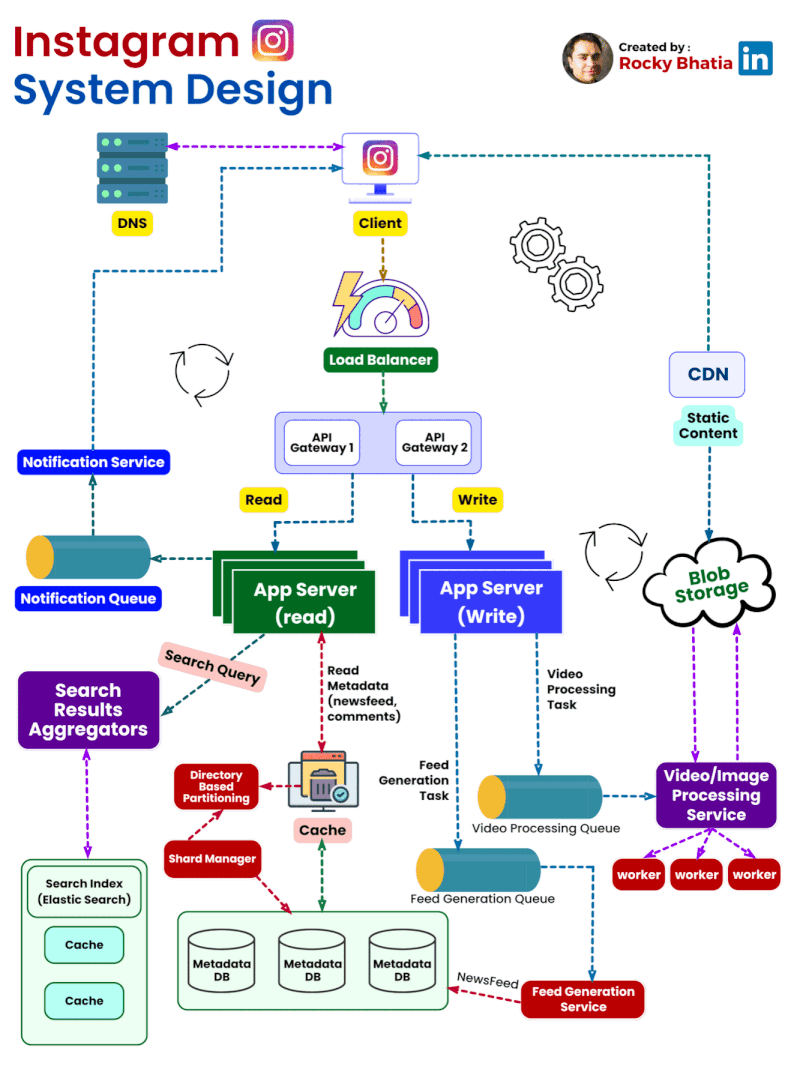
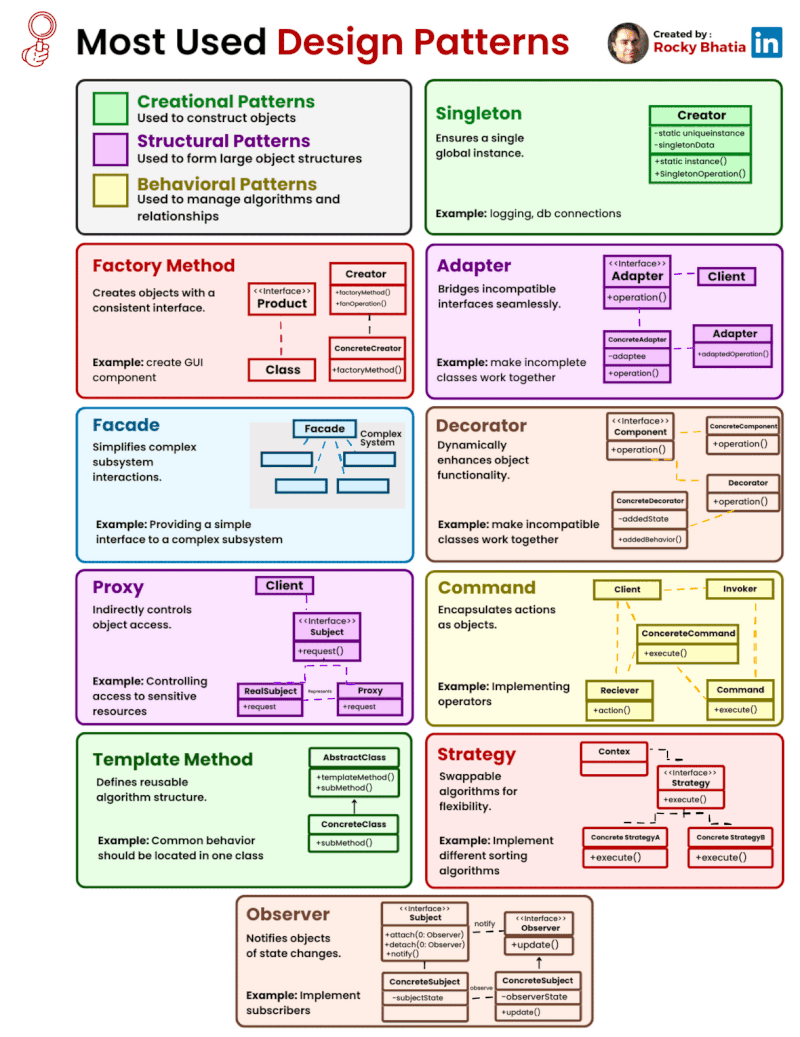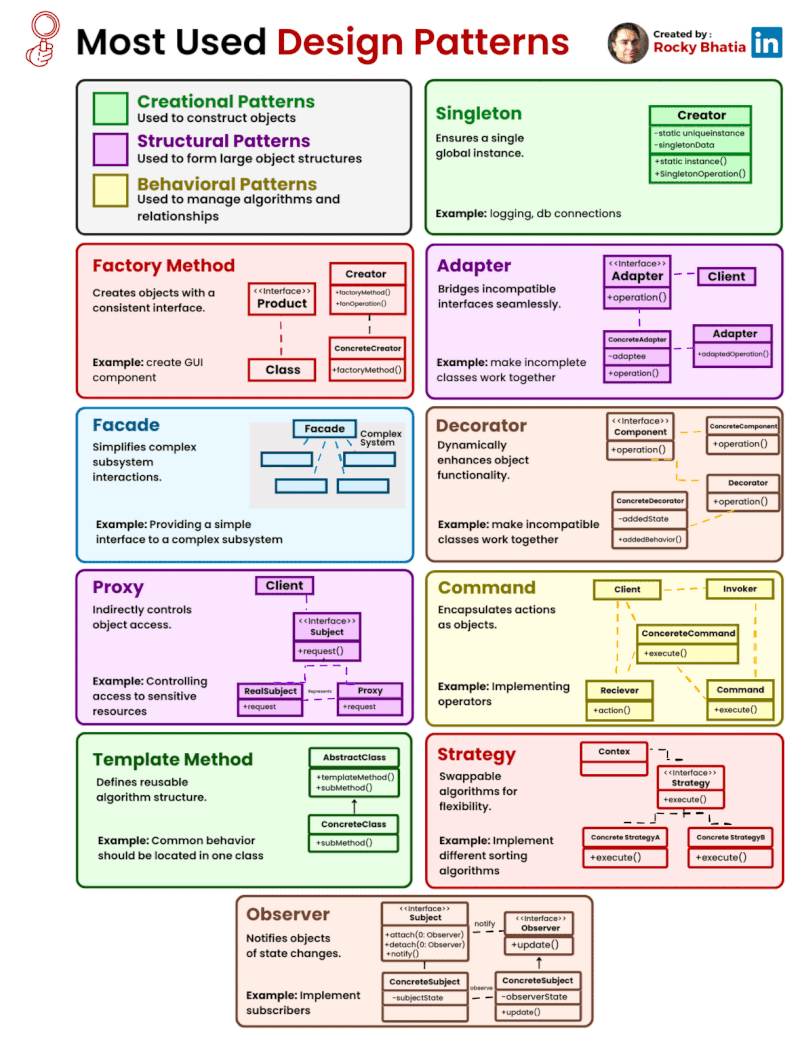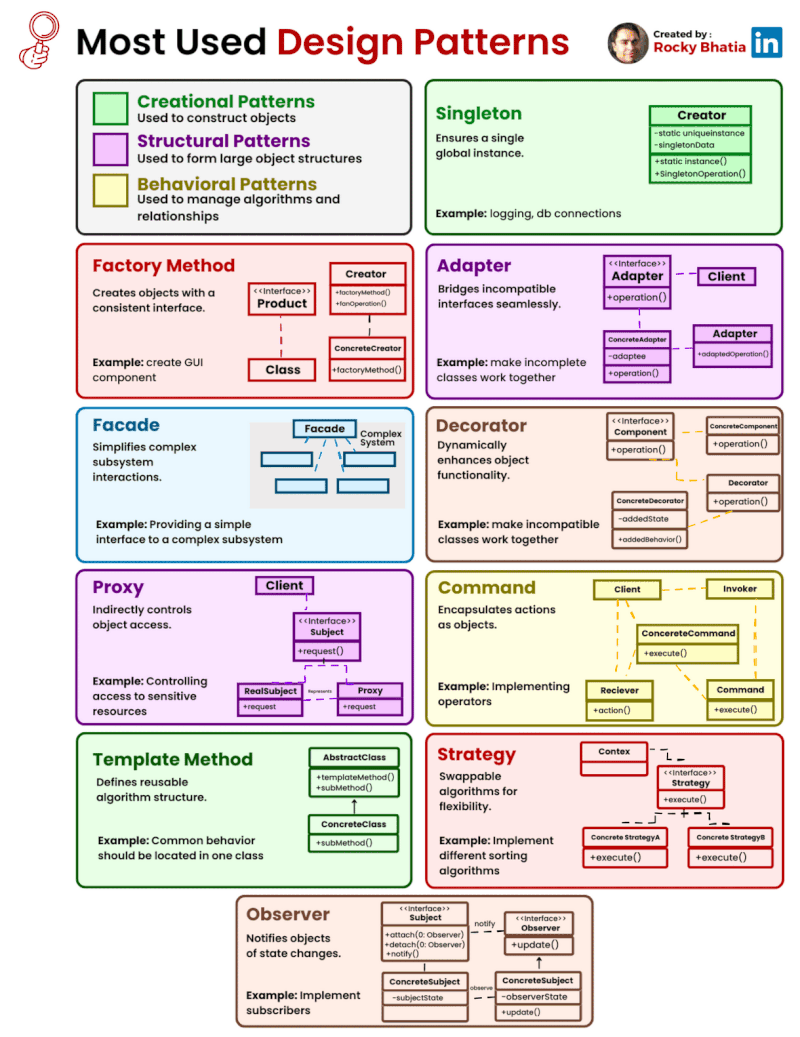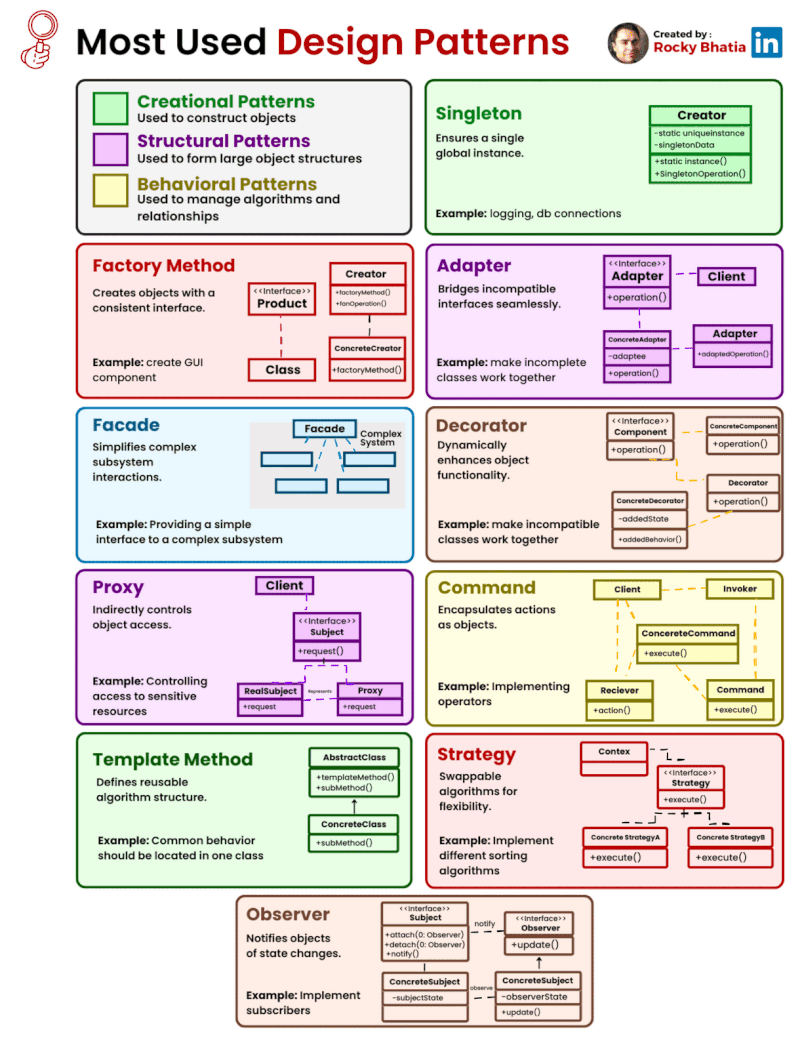 Categories of Design Patterns:
Categories of Design Patterns: