data


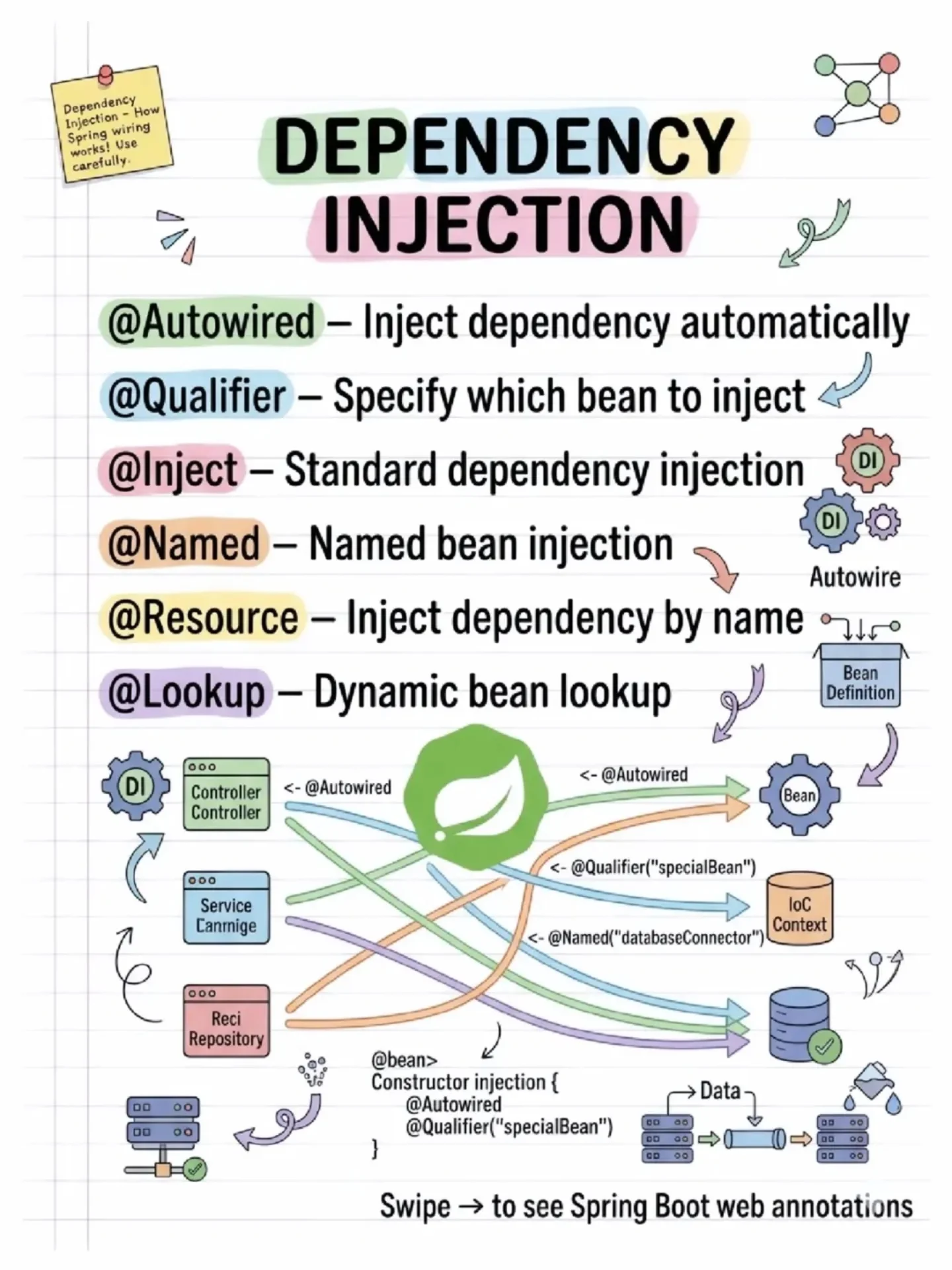
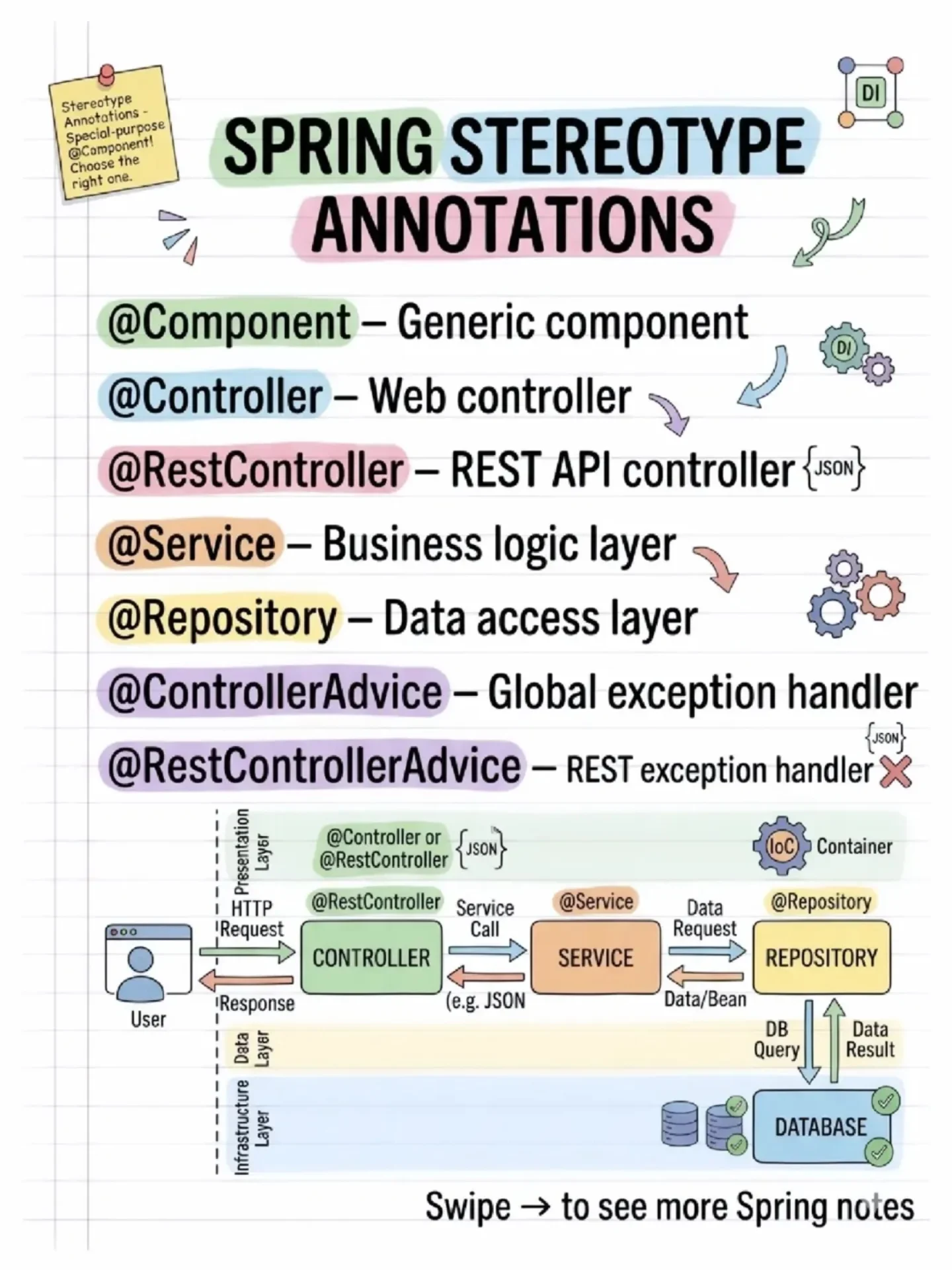

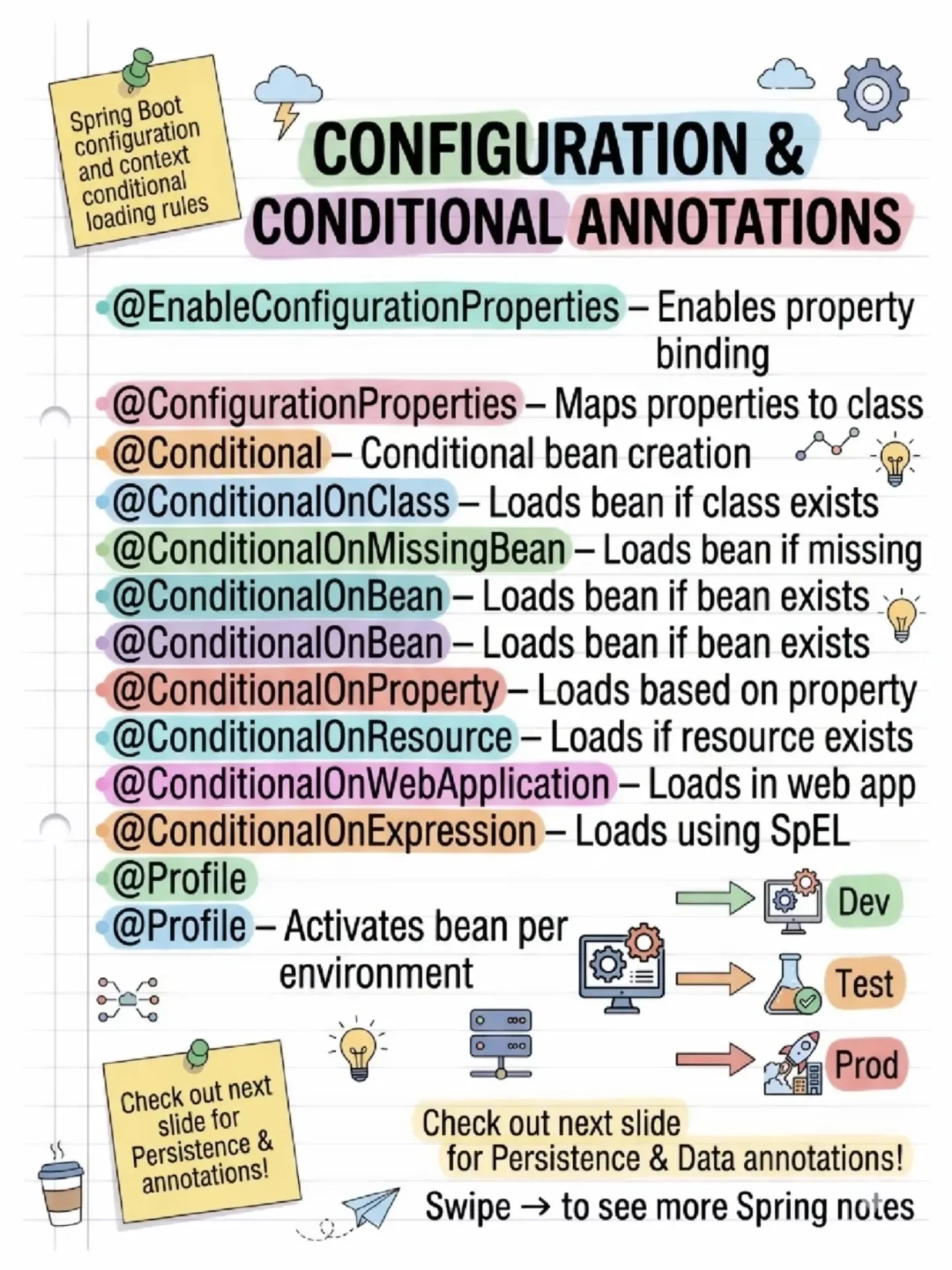
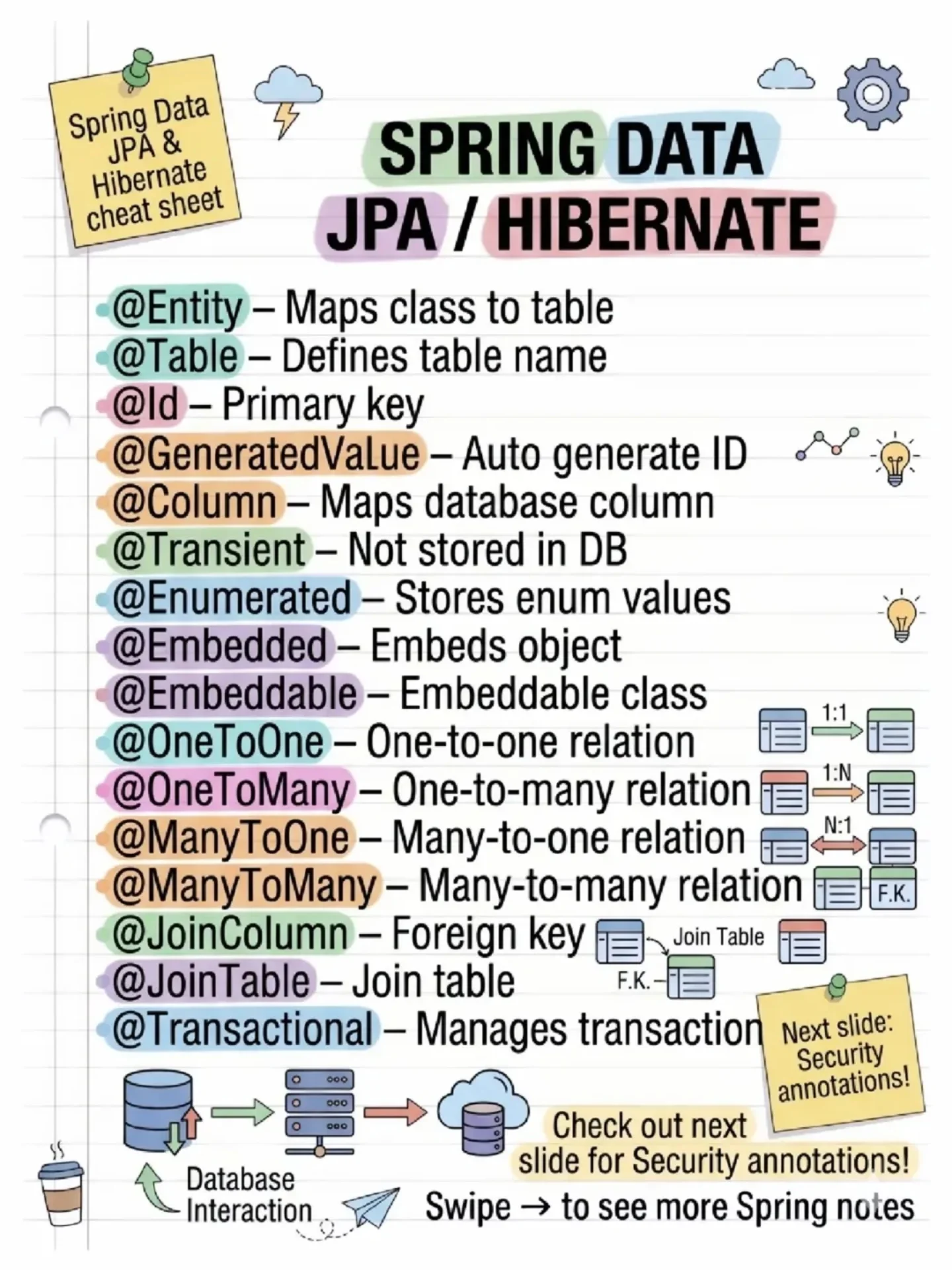


A Pattern Every Modern Developer Should Know: CQRS
CQRS, which stands for Command Query Responsibility Segregation, is an architectural pattern that separates the concerns of reading and writing data.
It divides an application into two distinct parts:
- The Command Side: Responsible for managing create, update, and delete requests.
- The Query Side: Responsible for handling read requests.
The CQRS pattern was first introduced by Greg Young, a software developer and architect, in 2010. He described it as a way to separate the responsibility of handling commands (write operations) from handling queries (read operations) in a system.
The origins of CQRS can be traced back to the Command-Query Separation (CQS) principle, introduced by Bertrand Meyer. CQS states that every method should either be a command that performs an action or a query that returns data, but not both. CQRS takes the CQS principle further by applying it at an architectural level, separating the command and query responsibilities into different models, services, or even databases.
Since its introduction, CQRS has gained popularity in the software development community, particularly in the context of domain-driven design (DDD) and event-driven architectures.
It has been successfully applied in various domains, such as e-commerce, financial systems, and collaborative applications, where performance, scalability, and complexity are critical concerns.
In this post, we’ll learn about CQRS in comprehensive detail. We will cover the various aspects of the pattern along with a decision matrix on when to use it.
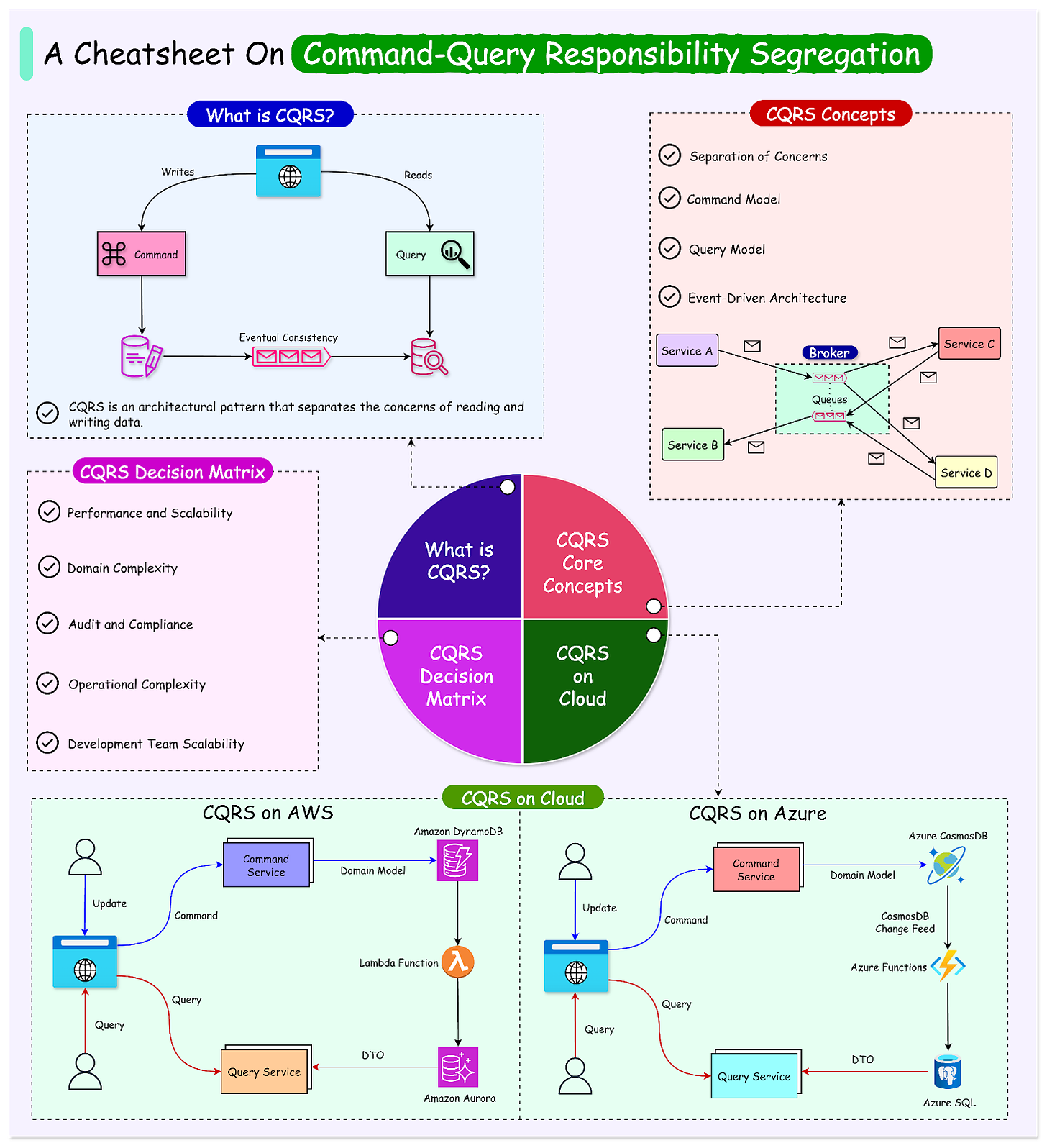
Core Concepts of CQRS
The overall CQRS pattern is made up of a few core concepts:
- Separation of Command and Query models
- Command Model
- Query Model
- Event-Driven Architecture
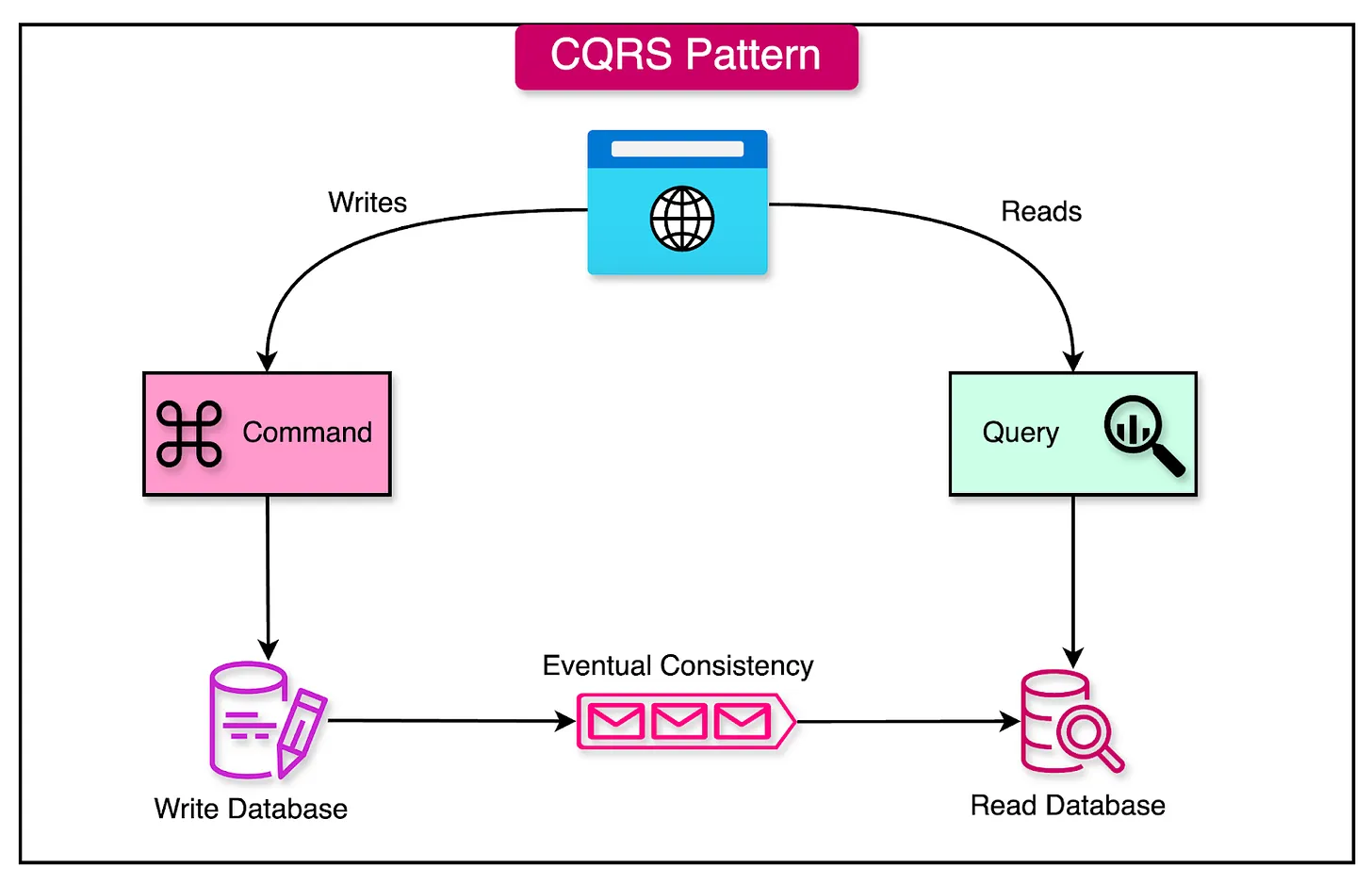
The diagram below shows a simple view of the CQRS pattern
To understand things better, let us look at each core concept in greater detail:
Separation of Command Model From Query Model
The fundamental principle of CQRS is the separation of the command model from the query model
- Command Model: Responsible for handling write operations and updating the system state.
- Query Model: Dedicated to providing efficient and flexible data access for read operations.
This separation enables each model to be optimized independently based on its specific requirements, enhancing the scalability, performance, and maintainability of complex systems.
Command Model (Write Operations)
The command model in CQRS handles all write operations, including creating, updating, and deleting data.
Key aspects of the command model include:
- Task-Based Operations: Commands are typically represented as task-based operations (e.g., “CreateOrder” or “UpdateCustomerAddress”) rather than generic CRUD operations.
- Command Handlers: Process commands by executing the corresponding business logic and persisting changes to the write database.
- Event Sourcing: The command model may incorporate event sourcing, where the system state is determined by a sequence of events, providing a complete audit trail and enabling powerful capabilities like event replay and temporal queries. More on this in a later section.
Query Model (Read Operations)
The query model in CQRS handles all read operations and provides efficient data access for querying and reporting purposes.
Key features of the query model include:
- Optimized Data Structures: These could be denormalized data structures or materialized views for fast and flexible data retrieval.
- Tailored Structure: The query model can have a different structure than the command model, specifically designed for the read scenarios required by the application.
- Data Aggregation: The query model may aggregate data from multiple sources, precompute complex calculations, or generate read-friendly data projections.
Event-Driven Architecture
CQRS often integrates with event-driven architectures, where changes in the system state are propagated as events.
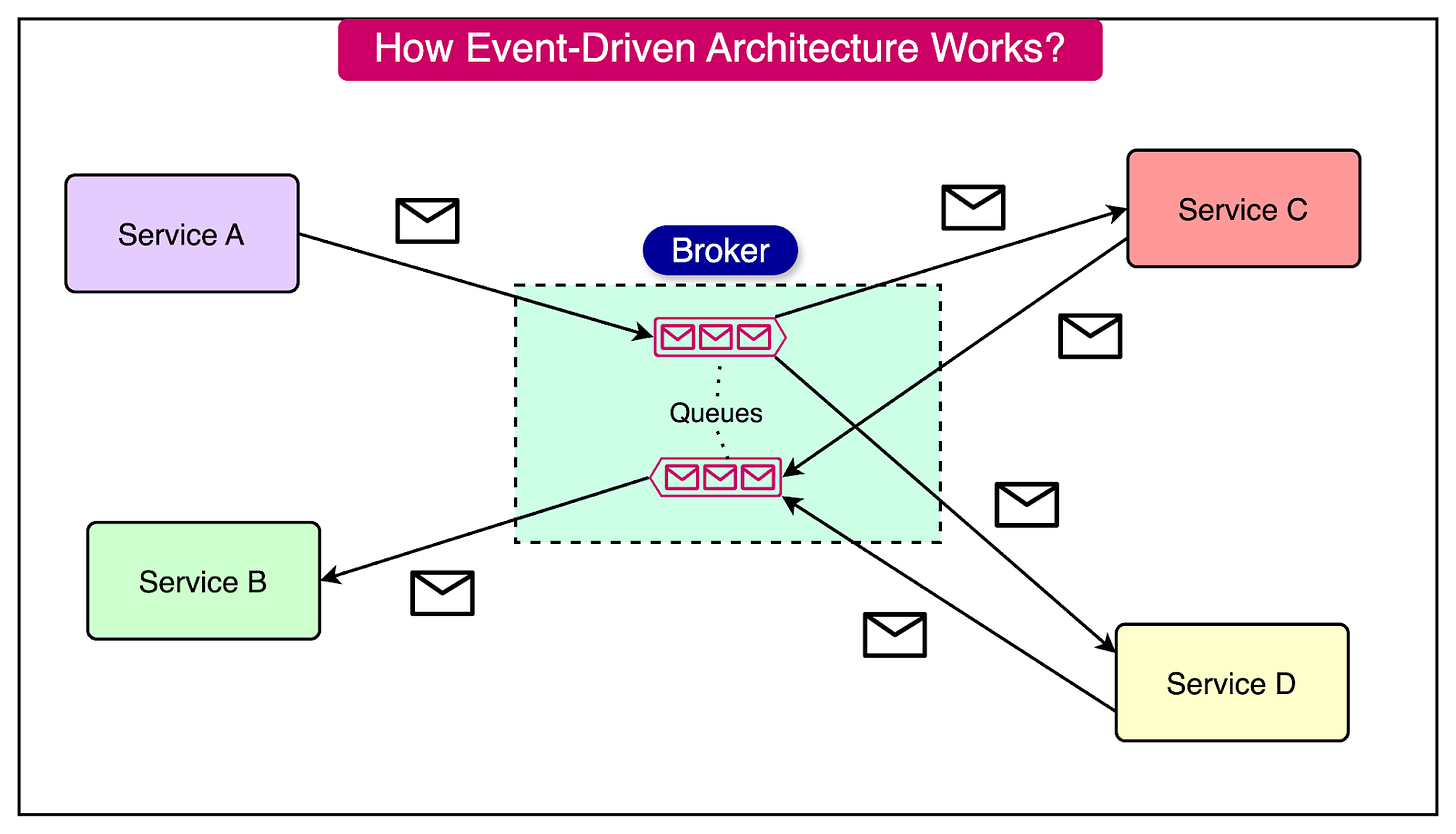
This integration provides several benefits:
- Asynchronous Communication: When a command is processed and the write model is updated, events are generated to notify other parts of the system, including the query model.
- Eventual Consistency: The query model can subscribe to these events and update its data stores, ensuring eventual consistency between the command and query sides.
- Loose Coupling: Event-driven communication allows for loose coupling between models. This enables independent scaling and evolution.
- System Integration: Facilitates integration with other systems and enables complex business processes to be modeled as a series of events.
CQRS in Action
Let us understand more about CQRS using the e-commerce domain as an example.
E-commerce platforms often face challenges in managing product inventory, orders, and customer data due to the conflicting requirements of read or write operations.
Traditional e-commerce architectures that use a single data model for both read and write operations face several limitations:
- Performance Impact: Complex queries for product listings and recommendations can slow down the system and impact the performance of write operations like inventory updates and order processing.
- Scalability Challenges: Managing high traffic during peak shopping periods can be challenging due to resource contention between read and write operations on the same data model.
- Feature Development Complexity: Implementing new features that require changes to the data model can be difficult and may necessitate costly migrations.
Applying the Command Query Responsibility Segregation (CQRS) pattern can address these challenges by separating the read and write models.
Write (Command) Model
The command model works as follows:
- Responsibilities: Handles inventory updates, order placements, and customer data modifications.
- Optimization: Optimized for fast, low-latency write operations using a database like MongoDB or Cassandra.
- Event Publishing: Publishes events for each command, such as “ProductAdded”, “OrderPlaced”, or “CustomerAddressUpdated”.
Read (Query) Model
The query model works as follows:
- Responsibilities: Handles product listings, search queries, order history, and customer profile views.
- Optimization: Optimized for fast, complex read queries.
- Event Subscription: Subscribes to events from the write model and updates its data stores accordingly, ensuring eventual consistency.
Implementing CQRS
Implementing Command Query Responsibility Segregation (CQRS) in a system involves several architectural patterns that enhance the overall design and performance.
Two key patterns that often go hand in hand with CQRS are Event Sourcing and Microservices.
CQRS also encourages a task-based approach to user interface (UI) design, leading to more intuitive and efficient user experiences.
Let’s look at them in more detail:
Event Sourcing and Its Synergy with CQRS
Event Sourcing is an architectural pattern that involves storing the state of a system as a sequence of events rather than just the current state. This approach aligns well with CQRS, particularly on the command side.
See the diagram below that shows the concept of event sourcing
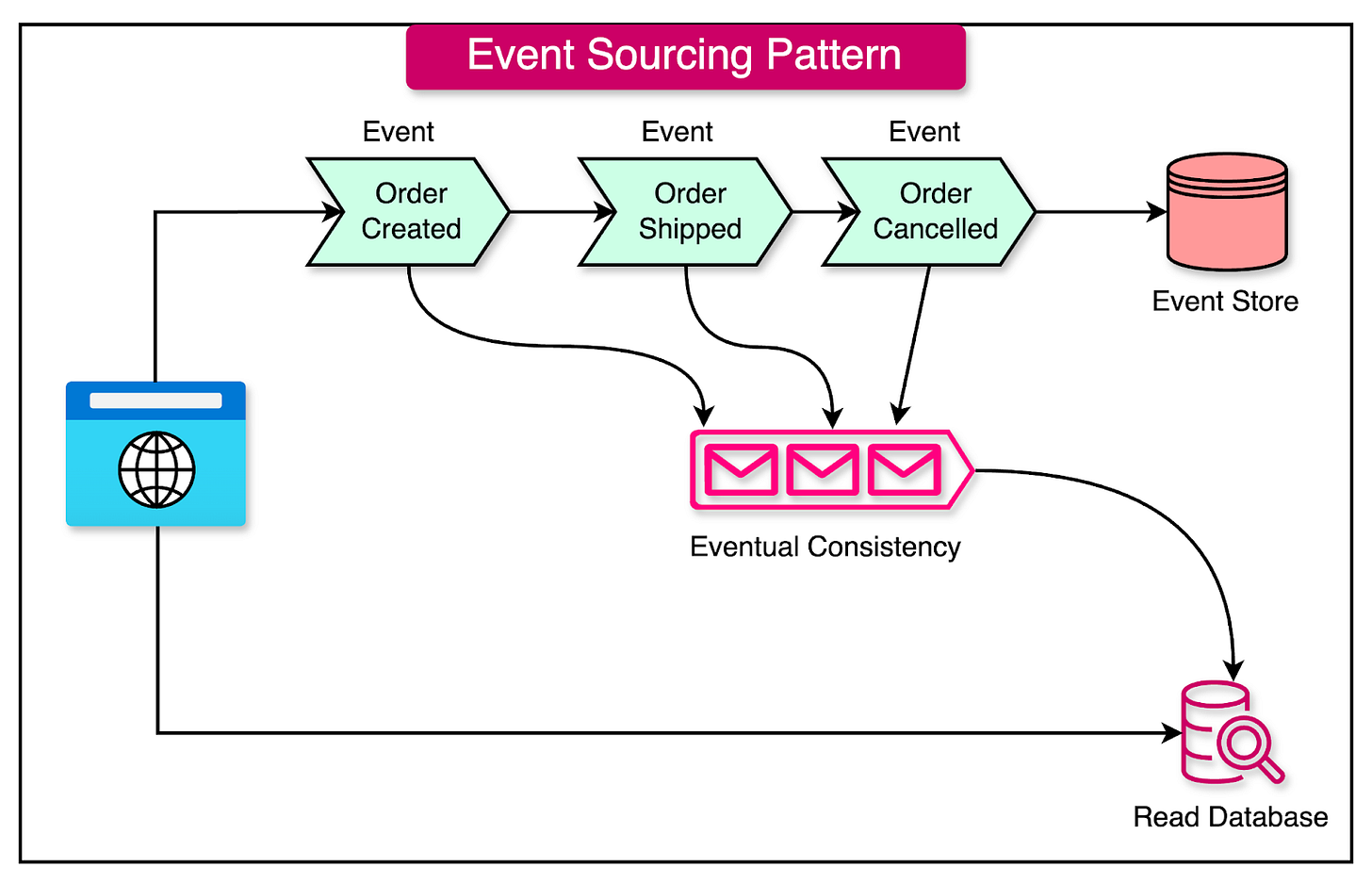
Key aspects of this synergy include:
- Natural Fit with the Command Model: In CQRS, commands can be easily translated into events, which are then stored in an append-only event store. This natural fit simplifies the implementation of the command model.
- Audit Trail and Historical Reconstruction: Event Sourcing provides a complete history of state changes, enabling powerful auditing capabilities and the ability to reconstruct past states. This feature is valuable for systems that require strong auditing and compliance.
- Flexibility in Read Model Creation: The event stream generated by Event Sourcing can be used to build and rebuild various read models, allowing for greater flexibility in how data is presented and queried. This flexibility enables the system to adapt to changing requirements and optimize read performance.
- Scalability: CQRS and Event Sourcing support independent scaling of read and write operations, enhancing overall system performance. The separation of concerns allows for optimized resource allocation and improved responsiveness.
Task-Based UI Design
CQRS encourages a task-based approach to UI design, which can lead to more intuitive and efficient user interfaces:
- Command-Oriented Interactions: UIs can be designed around specific user tasks (commands) rather than CRUD operations on data entities. This approach aligns the UI more closely with the user's goals and intentions.
- Simplified Validation: Task-based UIs can incorporate client-side validation, reducing the likelihood of server-side command failures. By validating user input before sending commands to the server, the system can provide faster feedback and a smoother user experience.
- Alignment with Domain Model: Task-based UIs often align more closely with the underlying domain model, improving overall system coherence. By reflecting the domain concepts and operations in the UI, the system becomes more understandable and maintainable.
Microservices and CQRS
CQRS can be effectively implemented within a microservices architecture, offering several benefits:
- Bounded Contexts: CQRS aligns well with the concept of bounded contexts in Domain-Driven Design, which is often used in microservices architectures. Each microservice can have its bounded context, with its own command and query models.
- Independent Deployment: The separation of command and query models in CQRS allows for independent deployment and scaling of these components as separate microservices. This independence enables more flexible and targeted scaling based on the specific demands of each model.
- Polyglot Persistence: With CQRS, different microservices can use different data stores optimized for their specific read or write requirements. This polyglot persistence approach allows for choosing the most suitable database technology for each microservice.
- Event-Driven Communication: Microservices can communicate changes through events, which fits naturally with the CQRS model. Events can be used to propagate updates and maintain consistency across multiple microservices.
CQRS on Cloud Platforms
Cloud platforms like Amazon Web Services (AWS) and Microsoft Azure provide a range of services that facilitate the implementation of the Command Query Responsibility Segregation (CQRS) pattern.
Do note that it is not necessary to use cloud platforms to implement the pattern. However, these platforms offer scalable, managed services that align well with the principles of CQRS, enabling developers to build high-performance, resilient systems with reduced operational overhead.
AWS Implementation (using DynamoDB and Aurora)
AWS provides several services that can be used to implement the CQRS pattern effectively.
A common approach is to use DynamoDB for the write model and Aurora for the read model. Some key points about the implementation are as follows:
- Write Model with DynamoDB: DynamoDB, a fully managed NoSQL database, is well-suited for the command side due to its ability to handle high-volume write operations with low latency and high throughput. Its flexible schema allows for easy storage of event data.
- Read Model with Aurora: For the query side, Amazon Aurora, a relational database compatible with MySQL and PostgreSQL, offers high read scalability and performance. It can handle complex queries and provide read-optimized views of the data.
- Synchronization with DynamoDB Streams: DynamoDB streams can be used to keep the read model in sync with the write model. Any updates to the write model in DynamoDB can trigger a Lambda function that processes the changes and updates the read model in Aurora accordingly, ensuring eventual consistency between the two models.
See the diagram below for reference:
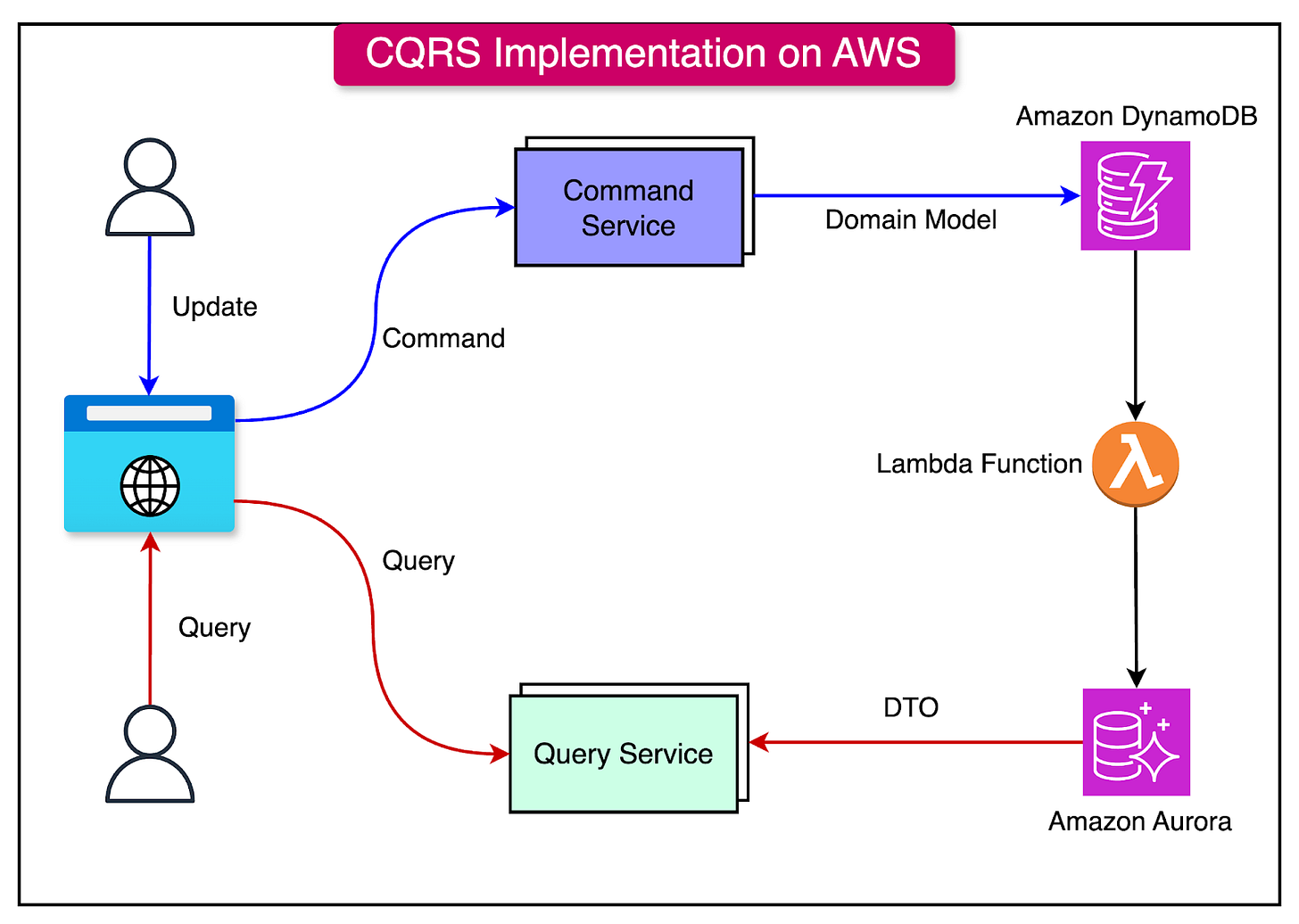
The main benefits of this approach include:
- Scalability: DynamoDB and Aurora can scale independently based on the read-and-write workloads.
- Performance: DynamoDB optimizes writes, while Aurora optimizes complex reads.
- Serverless: Both services offer serverless options, enabling pay-per-use pricing.
- Managed Services: AWS handles the operational tasks, reducing the burden on the development team.
Azure Implementation
Azure also provides various services that enable the implementation of CQRS.
A typical approach involves using Azure Cosmos DB for the write model and Azure SQL Database for the read model.
- Write Model with Cosmos DB: Azure Cosmos DB, a globally distributed, multi-model database service, is suitable for the command side. It offers high write throughput, low latency, and automatic scaling. Its flexible data model allows for easy storage of events and aggregates.
- Read Model with SQL Database: For the query side, Azure SQL Database, a fully managed relational database service, provides high performance and scalability for read-heavy workloads. It supports complex queries and can be used to create read-optimized views of the data.
- Synchronization with Cosmos DB Change Feed: To propagate changes from the write model to the read model, Azure Functions can be triggered by the Cosmos DB change feed. These functions can process the events and update the read model in the Azure SQL Database, ensuring eventual consistency.
See the diagram below for reference:
The key benefits of this approach include:
- Global Distribution: Cosmos DB enables the global distribution of data, reducing latency for users worldwide.
- Scalability: Cosmos DB and SQL Database can scale independently based on workload requirements.
- Flexibility: Cosmos DB supports multiple data models, allowing for flexibility in event storage.
- Managed Services: Azure handles the management and operations of the databases, reducing overhead.
When to Use CQRS: A Decision Framework
Deciding whether to apply the Command Query Responsibility Segregation (CQRS) pattern to a system requires careful consideration of various factors.
This decision framework helps evaluate the suitability of CQRS based on the system's specific requirements and characteristics.

Performance and Scalability Needs
CQRS can be particularly beneficial for systems with high performance and scalability demands, especially when the read-and-write workloads have different requirements:
- High Read-to-Write Ratio: If the system experiences a significantly higher number of read operations compared to write operations, CQRS allows optimizing the read side independently, potentially using a separate read-optimized data store.
- Independent Scaling: CQRS enables scaling the read and write sides separately based on their respective loads, allowing for better resource utilization and cost optimization.
However, for systems with moderate traffic and simple performance needs, the added complexity of CQRS may not be justified.
Domain Complexity
The complexity of the business domain is a key factor in deciding whether to use CQRS:
- Complex Business Logic: If the domain involves intricate business rules and logic that differ significantly between read and write operations, CQRS can help manage this complexity by separating the concerns.
- Simple CRUD Operations: For systems with straightforward create, read, update, and delete (CRUD) operations, such as a basic blog or to-do list application, CQRS may introduce unnecessary complexity.
It's important to note that CQRS should be applied selectively to specific bounded contexts or subdomains where it provides the most value, rather than enforcing it across the entire system.
Audit and Compliance Requirements
Systems with strict auditing and compliance requirements can benefit from CQRS, particularly when combined with event sourcing:
- Detailed Audit Trails: CQRS with event-sourcing enables capturing all state changes as events, providing a complete audit trail for regulatory compliance and historical analysis.
- Temporal Queries: Event sourcing allows querying the system's state at any point in time, which can be valuable for auditing and debugging purposes.
Operational Complexity Tolerance
Implementing CQRS introduces additional operational complexity, which should be considered based on the team's capabilities and project constraints:
- Skilled Team: If the development team has experience with CQRS and can effectively manage the increased complexity, it can be a viable option for complex domains.
- Limited Resources: For smaller teams or projects with tight deadlines, the learning curve and operational overhead associated with CQRS may not be feasible.
Development Team Capability
The capability and structure of the development team can influence the decision to adopt CQRS:
- Large, Distributed Teams: CQRS can be beneficial for large development teams working on different aspects of the system, as it allows for a clear separation of responsibilities and independent development of the read-and-write models.
- Small, Co-located Teams: For smaller teams working closely together, the added complexity of CQRS may not provide significant benefits and potentially hinder productivity.
Summary
In this article, we’ve taken a detailed look at Command Query Responsibility Segregation (CQRS).
Let’s summarize our learnings in brief:
- CQRS is an architectural pattern that separates the concerns of reading and writing data.
- The core concepts of CQRS include separation of concerns, command model, query model, and event-driven architecture.
- CQRS mainly consists of two functionalities – the write (command) model and the read (query) model.
- Event Sourcing is an architectural pattern that involves storing the state of a system as a sequence of events rather than just the current state. This approach aligns well with CQRS, particularly on the command side.
- CQRS encourages a task-based approach to UI design, which can lead to more intuitive and efficient user interfaces.
- CQRS can be effectively implemented within a microservices architecture, offering several benefits:
- Cloud platforms like Amazon Web Services (AWS) and Microsoft Azure provide a range of services that facilitate the implementation of the Command Query Responsibility Segregation (CQRS) pattern.
- Deciding whether to apply the Command Query Responsibility Segregation (CQRS) pattern to a system requires careful consideration of various factors such as performance, scalability, domain complexity, audit, compliance, operational complexity, and the scalability of the development team.
Data Sharing Between Microservices
Microservices architecture has become popular for building complex, scalable software systems.
This architectural style structures an application as a collection of loosely coupled, independently deployable services. Each microservice is focused on a specific business capability and can be developed, deployed, and scaled independently.
While microservices offer numerous benefits, such as improved scalability, flexibility, and faster time to market, they also introduce significant challenges in terms of data management.
One of the fundamental principles of microservices architecture is that each service should own and manage its data. This principle is often expressed as “don't share databases between services” and it aims to ensure loose coupling and autonomy among services, allowing them to evolve independently.
However, it's crucial to distinguish between sharing a data source and sharing data itself. While sharing a data source (e.g., a database) between services is discouraged, sharing data between services is often necessary and acceptable.
In this post, we’ll look at different ways of sharing data between microservices and the various advantages and disadvantages of specific approaches.

Sharing Data Source vs Sharing Data
As mentioned earlier, it's crucial to understand the difference between sharing a data source and sharing data itself when working with microservices.
This distinction has significant implications for service coupling, independence, and overall system design.
Sharing a data source means multiple services directly access the same database, potentially leading to tight coupling and dependencies. It violates the principle of service data ownership in microservices.
On the other hand, sharing data involves services exchanging data through well-defined APIs or messaging patterns, maintaining their local copies of the data they need. This helps preserve service independence and loose coupling.
Let's consider an example scenario involving an Order service and a Product service to illustrate the data-sharing dilemma.
- Order Service:
- Manages order information.
- Stores order details in its database.
- Product Service:
- Handles product information.
- Maintains a separate database for product details.
- Relationship:
- Each order is associated with a set of products
The challenge arises when the Order service needs to display product information alongside order details.
In a monolithic architecture, this would be straightforward since all the data resides in a single database. However, in a microservices architecture, the Order service should not directly access the Product service database. Instead, it should fetch the data via the Product Service.
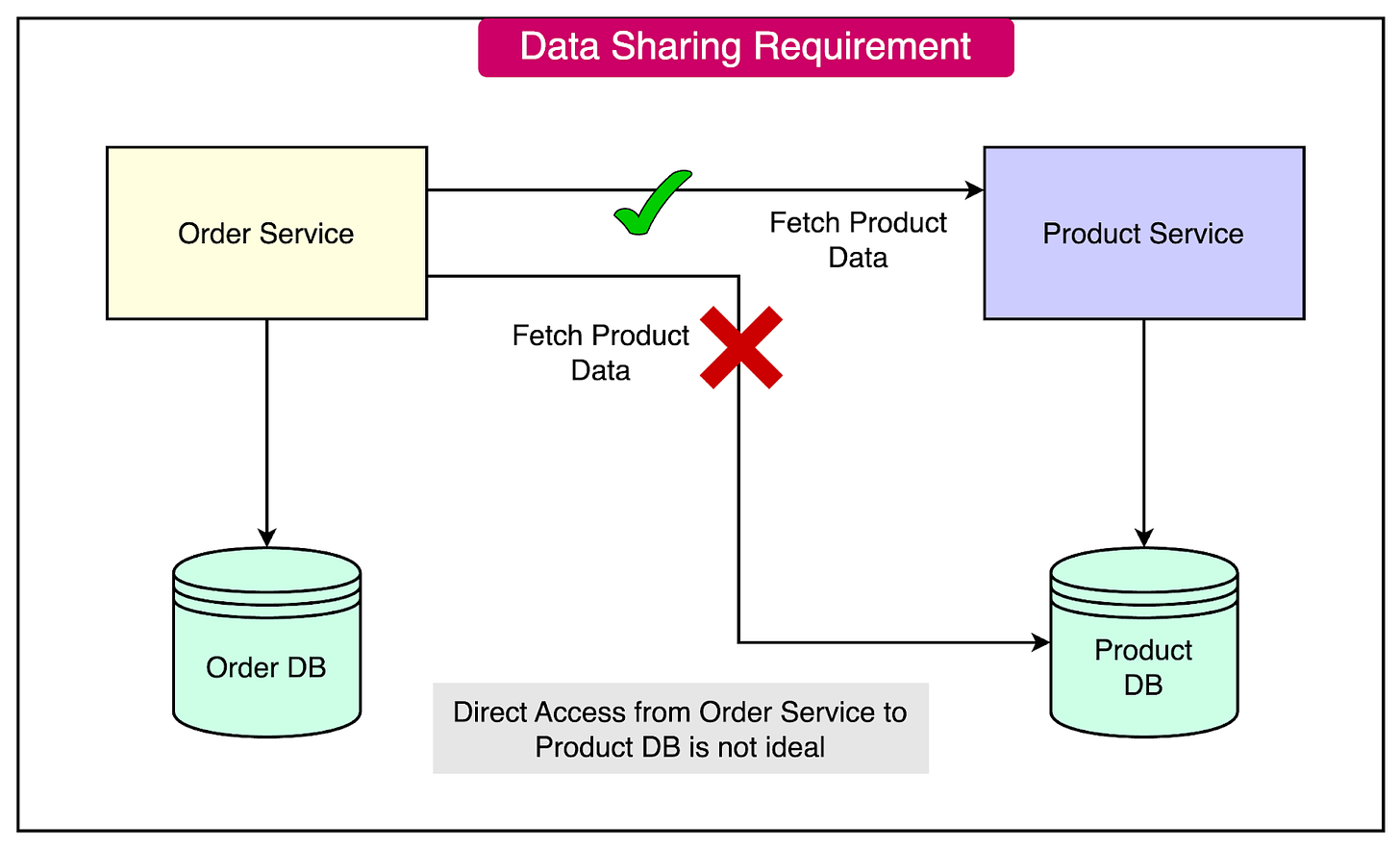
This scenario highlights the need for effective data-sharing strategies in microservices:
- Data Independence: Each service owns its data, preventing direct database access between services.
- Data Retrieval: The Order service must find a way to retrieve product information without violating service boundaries.
- Performance Considerations: The chosen data-sharing approach should not significantly impact system performance or introduce excessive latency.
- Consistency: Ensuring data consistency between services becomes crucial when sharing data across service boundaries.
Let us now look at different ways of sharing data.
Synchronous Data Sharing in Microservices
Synchronous data sharing in microservices involves real-time communication between services, where the requesting service waits for a response before proceeding. This approach ensures immediate consistency but introduces challenges in terms of scalability and performance.
Request/Response Model
The request/response model is the most straightforward synchronous approach:
- Service A sends a request to Service B for data.
- Service B processes the request and sends back a response.
- Service A waits for the response before continuing its operation.
For example, whenever the Order Service is called to provide order details (which includes product information), it has to fetch product data by calling the Product Service.
As expected, the synchronous data-sharing approaches face several challenges:
- Increased Response Time: Each synchronous call adds to the overall response time of the system.
- Cascading Failures: If one service is slow or down, it can affect the entire chain of dependent services.
- Resource Utilization: Services may need to keep connections open while waiting for responses, potentially leading to resource exhaustion.
- Network Congestion: As the number of inter-service calls increases, network traffic can become a bottleneck.
Due to these challenges, services can share data using duplication. For example, storing the product name with order details within the order table. This way the Order Service does not have to contact the Product Service to fetch the product’s name.
However, this creates consistency issues during data updates. For example, the product name is now duplicated across two different services. If the product name gets changed, the updates have to be done in both the product table and the order table to maintain consistency.
Note that this is just a simple example for explanation purposes. Even more critical consistency requirements can exist in a typical application.
The Gateway Approach
The Gateway approach is a simple approach to ensure data consistency while sharing data across multiple services.
Here’s an example scenario of how it can work:
- A coordinator that acts like a gateway initiates the update process.
- The coordinator sends update requests to all participating services.
- Each service performs the update and sends back a success or failure response.
- If all services succeed, the transaction is considered complete. If any service fails, the coordinator must initiate a rollback on all services.
See the diagram below where a possible change in the product name requires updates in the order service where a copy of the product name is shared. The coordinator ensures that both the updates are successful before informing the user.
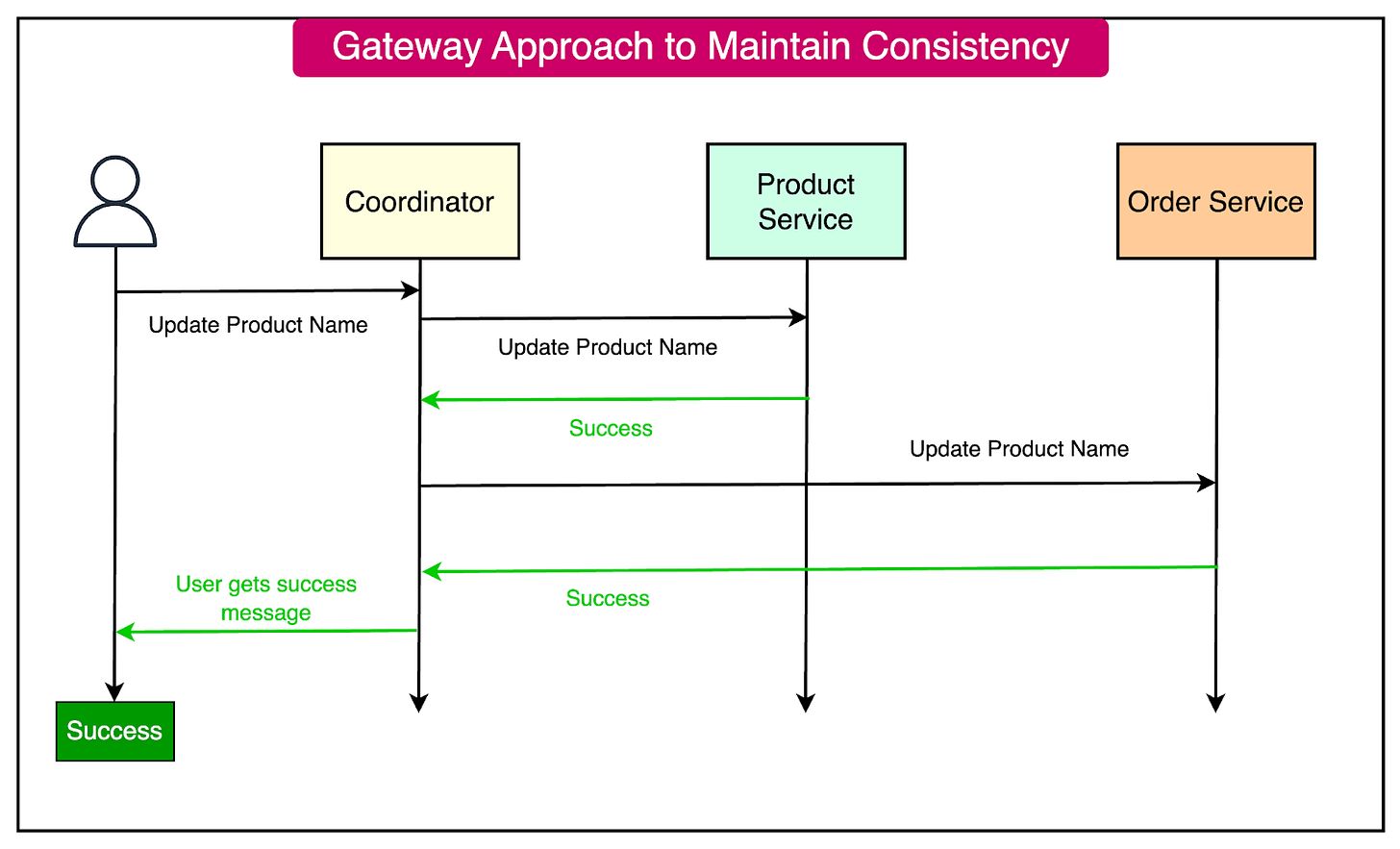
Some advantages of the gateway approach are as follows:
- Simpler to implement and reason about
- Maintains consistency
However, there are also disadvantages:
- Less reliable in failure scenarios.
- Poor experience for the users in case one of the services fails.
- Difficult to handle partial failures.
As evident, while synchronous approaches offer strong consistency and simplicity, they come with significant trade-offs in terms of scalability, performance, and resilience.
This is also the reason why asynchronous approaches are usually more popular.
Asynchronous Data Sharing in Microservices
Asynchronous data sharing in microservices architectures enables services to exchange data without waiting for immediate responses. This approach promotes service independence and enhances overall system scalability and resilience.
Let's explore the key components and concepts of asynchronous data sharing.
Event-Driven Architecture
In an event-driven architecture, services communicate through events:
- When a service performs an action or experiences a state change, it publishes an event to a message broker.
- Other services interested in that event can subscribe to it and react accordingly.
- This loosely coupled approach allows services to evolve independently.
The example below describes such an event-driven approach
- The Order Service publishes an “OrderCreated” event when a new order is placed.
- The Inventory Service subscribes to the “OrderCreated” event and updates stock levels.
- The Shipping Service also subscribes to the event and initiates the shipping process.
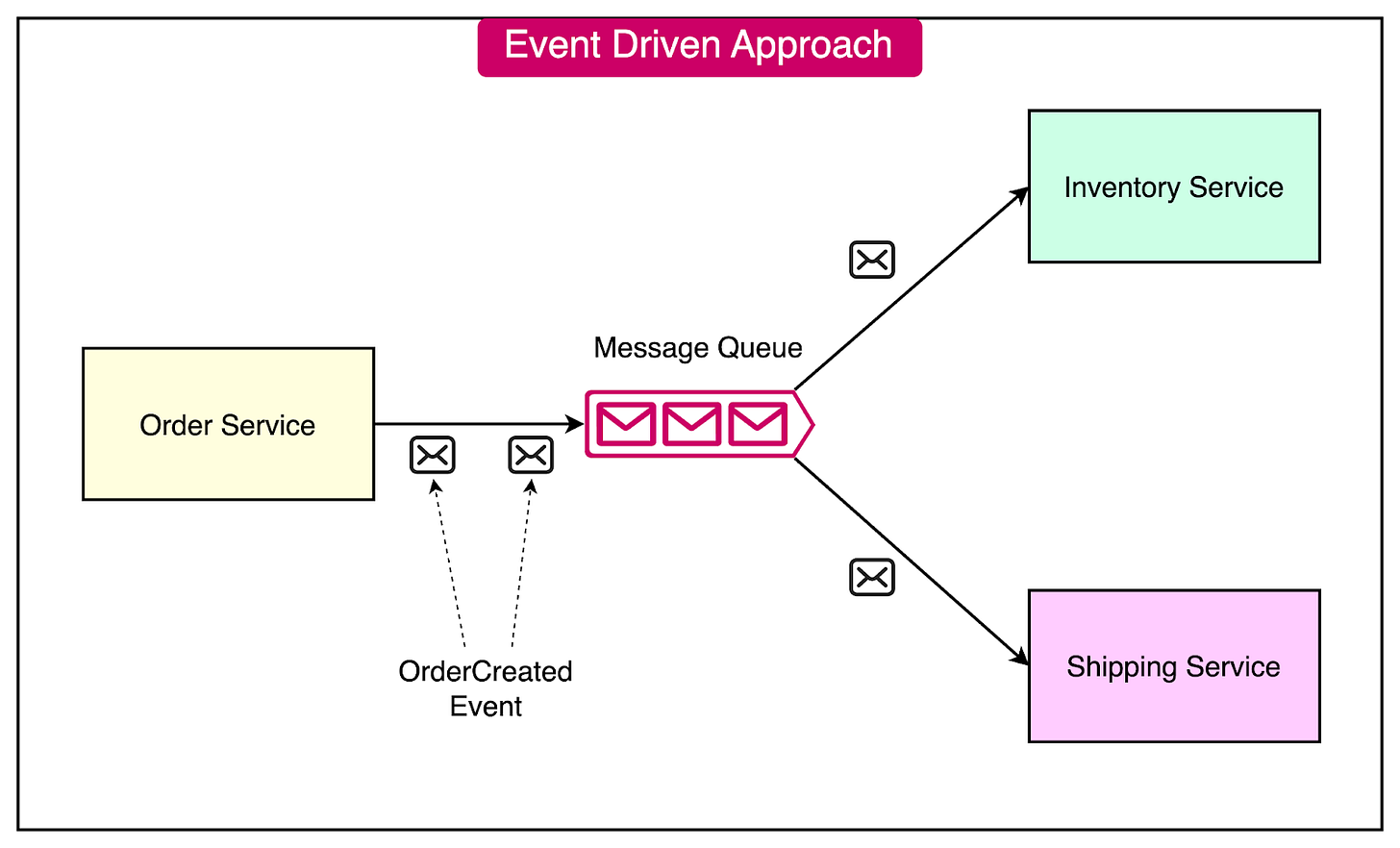
### Message Queues
Message queues, such as RabbitMQ, serve as the backbone of asynchronous communication in microservices: * They provide a reliable and scalable way to exchange messages between services. * Services can publish messages to specific topics or queues. * Other services can consume those messages at their own pace.
### Eventual Consistency
Asynchronous data sharing often leads to eventual consistency.
Services maintain their local copies of data and update them based on received events. It means that data across services may be temporarily inconsistent but will eventually reach a consistent state.
This approach allows services to operate independently and improves performance by reducing synchronous communication.
Here’s an example of the impact of eventual consistency on the earlier example about data sharing between Product and Order Service: * The Product Service maintains a local copy of the product data. * When a product’s details (such as name) are updated, the Product Service publishes a “ProductUpdated” event. * The Order Service consume the event and updates their local copies of the product data asynchronously. * There may be a short period where product data is inconsistent across services, but it will eventually become consistent.
See the diagram below:
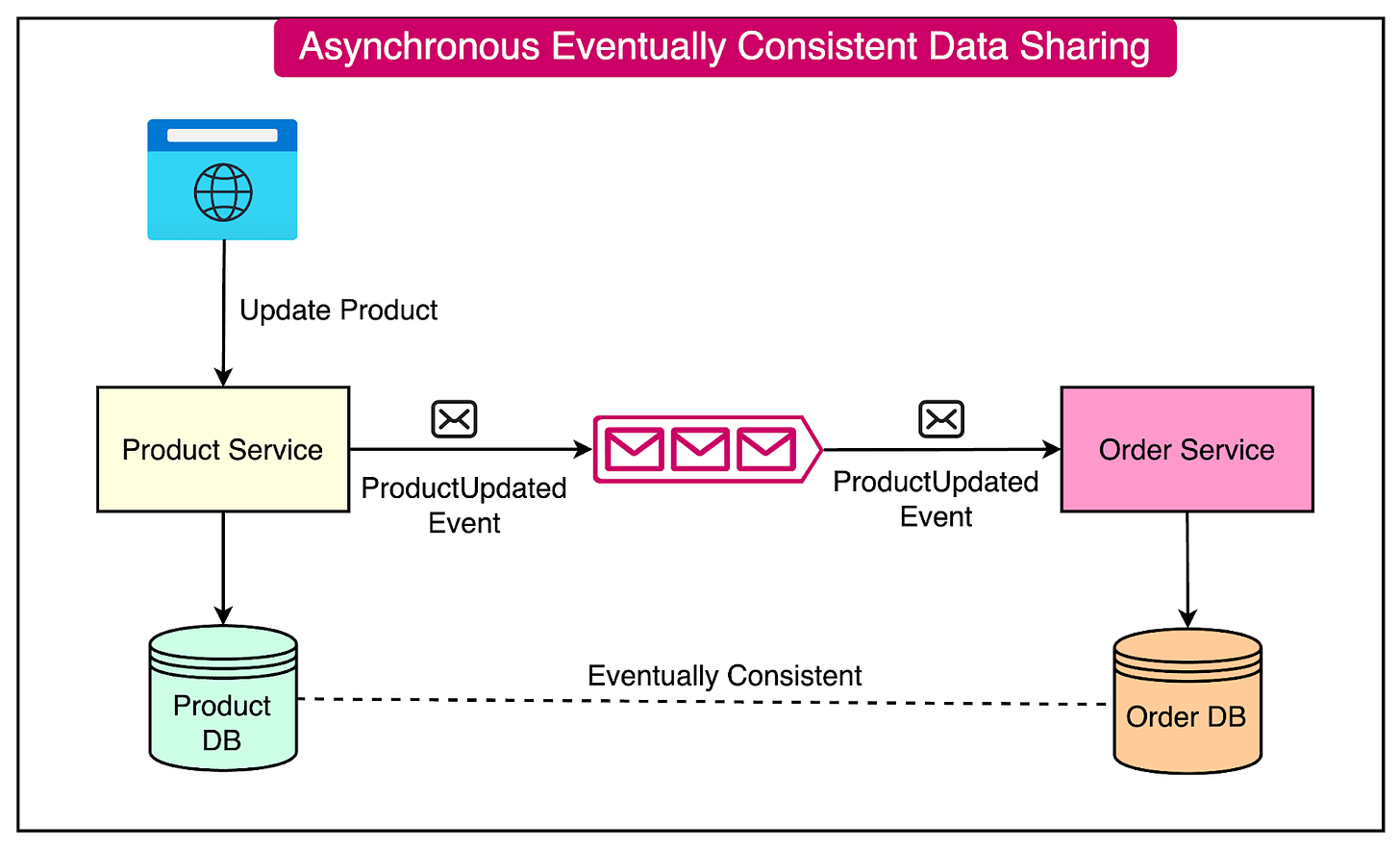
The advantages of asynchronous data sharing are as follows: * Loose Coupling: Services can evolve independently without tight dependencies on each other. * Scalability: Services can process messages at their own pace, allowing for better scalability and resource utilization. * Resilience: If a service is temporarily unavailable, messages can be buffered in the queue and processed later, improving system resilience. * Improved Performance: Asynchronous communication reduces the need for synchronous requests, resulting in faster response times and improved overall performance.
However, there are also some disadvantages: * Eventual Consistency: Data may be temporarily inconsistent across services, which can be challenging to handle in certain scenarios. * Increased Complexity: Implementing event-driven architectures and handling message queues adds complexity to the system. * Message Ordering: Ensuring the correct order of message processing can be challenging, especially in scenarios where message ordering is critical. * Error Handling: Dealing with failures and errors in asynchronous communication requires careful design and implementation of retry mechanisms and compensating actions.
## Hybrid Approach
A hybrid approach to data sharing in microservices combines elements of both synchronous and asynchronous methods. This approach aims to balance the benefits of local data availability with the need for up-to-date and detailed information from other services.
Let's consider a ride-sharing application with two microservices: Driver and Ride. * The Ride service stores basic driver information (ID, name) locally. * For detailed information (e.g., driver rating, car details), the Ride service makes a synchronous call to the Driver service.
This hybrid approach allows the Ride service to have quick access to essential driver data while still retrieving more comprehensive information when needed.
See the diagram below:
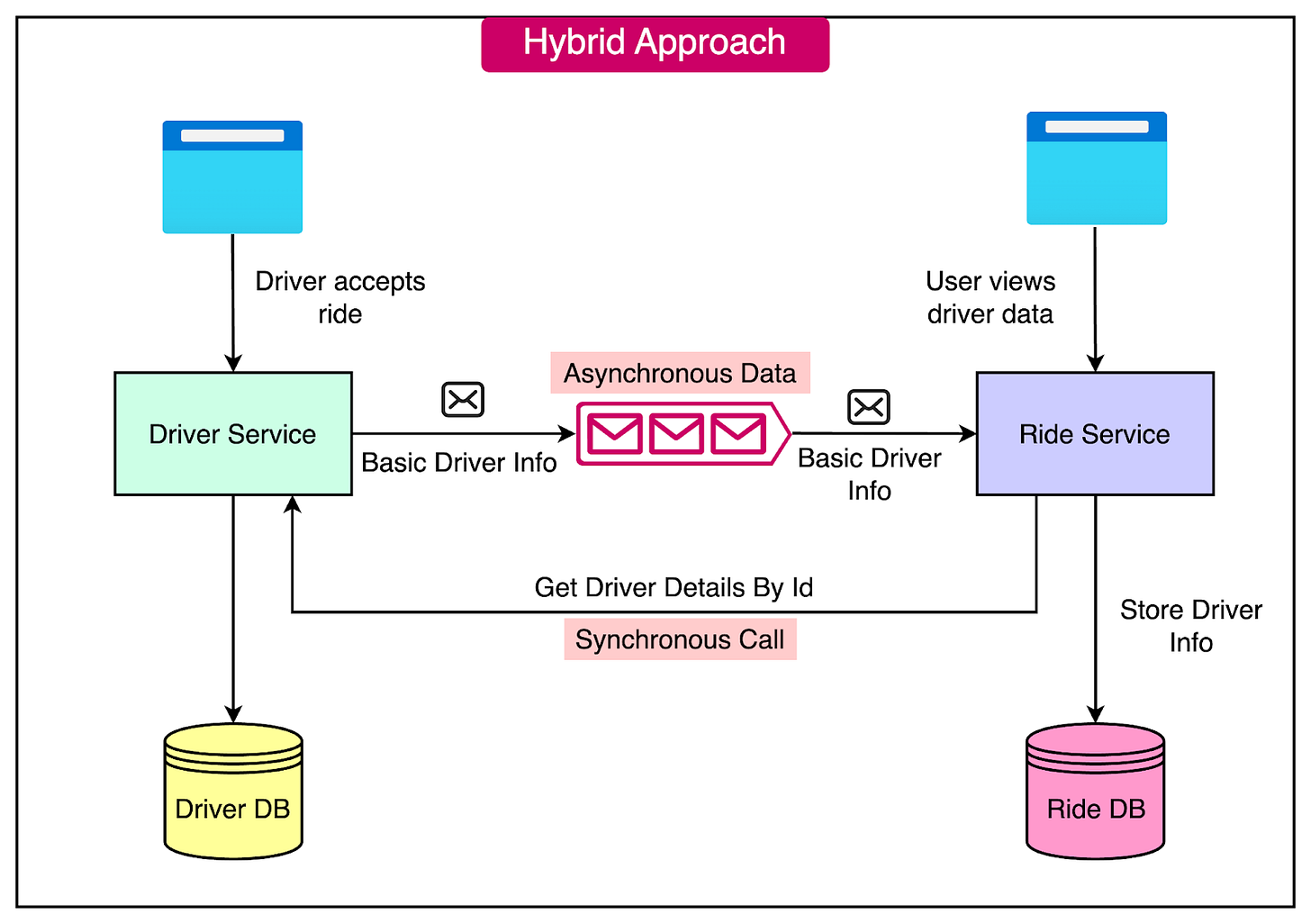
The hybrid approach offers a couple of benefits such as: * Reduces Redundant Calls: By storing basic information locally, the Ride service can reduce the frequency of service-to-service calls. This improves performance and minimizes the load on the network. * Smaller Database Footprint: Only essential data is duplicated across services, resulting in a smaller database footprint. This saves storage space and reduces the overhead of managing redundant data.
However, it also has some drawbacks: * Still Affects Response Time: Although basic information is available locally, retrieving detailed information through synchronous calls to the Driver service still impacts the overall response time of the Ride service. * Some Data Duplication: Even though only essential data is duplicated, there is still some level of data duplication across services. This requires careful management to ensure data consistency and avoid discrepancies.
When implementing a hybrid approach, consider the following: * Data Consistency: Ensure that the duplicated data remains consistent across services. Implement mechanisms to update the local copy of data when changes occur in the source service. * Caching Strategies: Employ caching strategies to store frequently accessed detailed information locally, reducing the need for repetitive synchronous calls to other services. * Asynchronous Updates: Consider using asynchronous methods, such as event-driven architecture or message queues, to propagate updates to the duplicated data asynchronously, minimizing the impact on response times.
## Trade-offs and Decision Making
When designing a microservices architecture that involves data sharing, it's crucial to carefully evaluate the trade-offs between consistency, performance, and scalability.
This decision-making process requires a deep understanding of your system's requirements and constraints.
### 1 – Evaluating Consistency Requirements
One of the key factors in choosing an appropriate solution is the consistency requirement.
#### Strong Consistency
Strong consistency ensures that all services have the most up-to-date data at all times. It is suitable for systems where data accuracy is critical, such as financial transactions or medical records.
The main characteristics are as follows: * Often implemented using synchronous communication patterns like the gateway pattern or request-response approach. * Ensures immediate data consistency across all services. * Drawbacks include higher latency and reduced availability.
#### Eventual Consistency
Eventual consistency allows for temporary data inconsistencies but guarantees that data will become consistent over time. It is appropriate for systems that can tolerate temporary inconsistencies, such as social media posts or product reviews.
The primary characteristics of a system based on eventual consistency are as follows: * Implemented using asynchronous communication patterns like event-driven architecture. * Allows for faster response times and higher availability. * Requires careful design to handle conflict resolution and compensating transactions.
### 2 – Performance Considerations
The key performance-related considerations are as follows: * Latency * Strong consistency often leads to higher latency due to synchronous communication. * Eventual consistency can provide lower latency but may serve stale data. * Throughput * Eventual consistency generally allows for higher throughput as services can operate more independently. * Strong consistency may limit throughput due to the need for coordination between services. * Resource Utilization * Strong consistency may require more computational and network resources to maintain data integrity. * Eventual consistency can be more efficient in terms of resource usage but requires additional storage for local data copies.
### 3 – Scalability
The data-sharing solution has a significant impact on the application's scalability. Some of the key aspects are as follows: * Horizontal Scaling: Eventual consistency models often scale better horizontally as services can be added without significantly impacting overall system performance. Strong consistency models may face challenges in horizontal scaling due to increased coordination overhead. * Data Volume: As data volume grows, maintaining strong consistency across all services becomes challenging. Eventual consistency can handle large data volumes more gracefully but requires careful management of data synchronization. * Service Independency: Eventual consistency allows services to evolve more independently, facilitating easier scaling. Strong consistency models create tighter coupling between services.
## Summary
In this article, we’ve taken a detailed look at the important topic of sharing data between microservices. This is a critical requirement when it comes to building robust and high-performance microservices.
Let’s summarize the key learnings: * The principle of each service owning its data aims to ensure loose coupling and autonomy among services, allowing them to evolve independently. * However, it's crucial to distinguish between sharing a data source and sharing data itself. * Synchronous data sharing in microservices involves real-time communication between services, where the requesting service waits for a response before proceeding. * Some approaches for synchronous data sharing are the request/response model and the gateway approach * Asynchronous data sharing in microservices architectures enables services to exchange data without waiting for immediate responses. * The key components of the asynchronous data-sharing approach are event-driven architecture, message queues, and the concept of eventual consistency. * A hybrid approach to data sharing in microservices combines elements of both synchronous and asynchronous methods. This approach aims to balance the benefits of local data availability with the need for up-to-date and detailed information from other services. * Multiple trade-offs need to be taken into consideration while choosing the appropriate data-sharing approach. Some key factors are consistency requirements, performance needs, and the desired scalability of the application.