Kenny Yip: Excellent Programmer
I recently came across a developer by the name Kenny Yip who generously provides tutorials focused on Java, Python, C++ and more. Two main links of his to please check out:
https://www.youtube.com/@KennyYipCoding
https://www.kennyyipcoding.com/
Kenny’s content is great; he is popular and does an excellent job of educating, encouraging and embracing those on the path of learning software development. Regardless of which stage you’re at on the journey of coding and creating IT solutions, Kenny has a spirit which can lift you up a step from either beginner-to-intermediate, or give you an enjoyable refreshing reminder of your hard-earned advanced—technical-chops.
The world is your Yippee-ki-yay, mothercrusher!
#kenny-yip #kennyyipcoding #java #python #c++

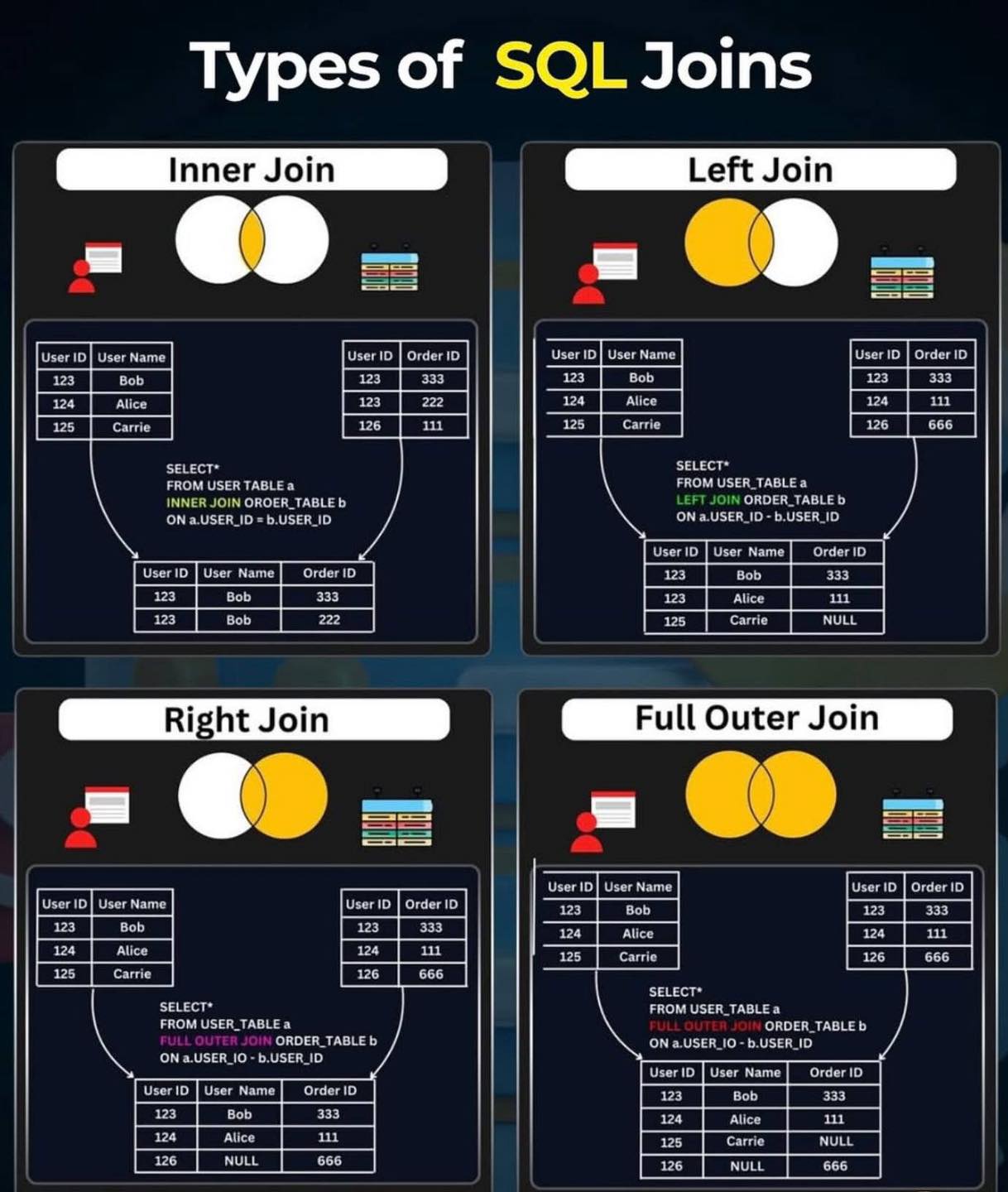
Python List Methods
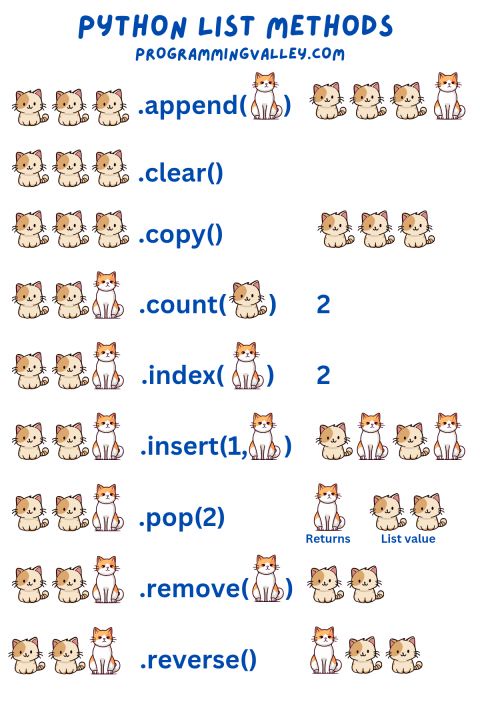
Lists are everywhere—data, APIs, ML, automation… And mastering their methods makes your code 10x better.
Here are the essentials:
🔹 append() → Add item to the end
🔹 clear() → Remove all items
🔹 copy() → Create a shallow copy
🔹 count(x) → Count occurrences of a value
🔹 index(x) → Find position of a value
🔹 insert(i, x) → Add item at a specific position
🔹 pop(i) → Remove & return item by index
🔹 remove(x) → Remove first matching value
🔹 reverse() → Reverse the list
💡 Pro insight: Lists are not just data structures… They’re the foundation of how Python handles collections.
10 Must-Know Array Patterns

Back-End Tech Stack
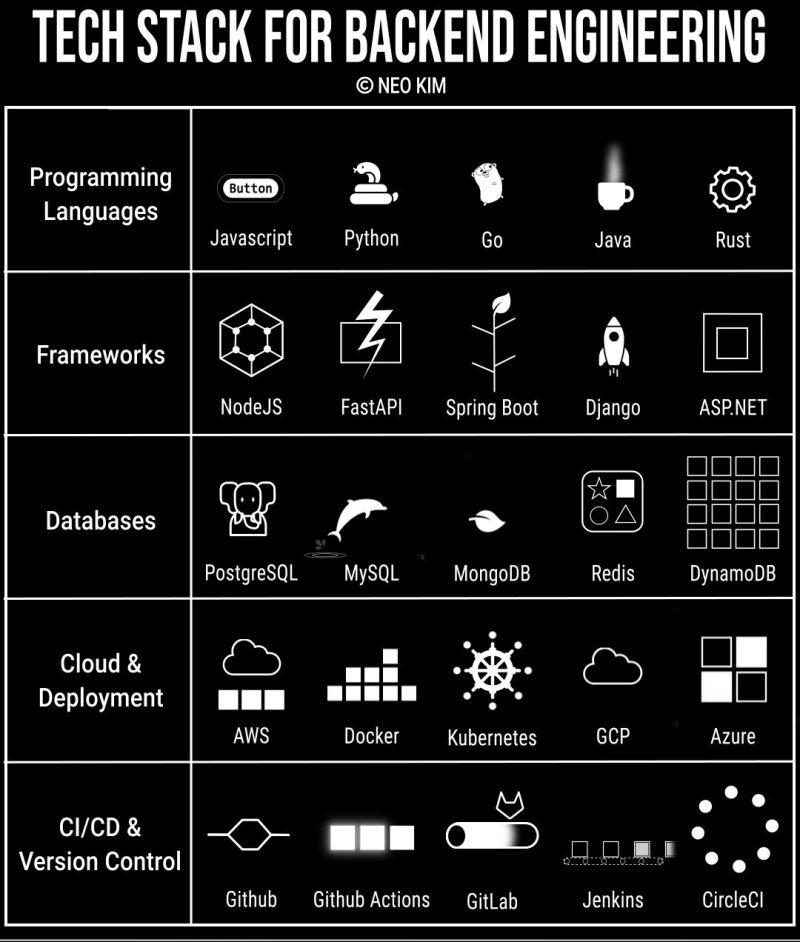
#back-end #tech-stack #programming #ci-cd #databases #cloud
Here are 5 best Tech Stack & Resources
A strong backend foundation often includes:
Node.js— for scalable server-side applications
PostgreSQL / MongoDB— for structured and flexible data handling
Redis— for caching and performance optimization
RabbitMQ —for event-driven communication
AWS— for scalable infrastructure.
- Focus on real-world system design case studies. Study how large-scale systems handle traffic and failures
- Build small projects that simulate real-world load
- Backend engineering is not just about making systems work.It is about making sure they continue to work as usage grows and complexity increases.
- The difference between a stable system and a failing one often comes down to early design decisions.
- If you are building or scaling backend systems, or looking to improve your system design approach let's discuss share your challenges.
- Let’s build systems that are designed to last.
20 Must-Know Concurrency Concepts
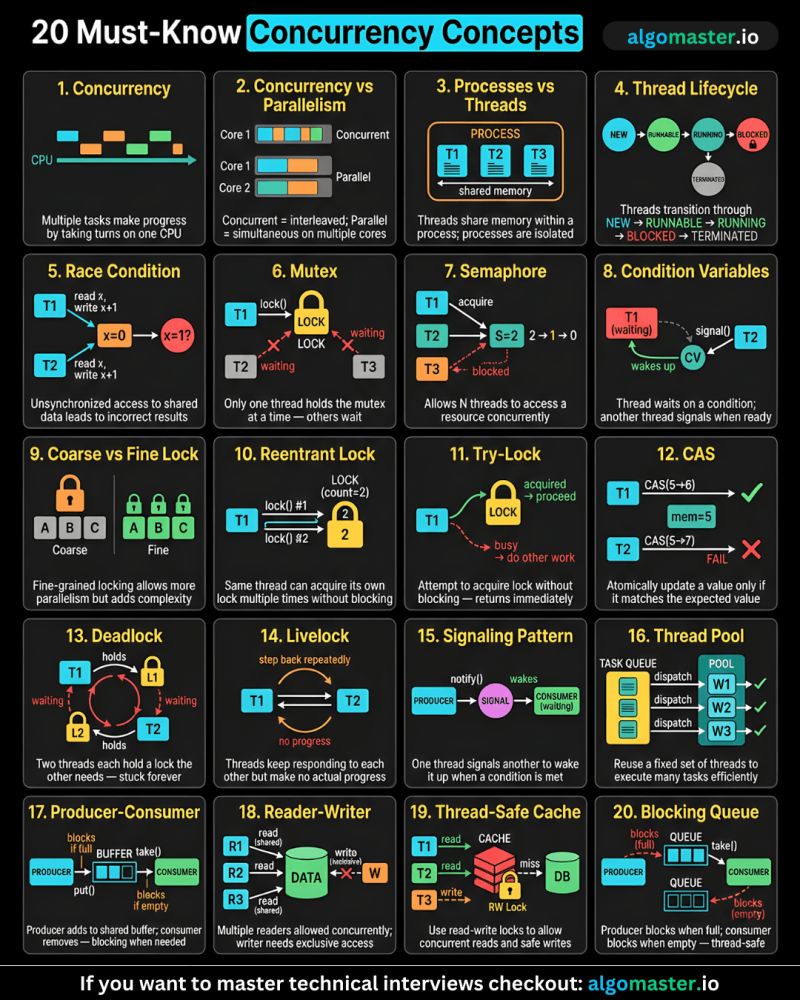
#concurrency #threads #thread-safe #queue #locks
1. Concurrency Overview: https://lnkd.in/gbXNtx8i 2. Concurrency vs Parallelism: https://lnkd.in/ggm3zxKi 3. Processes vs Threads: https://lnkd.in/gjD7BE9D 4. Thread Lifecycle: https://lnkd.in/gnraugyb 5. Race Conditions: https://lnkd.in/gJBaBWa5 6. Mutex: https://lnkd.in/gU-6SvJh 7. Semaphores: https://lnkd.in/gpcMAvvC 8. Condition Variables: https://lnkd.in/gzD3RdWy 9. Coarse-grained vs Fine-grained Locking: https://lnkd.in/giHCvjbK 10. Reentrant Locks: https://lnkd.in/gjjtEZrm 11. Try-Lock: https://lnkd.in/gc9Frvik 12. Compare-and-Swap (CAS): https://lnkd.in/gzzvSW_W 13. Deadlock: https://lnkd.in/gKtDZ9gD 14. Livelock: https://lnkd.in/g8UTb86c 15. Signaling Pattern: https://lnkd.in/gg8RxZBf 16. Thread Pool Pattern: https://lnkd.in/g52TJUT3 17. Producer-Consumer Pattern: https://lnkd.in/g9P_Rh-6 18. Reader-Writer Pattern: https://lnkd.in/geAvZkRy 19. Thread-Safe Cache: https://lnkd.in/gPW9JnkH 20. Thread-Safe Blocking Queue: https://lnkd.in/gtKrDJiE
Top 6 API Architectural Styles
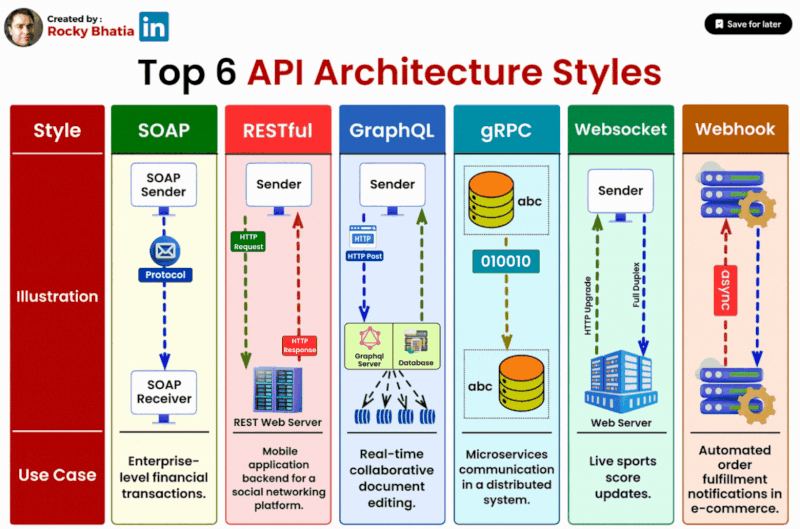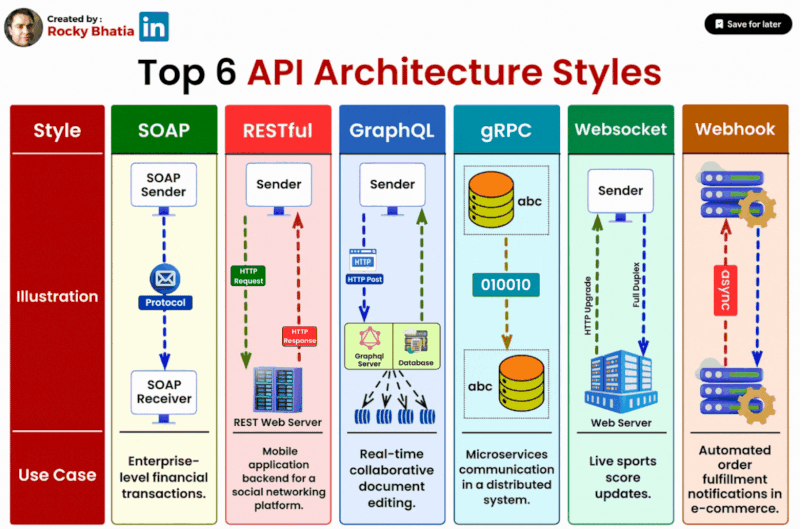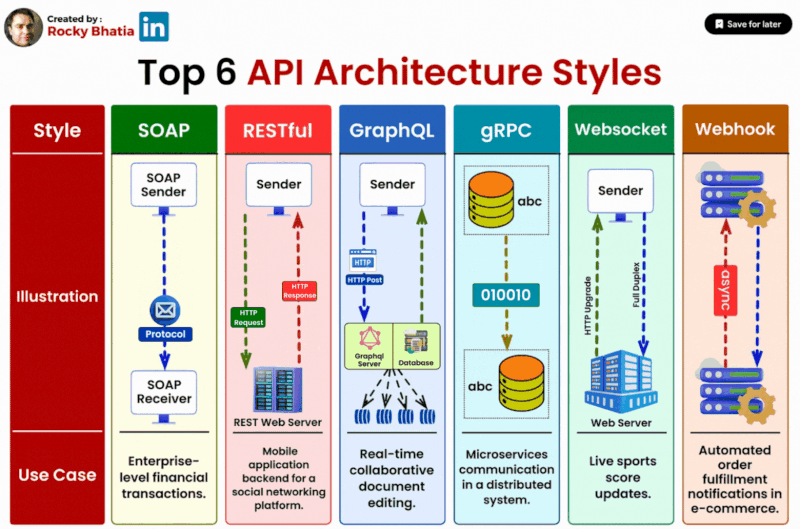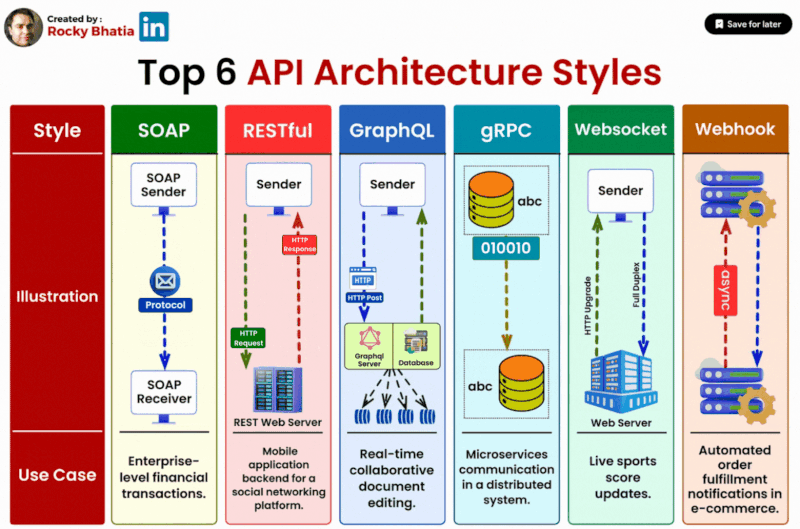
#api #systemarchitecture #soap #rest #graphql #grpc #websockets #webhooks
1️⃣ SOAP (Simple Object Access Protocol): SOAP is ideal for enterprise-level applications that require a standardized protocol for exchanging structured information. Its robust features include strong typing and advanced security mechanisms, making it suitable for complex and regulated environments.
2️⃣ RESTful (Representational State Transfer): RESTful APIs prioritize simplicity and scalability, making them well-suited for web services, particularly those catering to public-facing applications. With a stateless, resource-oriented design, RESTful APIs facilitate efficient communication between clients and servers.
3️⃣ GraphQL: GraphQL shines in scenarios where flexibility and client-driven data retrieval are paramount. By allowing clients to specify the exact data they need, GraphQL minimizes over-fetching and under-fetching, resulting in optimized performance and reduced network traffic.
4️⃣ gRPC: For high-performance, low-latency communication, gRPC emerges as the preferred choice. Widely adopted in microservices architectures, gRPC offers efficient data serialization and bi-directional streaming capabilities, making it suitable for real-time applications and distributed systems.
5️⃣ WebSockets: WebSockets excel in applications requiring real-time, bidirectional communication, such as chat platforms and online gaming. By establishing a persistent connection between clients and servers, WebSockets enable instant data updates and seamless interaction experiences.
6️⃣ Webhooks: In event-driven systems, webhooks play a vital role by allowing applications to react to specific events in real-time. Whether it's notifying about data updates or triggering actions based on user activities, webhooks facilitate seamless integration and automation.
Selecting the appropriate API style is crucial for optimising your application's performance and enhancing user experience. By understanding the strengths and use cases of each architecture style, you can make informed decisions that align with your project's specific requirements.
JVM (Java Virtual Machine) Explained
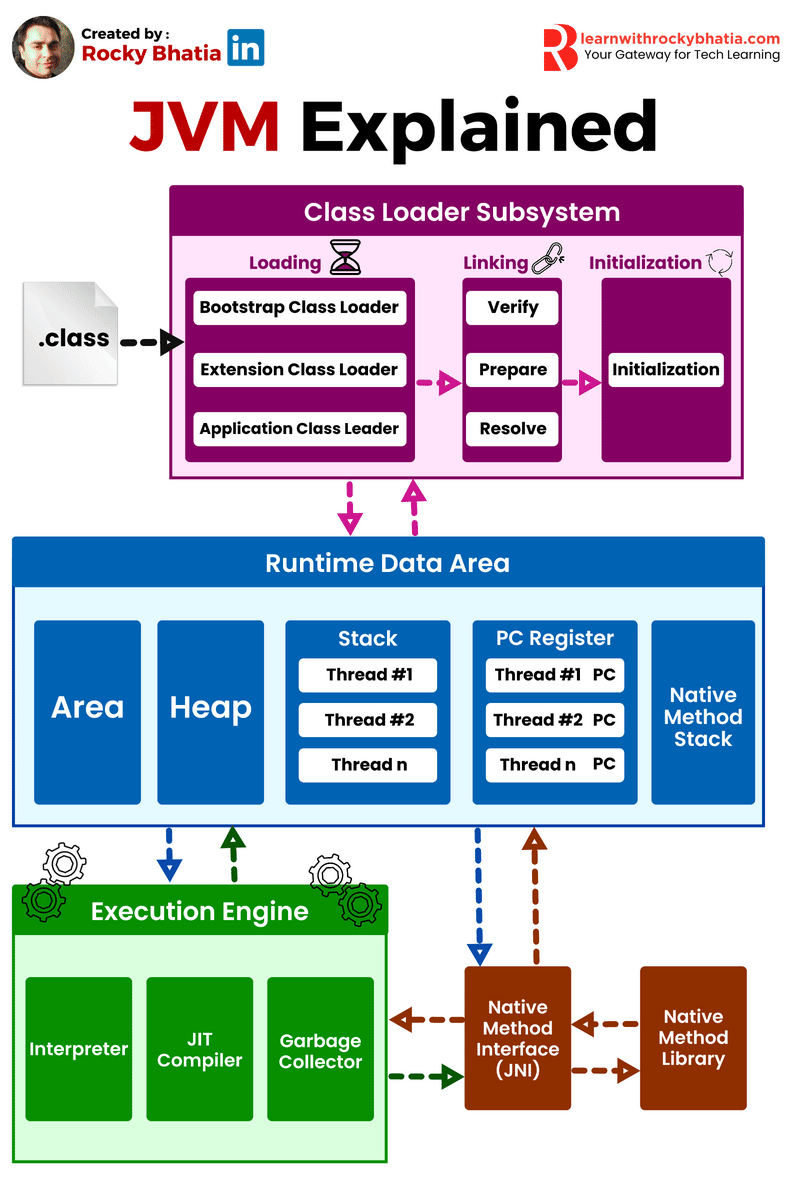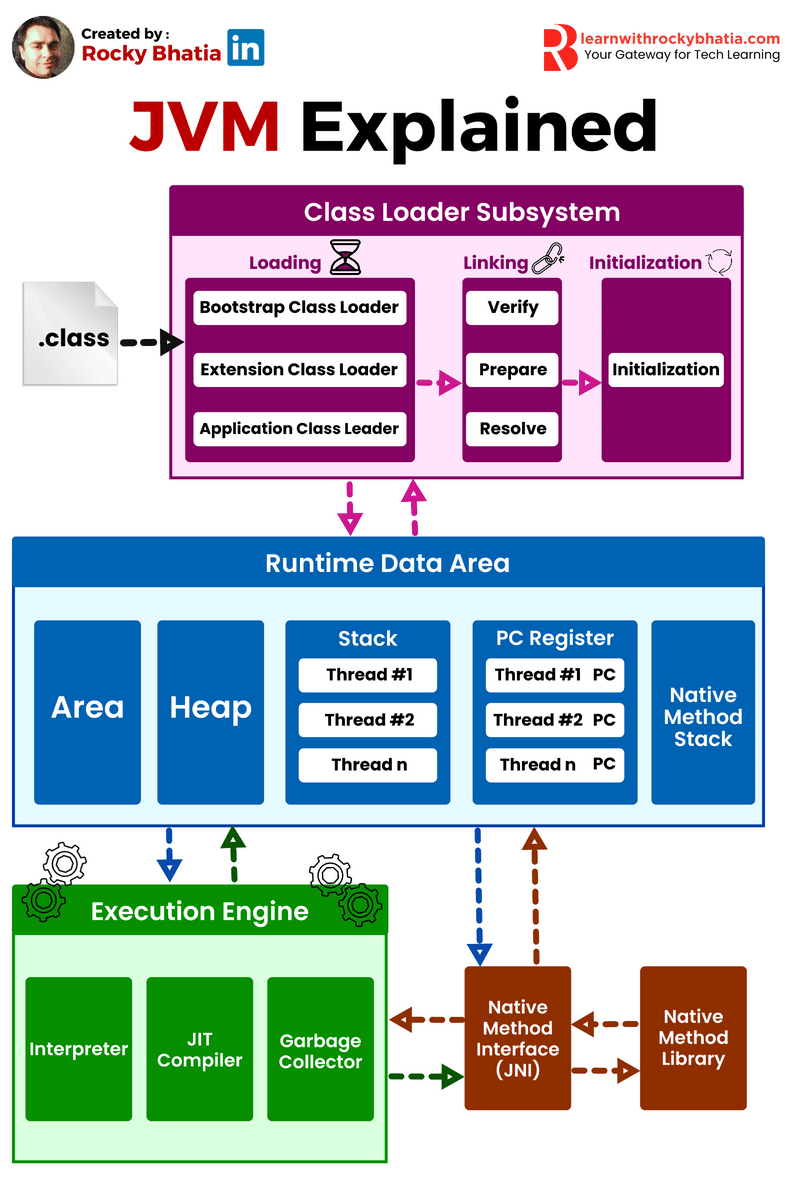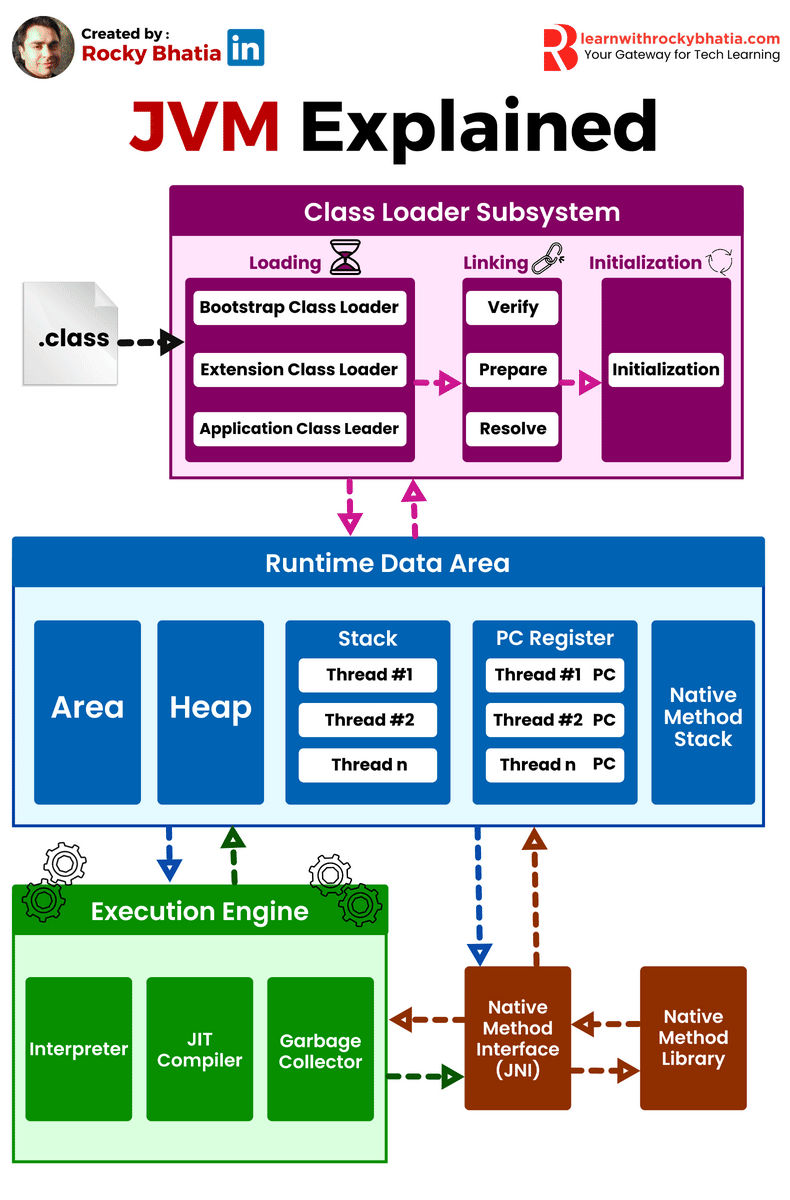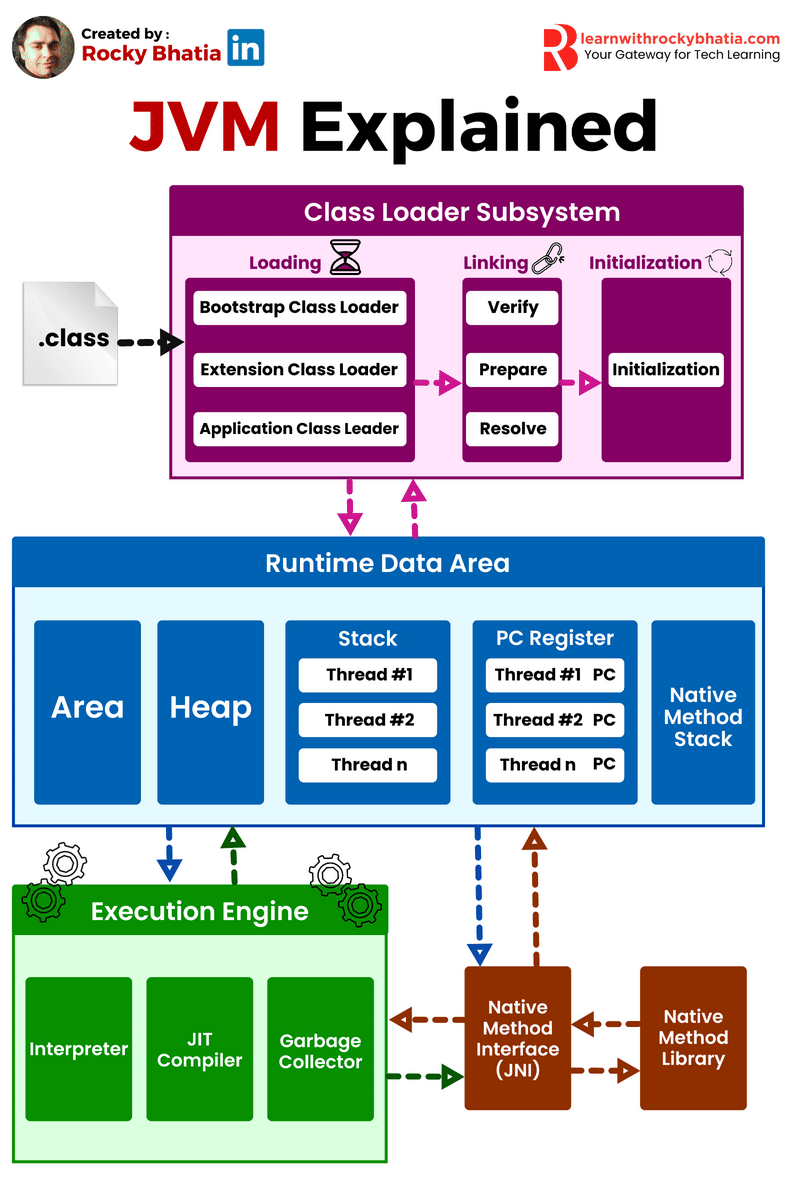
#java #jvm #virtulisation #stack #thread
𝐓𝐡𝐞 𝐏𝐨𝐰𝐞𝐫 𝐨𝐟 𝐉𝐚𝐯𝐚: 𝐀 𝐏𝐞𝐞𝐤 𝐈𝐧𝐬𝐢𝐝𝐞 𝐭𝐡𝐞 𝐉𝐕𝐌 𝐌𝐚𝐜𝐡𝐢𝐧𝐞
Ever wondered what makes Java so robust and platform-independent?
Let’s dive into the heart of Java – the Java Virtual Machine (JVM)
1. 📚 Class LoaderStarts the show by loading those .class files. It doesn't just load any code; it ensures the code is legit!
2. 🔍 Bytecode VerifierActs as the gatekeeper, checking the bytecode to make sure it plays by the rules – safe and secure before execution.
3. 🧠 Execution EngineThis is where the magic happens! It converts bytecode into native machine code. Whether it’s interpreting it line-by-line, or compiling it on the fly with Just-In-Time (JIT) compilation, it’s all about speed and efficiency
.4. 🗄️ Memory AreaJVM’s powerhouse! It manages various memory areas like the heap for object storage, stack for method execution tracks, and more to ensure smooth operation and GC (Garbage Collection) to clean up after the party
.5. 🎛️ Runtime Data AreasHere, JVM manages runtime data, method calls, and returns results. Like a well-oiled machine, it keeps everything running smoothly.
6. 🗂️ Native Interface & LibraryWhen JVM needs a break, it uses native methods. The Native Interface links Java to libraries written in languages like C or C++, expanding its capabilities beyond java
In essence, JVM is like a high-tech factory that turns Java bytecode into the action your device understands and executes. It’s why Java runs everywhere – from your toaster to data centers!
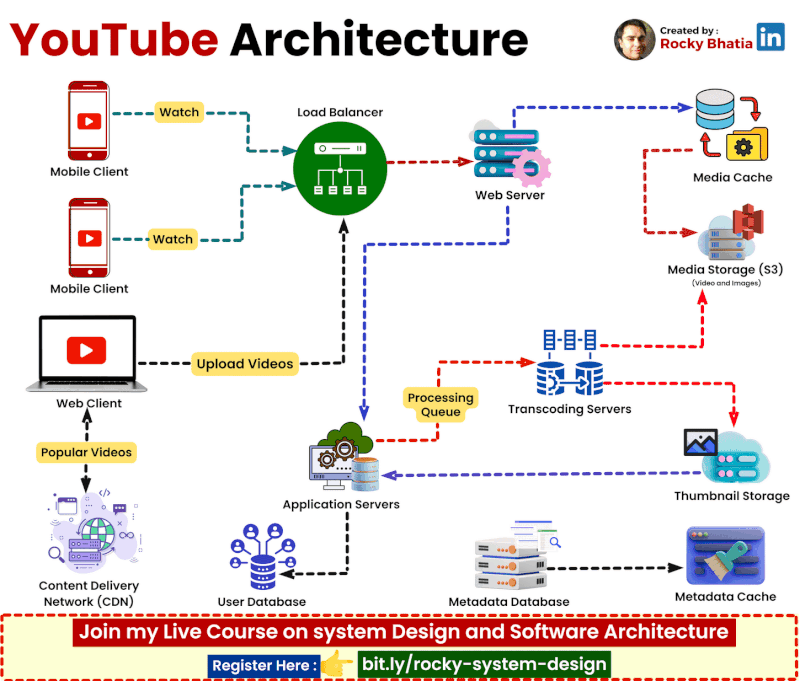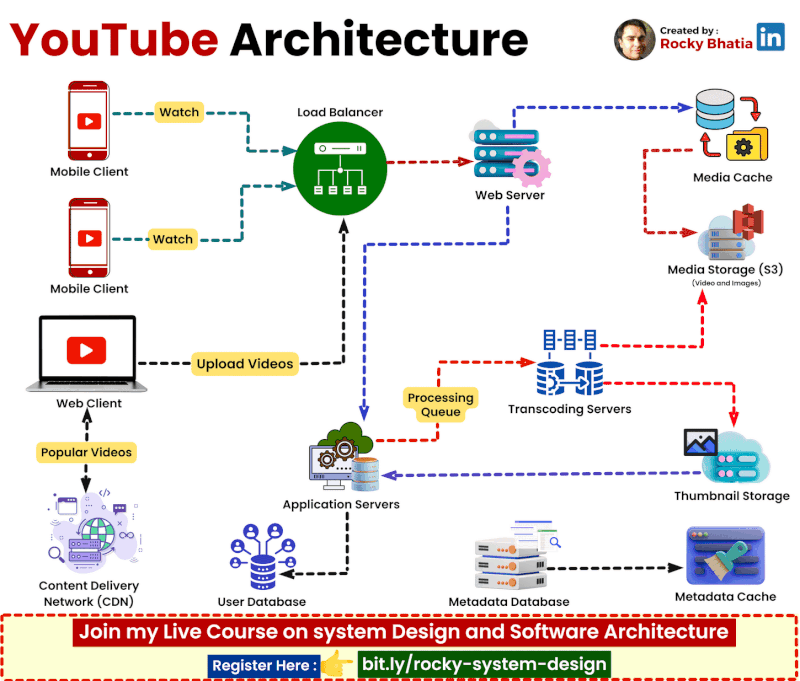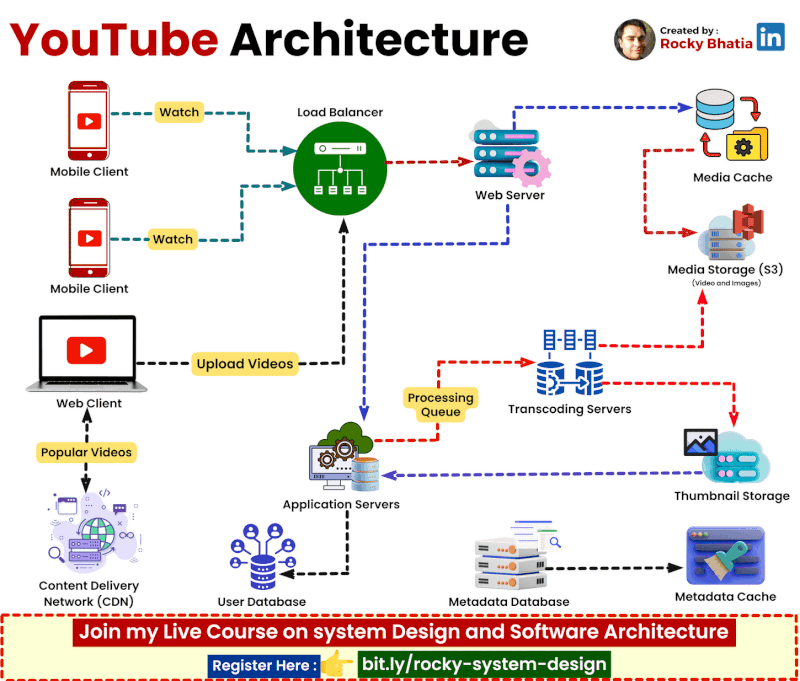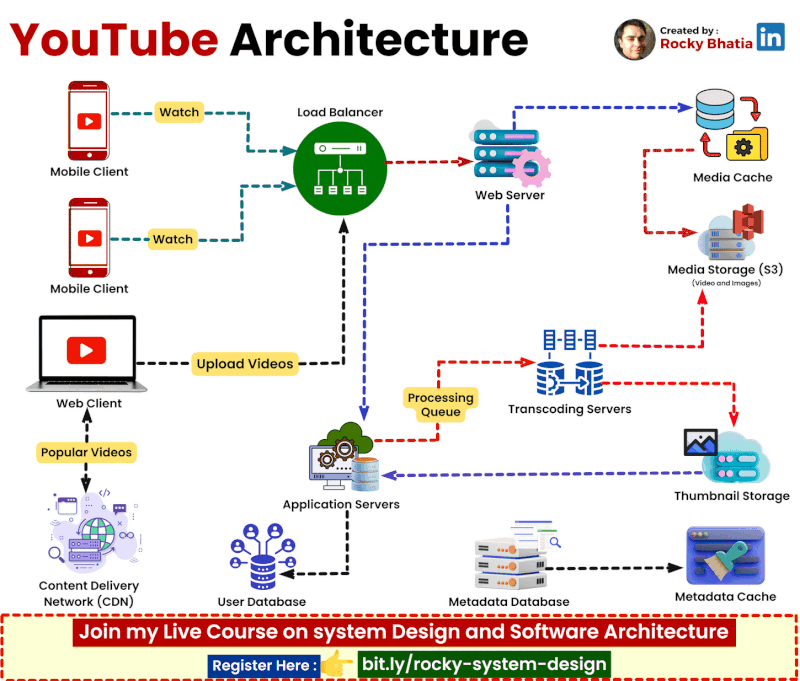
YouTube Architecture
1. Syntax and Data Types: – Basic syntax and structure of Java programs. – Primitive data types (int, float, boolean, etc.) and their usage. – Object-oriented programming (classes, objects, inheritance, polymorphism, etc.). – Control flow statements (if-else, loops, switch, etc.). ** 2. Java Libraries and APIs:** – Java Standard Library: Provides a wide range of classes and methods for common programming tasks, such as handling strings, input/output operations, collections, concurrency, and networking. – Java Development Kit (JDK): Includes tools for developing, debugging, and running Java applications, such as the Java Compiler (javac), Java Virtual Machine (JVM), and Java Runtime Environment (JRE). – Java Application Programming Interface (API): A collection of pre-written classes and interfaces that developers can use to build applications.
3. Exception Handling: – Handling and managing errors and exceptions that may occur during program execution. – Using try-catch blocks to catch and handle exceptions gracefully. – Throwing and creating custom exceptions. ** 4. Input/Output (I/O):** – Reading and writing data from/to different sources (files, streams, etc.). – Working with input and output streams, readers, and writers. – Serialization and deserialization of objects.
5. Multithreading and Concurrency: – Creating and managing multiple threads to achieve concurrent execution. – Synchronization and thread safety. – Inter-thread communication and synchronization mechanisms.
6. Collections Framework: – Built-in data structures (lists, sets, maps, queues, etc.) and algorithms for manipulating and storing collections of objects. – Iterating over collections and performing operations like sorting, searching, and filtering.
7. Java Database Connectivity (JDBC): – Connecting to databases and executing SQL queries. – Retrieving, updating, and manipulating data in relational databases.
Core Java serves as the foundation for Java development, providing the necessary tools and concepts to create robust,platform-independent applications across various domains, including web development, enterprise systems, mobile apps, and more.
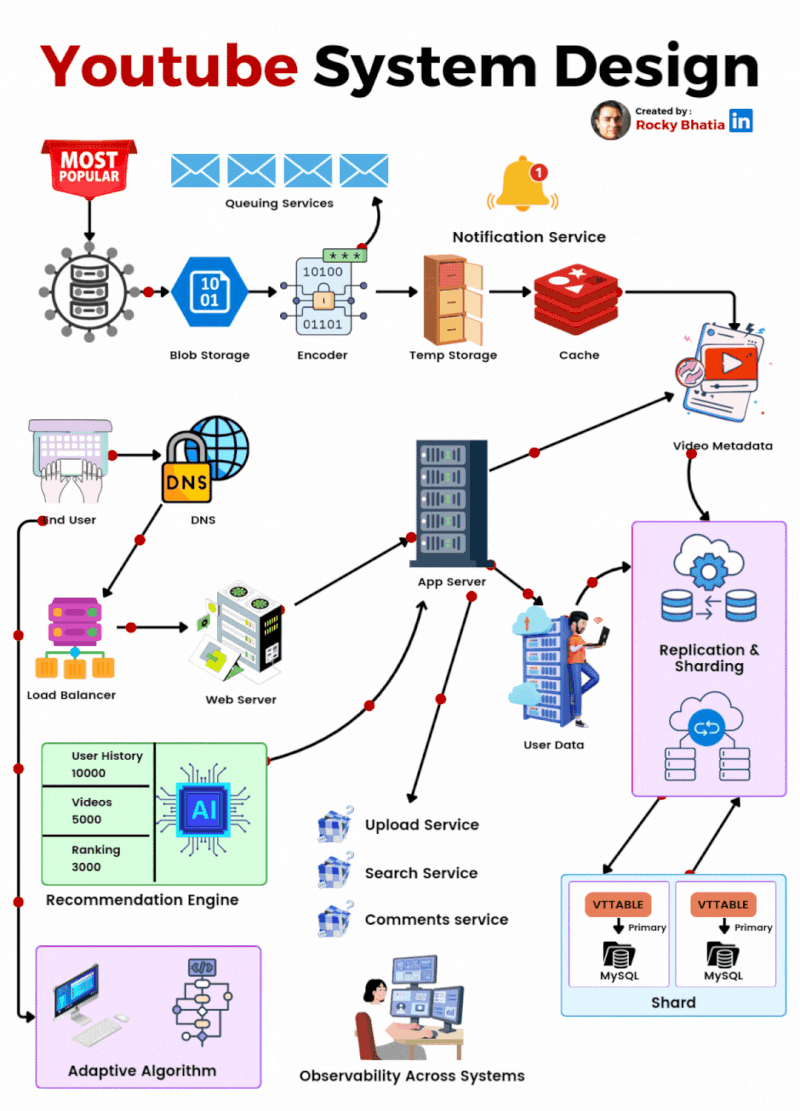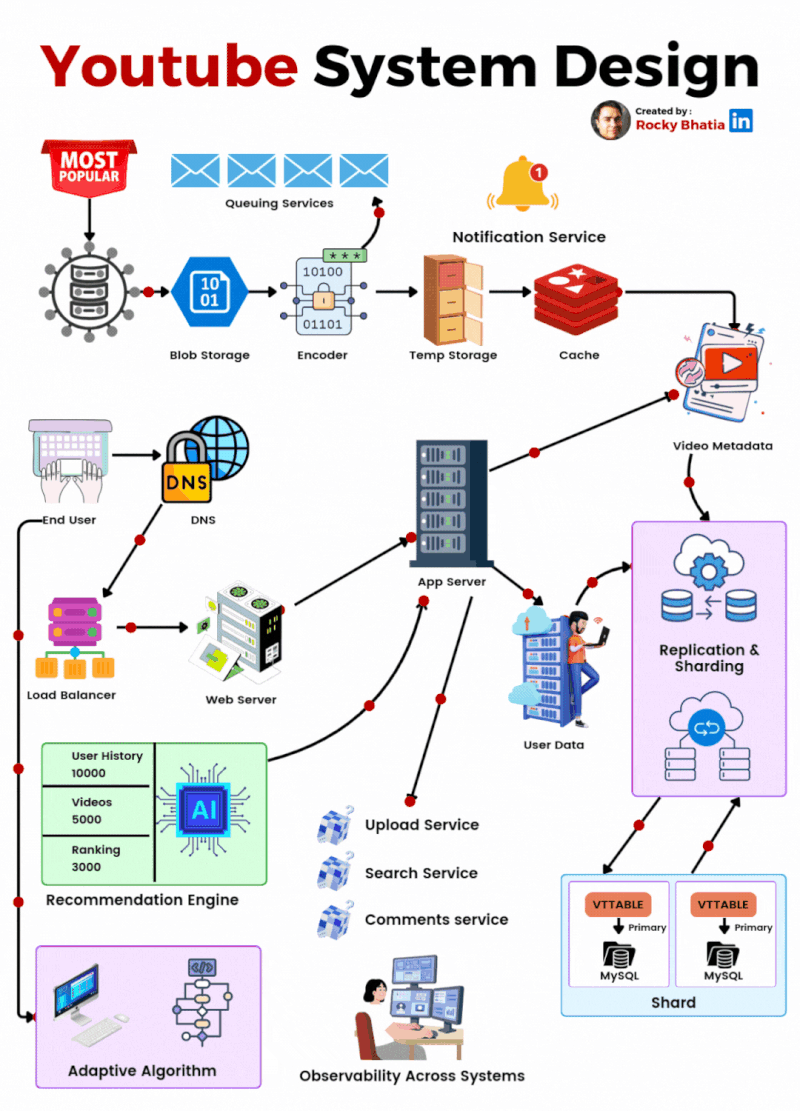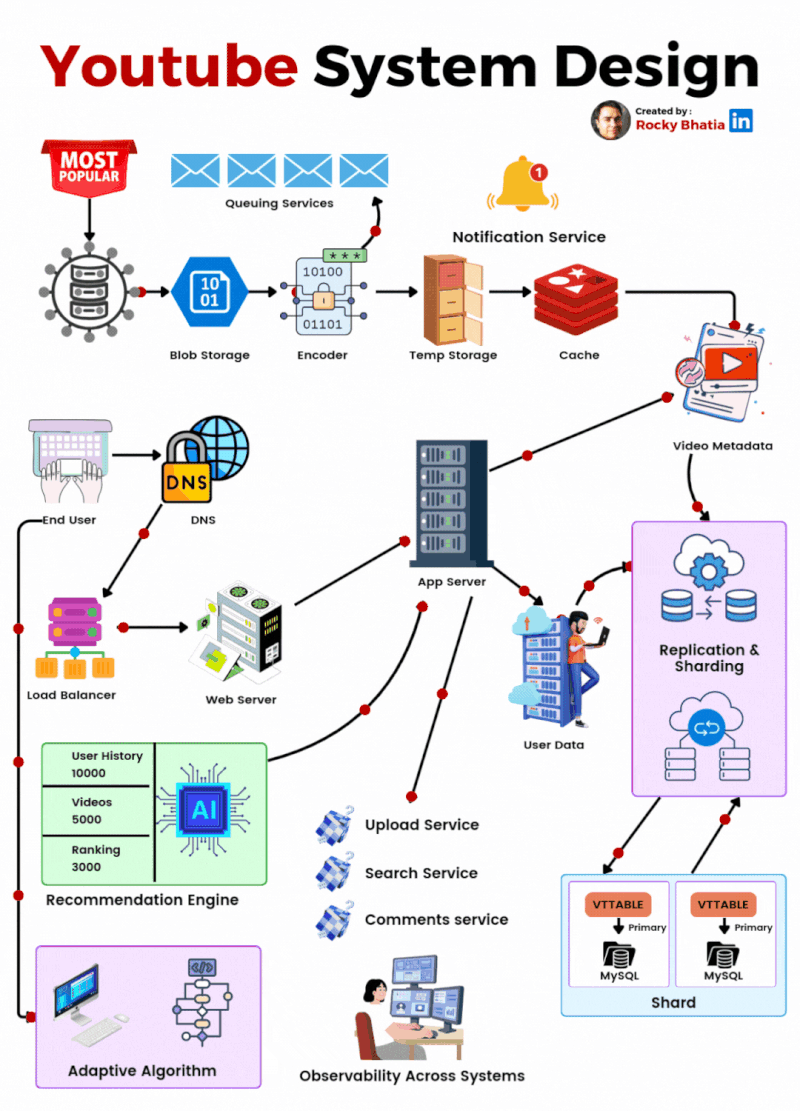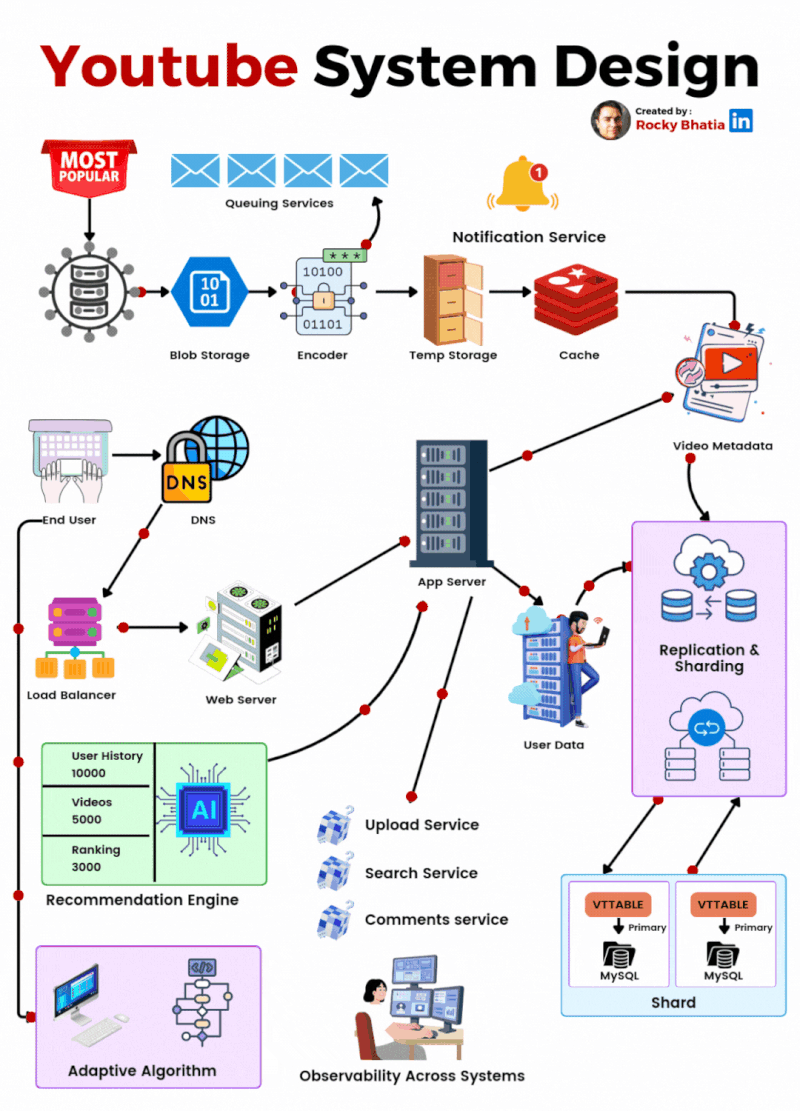
YouTube System Design
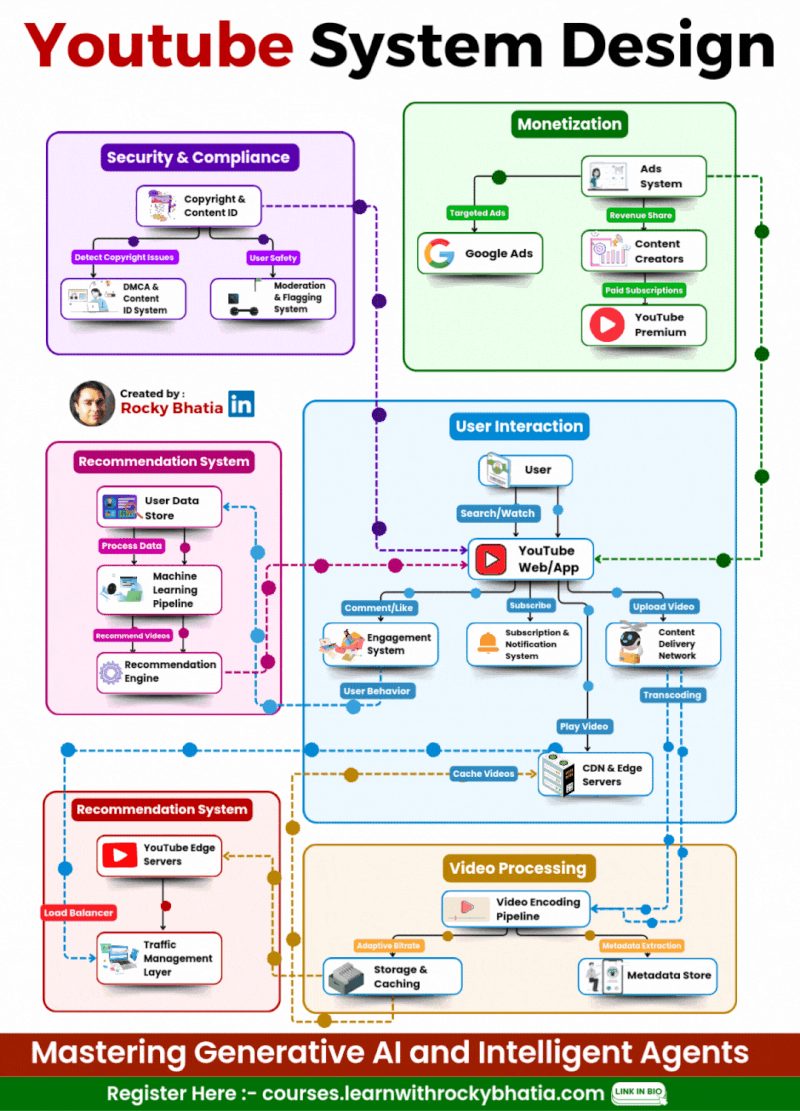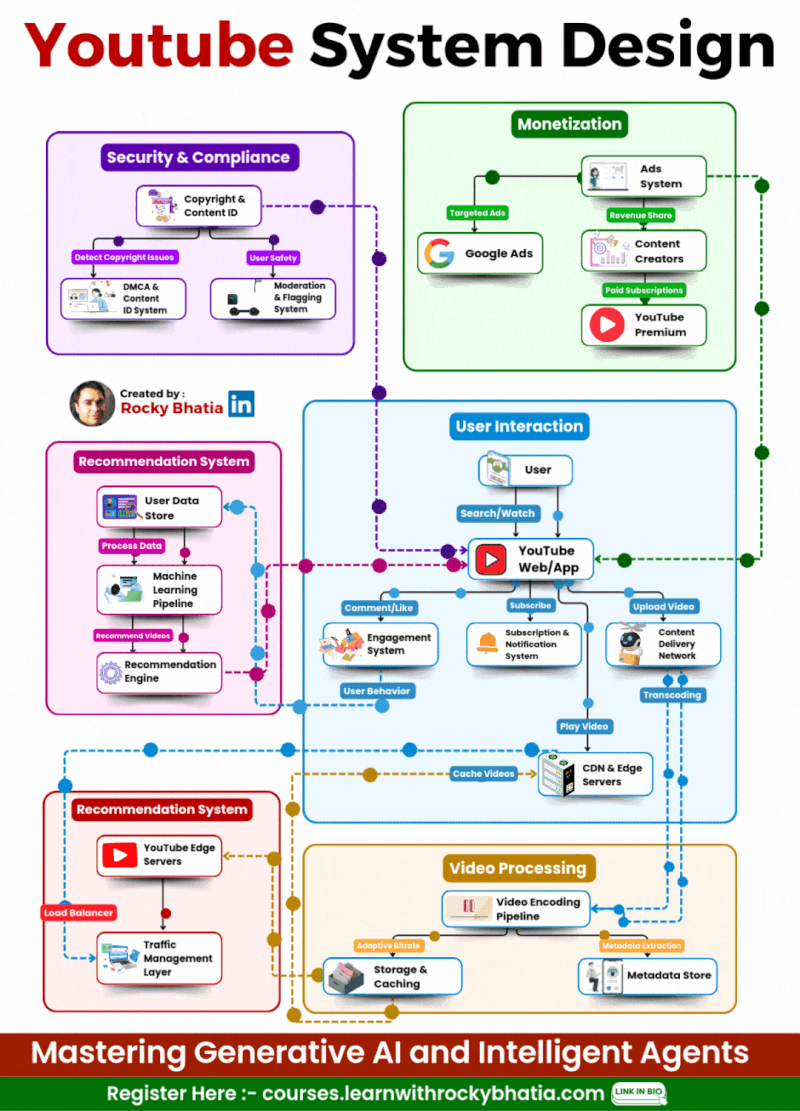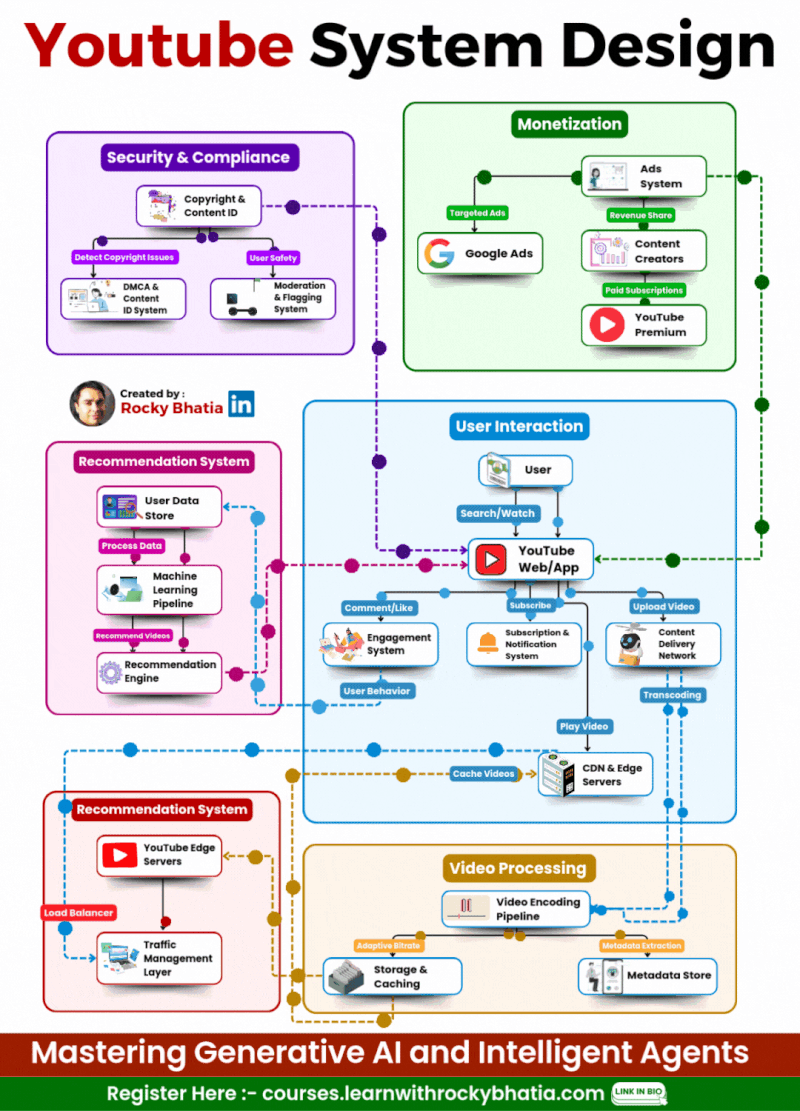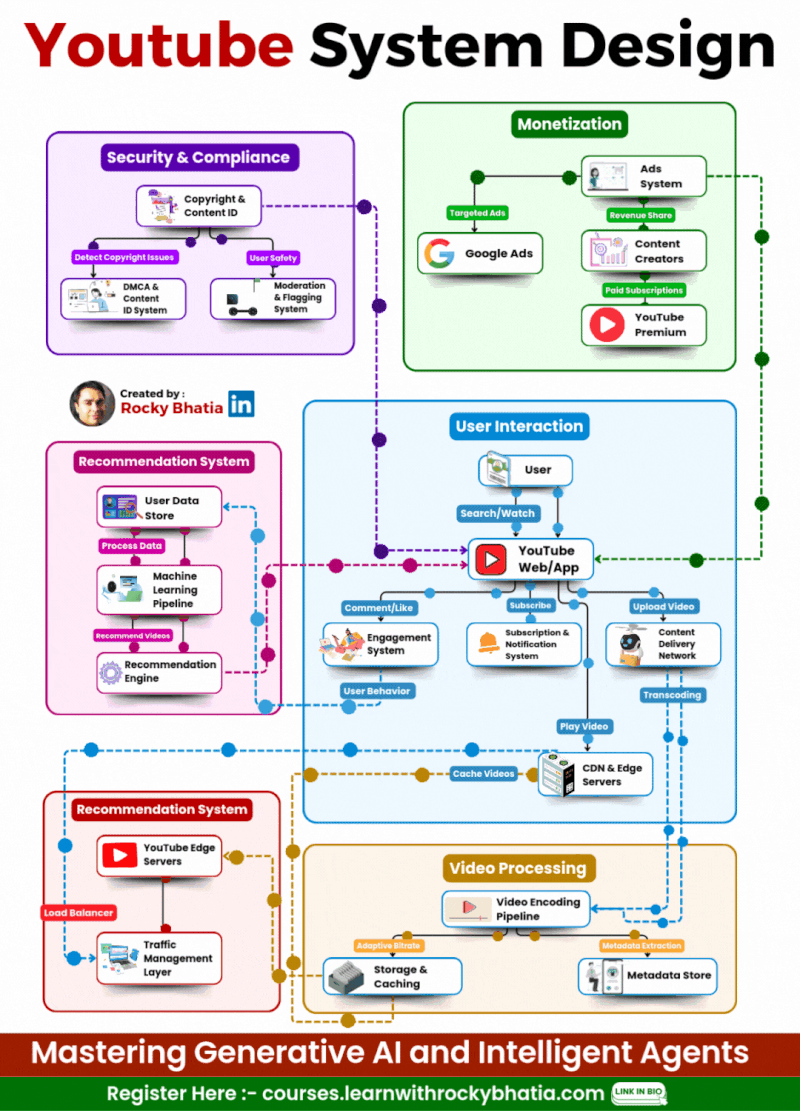
🔹 1. User Interaction Users engage via Web/App, where they search, watch, upload, comment, like, and subscribe. A robust engagement system ensures real-time updates.
🔹 2. Video Processing Uploaded videos go through a Video Encoding Pipeline, enabling adaptive bitrate streaming for smooth playback across devices. Metadata is extracted to optimize search and recommendations.
🔹 3. Content Distribution A global CDN (Content Delivery Network) and Edge Servers cache and serve videos efficiently, reducing load times and enhancing playback performance. Traffic Management Layers balance load dynamically.
🔹 4. Recommendation System AI-powered Machine Learning Pipelines analyze user behavior to suggest highly relevant videos, boosting engagement and retention.
🔹 5. Monetization YouTube leverages Google Ads for targeted advertising while revenue-sharing with creators. Premium subscriptions offer ad-free experiences and exclusive content.
🔹 6. Security & Compliance Copyright Detection, Content ID, and Moderation Systems safeguard creators’ content and ensure platform integrity while filtering inappropriate material.
🎯 The Outcome? A fault-tolerant, AI-driven, and scalable architecture that delivers seamless content consumption at an unprecedented scale! 🌍📺