
Types of Database

1. Relational Databases (e.g., MySQL, Oracle, SQL Server): – Uses structured tables to store data. – Offers data integrity and complex querying capabilities. – Known for ACID compliance, ensuring reliable transactions. – Includes features like foreign keys and security control, making them ideal for applications needing consistent data relationships.
2. Document Databases (e.g., CouchDB, MongoDB): – Stores data as JSON documents, providing flexible schemas that can adapt to varying structures. – Popular for semi-structured or unstructured data. – Commonly used in content management and automated sharding for scalability.
3. In-Memory Databases (e.g., Apache Geode, Hazelcast): – Focuses on real-time data processing with low-latency and high-speed transactions. – Frequently used in scenarios like gaming applications and high-frequency trading where speed is critical.
4. Graph Databases (e.g., Neo4j, OrientDB): – Best for handling complex relationships and networks, such as social networks or knowledge graphs. – Features like pattern recognition and traversal make them suitable for analyzing connected data structures.
5. Time-Series Databases (e.g., Timescale, InfluxDB): – Optimized for temporal data, IoT data, and fast retrieval. – Ideal for applications requiring data compression and trend analysis over time, such as monitoring logs.
6. Spatial Databases (e.g., PostGIS, Oracle, Amazon Aurora): – Specializes in geographic data and location-based queries. – Commonly used for applications involving maps, GIS, and geospatial data analysis, including earth sciences.
RPandS Rules High-Level Diagram

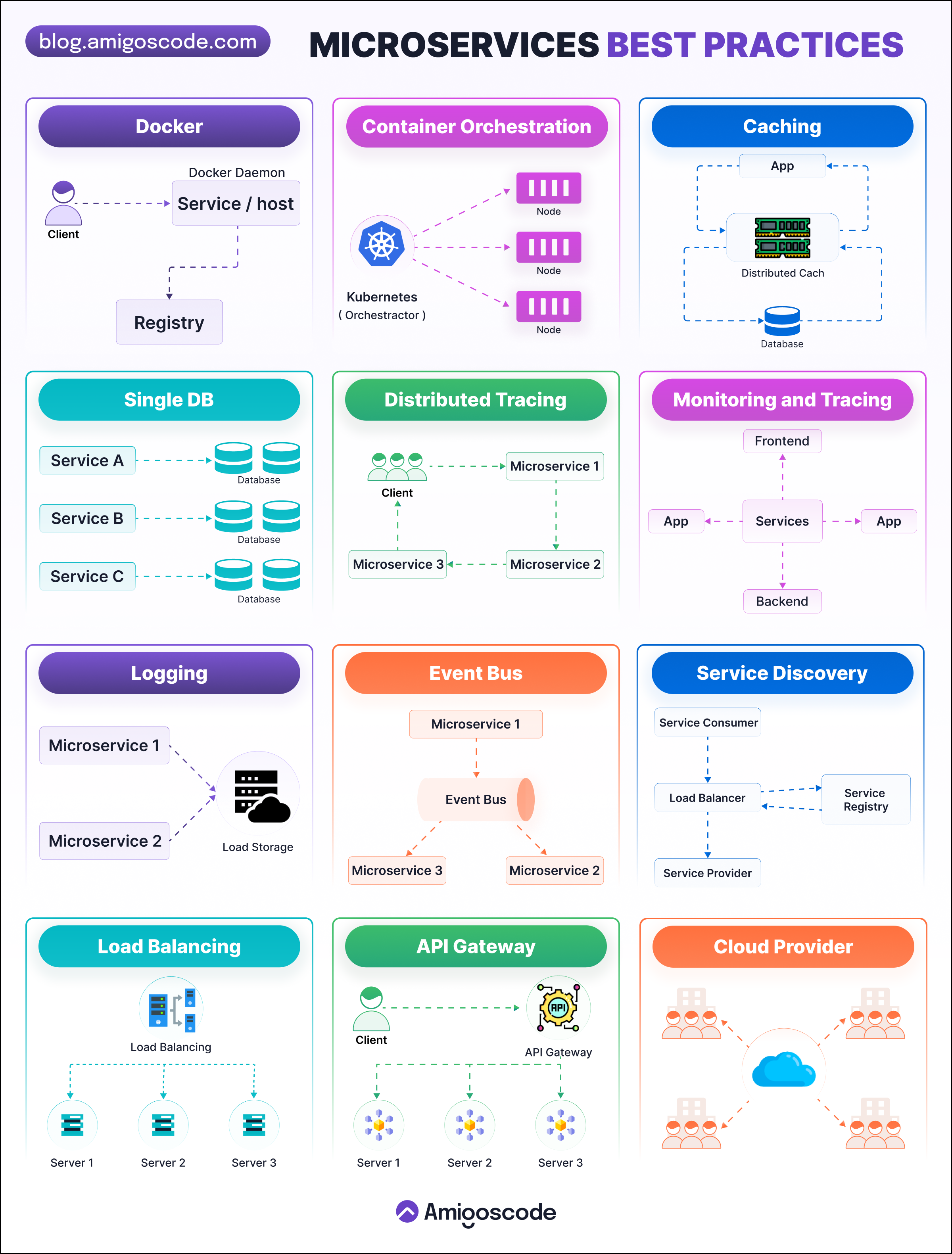
Microservices Best Practices
UML Cheat Sheet

AWS Architecture

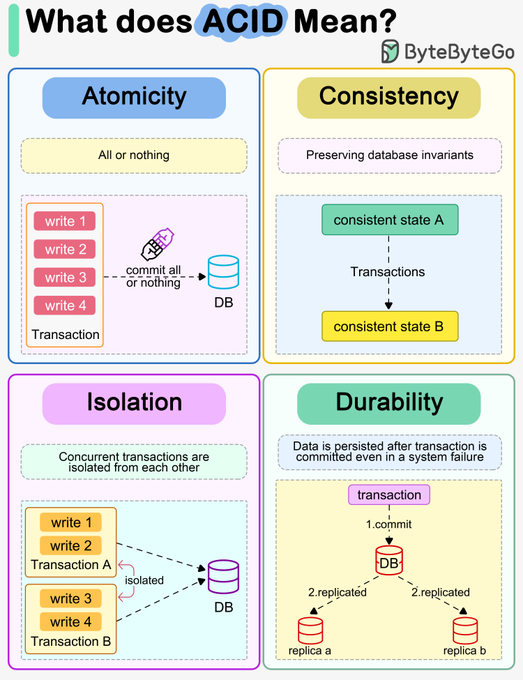
ACID
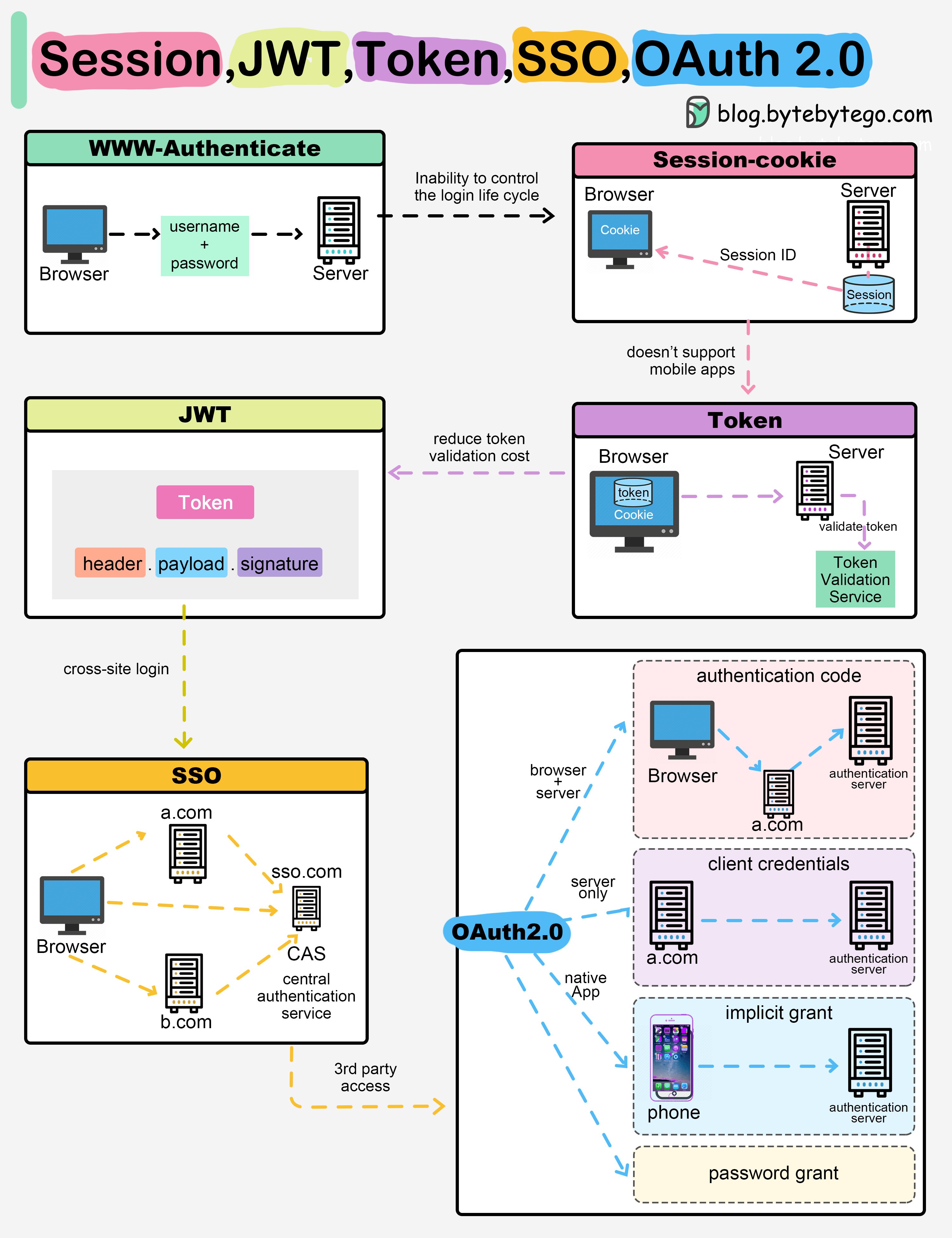
Session, JWT, Token, SSO, OAuth 2.0
Network Protocols

- HTTP (Hypertext Transfer Protocol): The foundation of data communication on the web, HTTP allows web pages to be requested and delivered across the internet.
- HTTPS (Hypertext Transfer Protocol Secure): An extension of HTTP, HTTPS adds a layer of security by encrypting data, making it safer for sensitive transactions online.
- FTP (File Transfer Protocol): A protocol used to transfer files between computers over a network, FTP is essential for managing and sharing large amounts of data.
- TCP (Transmission Control Protocol): Ensures that data sent over the internet arrives intact and in the correct order, making it reliable for most applications.
- IP (Internet Protocol): The addressing system for the internet, IP assigns unique addresses to devices, enabling them to be identified and communicate with each other.
- UDP (User Datagram Protocol): A faster but less reliable protocol compared to TCP, UDP is ideal for applications where speed is critical, like gaming and video streaming.
- SMTP (Simple Mail Transfer Protocol): The protocol responsible for sending emails across networks, ensuring messages reach their intended recipients.
- SSH (Secure Shell): A protocol that provides secure access to remote computers, widely used for system administration and secure data transfers.
- IMAP (Internet Message Access Protocol): Allows users to access and manage their email on a remote server, making it easier to sync messages across multiple devices.
The 18 Most Used Java List Methods

- 1. add(E element) – Adds the specified element to the end of the list.
- 2. addAll(Collection<? extends E> c) – Adds all elements of the specified collection to the end of the list.
- 3. remove(Object o) – Removes the first occurrence of the specified element from the list.
- 4. remove(int index) – Removes the element at the specified position in the list.
- 5. get(int index) – Returns the element at the specified position in the list.
- 6. set(int index, E element) – Replaces the element at the specified position in the list with the specified element.
- 7. indexOf(Object o) – Returns the index of the first occurrence of the specified element in the list.
- 8. contains(Object o) – Returns true if the list contains the specified element.
- 9. size() – Returns the number of elements in the list.
- 10. isEmpty() – Returns true if the list contains no elements.
- 11. clear() – Removes all elements from the list.
- 12. toArray() – Returns an array containing all the elements in the list.
- 13. subList(int fromIndex, int toIndex) – Returns a view of the portion of the list between the specified fromIndex, inclusive, and toIndex, exclusive.
- 14. addAll(int index, Collection<? extends E> c) – Inserts all elements of the specified collection into the list, starting at the specified position.
- 15. iterator() – Returns an iterator over the elements in the list.
- 16. sort(Comparator<? super E> c) – Sorts the elements of the list according to the specified comparator.
- 17. replaceAll(UnaryOperator operator) – Replaces each element of the list with the result of applying the given operator.
- 18. forEach(Consumer<? super E> action) – Performs the given action for each element of the list until all elements have been processed or the action throws an exception.