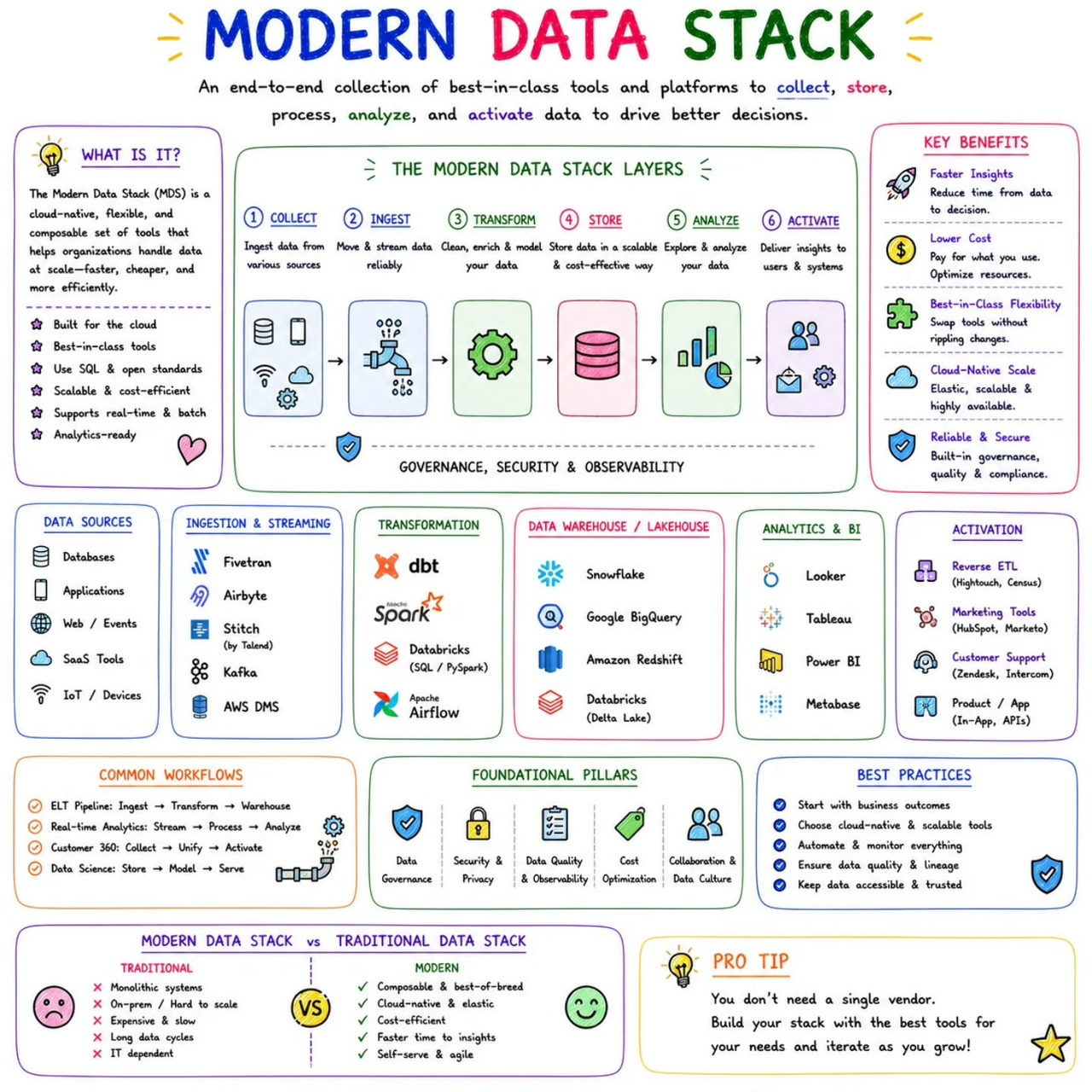
Kafka Architecture
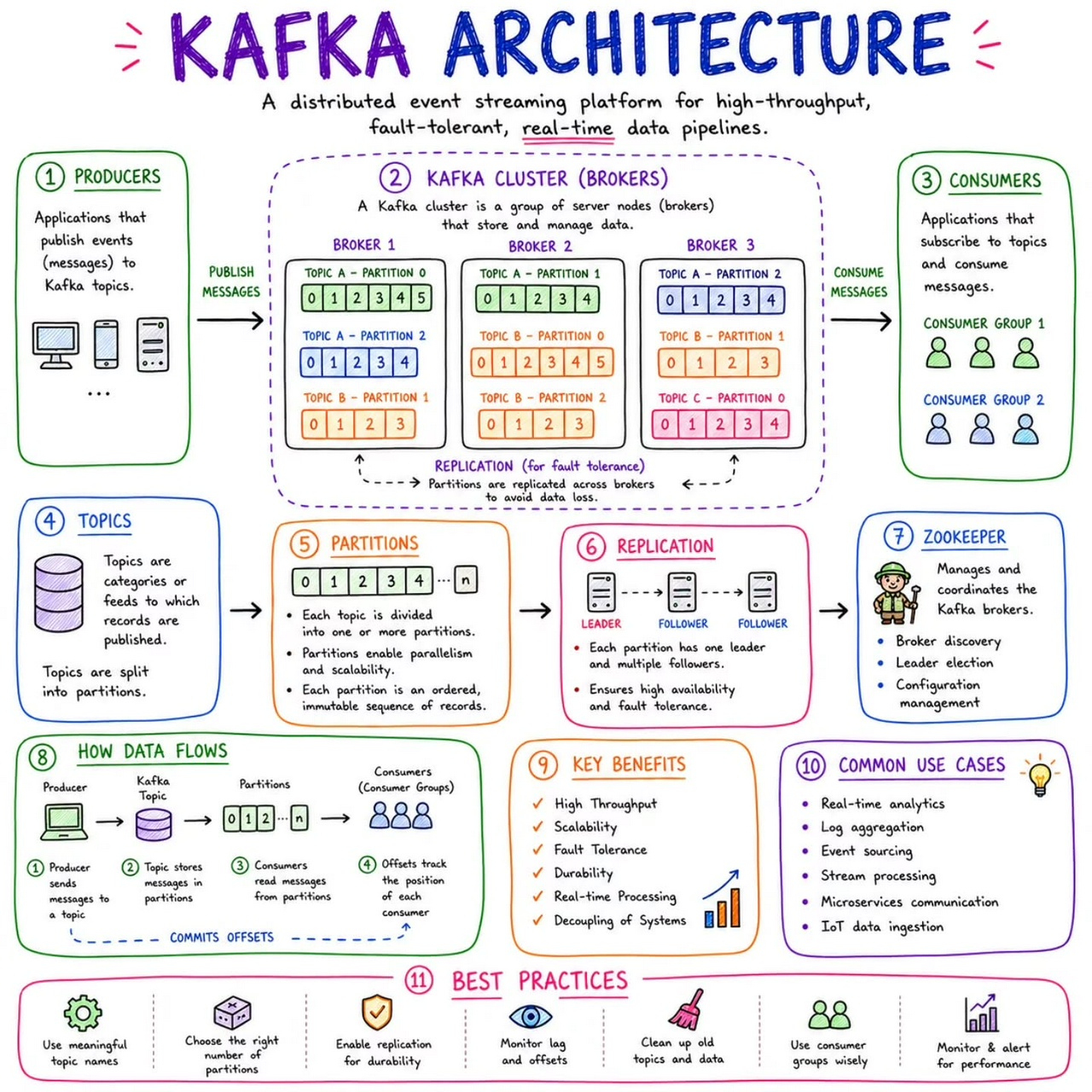
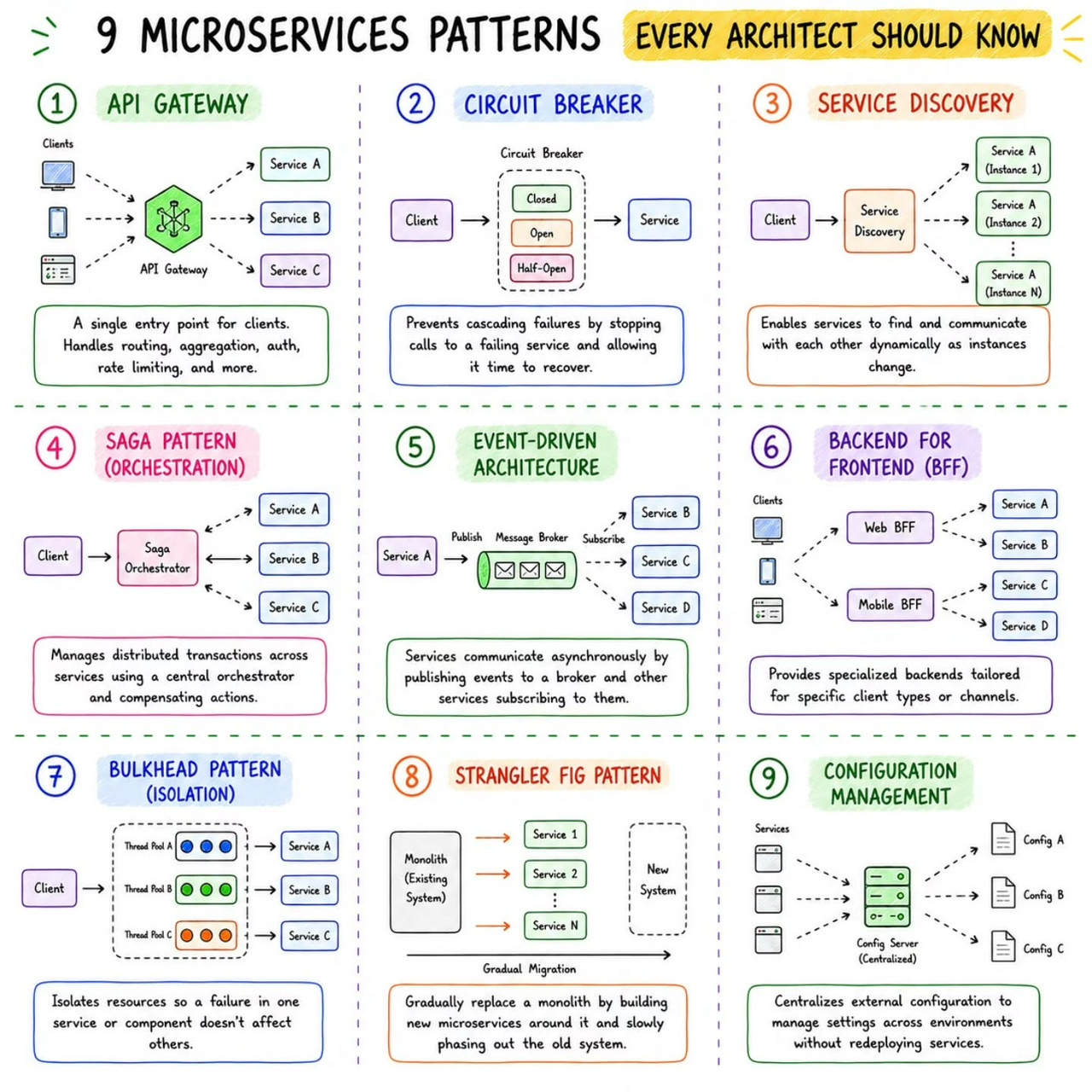
Microservice Patterns
SOLID Principles

#SOLID #solidprinciples #objectoriented #oop
𝐒 – 𝐒𝐢𝐧𝐠𝐥𝐞 𝐑𝐞𝐬𝐩𝐨𝐧𝐬𝐢𝐛𝐢𝐥𝐢𝐭𝐲 𝐏𝐫𝐢𝐧𝐜𝐢𝐩𝐥𝐞 A class should have only one reason to change. - Example: Instead of one giant User class that handles authentication, profile updates, and sending emails, split it into UserAuth, UserProfile, and EmailService.
𝐎 – 𝐎𝐩𝐞𝐧/𝐂𝐥𝐨𝐬𝐞𝐝 𝐏𝐫𝐢𝐧𝐜𝐢𝐩𝐥𝐞 Classes should be open for extension but closed for modification. - Example: Define a Shape interface with an area() method. When you need a new shape, just add a Circle or Triangle class that implements it.
𝐋 – 𝐋𝐢𝐬𝐤𝐨𝐯 𝐒𝐮𝐛𝐬𝐭𝐢𝐭𝐮𝐭𝐢𝐨𝐧 𝐏𝐫𝐢𝐧𝐜𝐢𝐩𝐥𝐞 Subtypes must be substitutable for their base types without breaking behavior. - Example: If Bird has a fly() method, then Eagle and Sparrow should both work anywhere a Bird is expected.
𝐈 – 𝐈𝐧𝐭𝐞𝐫𝐟𝐚𝐜𝐞 𝐒𝐞𝐠𝐫𝐞𝐠𝐚𝐭𝐢𝐨𝐧 𝐏𝐫𝐢𝐧𝐜𝐢𝐩𝐥𝐞 Don't force classes to implement interfaces they don't use. - Example: Instead of one fat Machine interface with print(), scan(), and fax(), break it into Printable, Scannable, and Faxable. A SimplePrinter only implements Printable.
𝐃 – 𝐃𝐞𝐩𝐞𝐧𝐝𝐞𝐧𝐜𝐲 𝐈𝐧𝐯𝐞𝐫𝐬𝐢𝐨𝐧 𝐏𝐫𝐢𝐧𝐜𝐢𝐩𝐥𝐞 High-level modules should not depend on low-level modules. Both should depend on abstractions. - Example: Your OrderService should depend on a PaymentGateway interface, not directly on Stripe or PayPal.
The real power of SOLID is not in following each principle in isolation. It's in how they work together to make your code easier to change, test, and extend.
Learn Linux (part 1)

SSH Commands

SSH is one of the most important tools in Linux & DevOps.
But most engineers only use: ssh user@host
without understanding what actually happens underneath.
In this series: 🔐 How SSH creates a secure encrypted tunnel 🧠 How authentication & key exchange work ⚙️ Important SSH command options explained 🛡️ Security best practices for production servers
Topics covered: • SSH workflow • Public/private key authentication • Encryption & integrity • Host verification • Port forwarding • Debugging flags • Secure SSH practices
💡 Pro Tip: Always prefer key-based authentication over passwords.
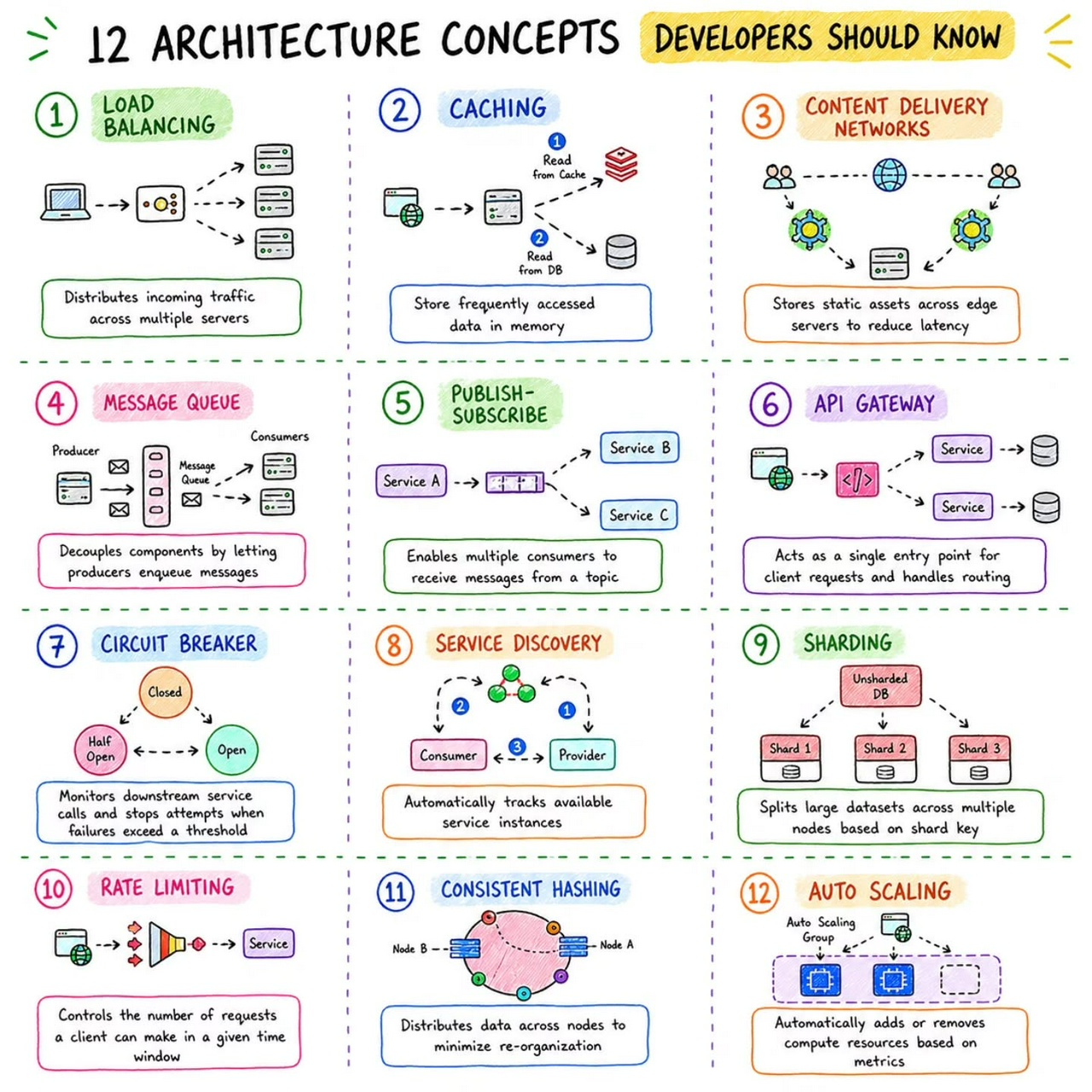
Architecture Concepts
Big O Complexities
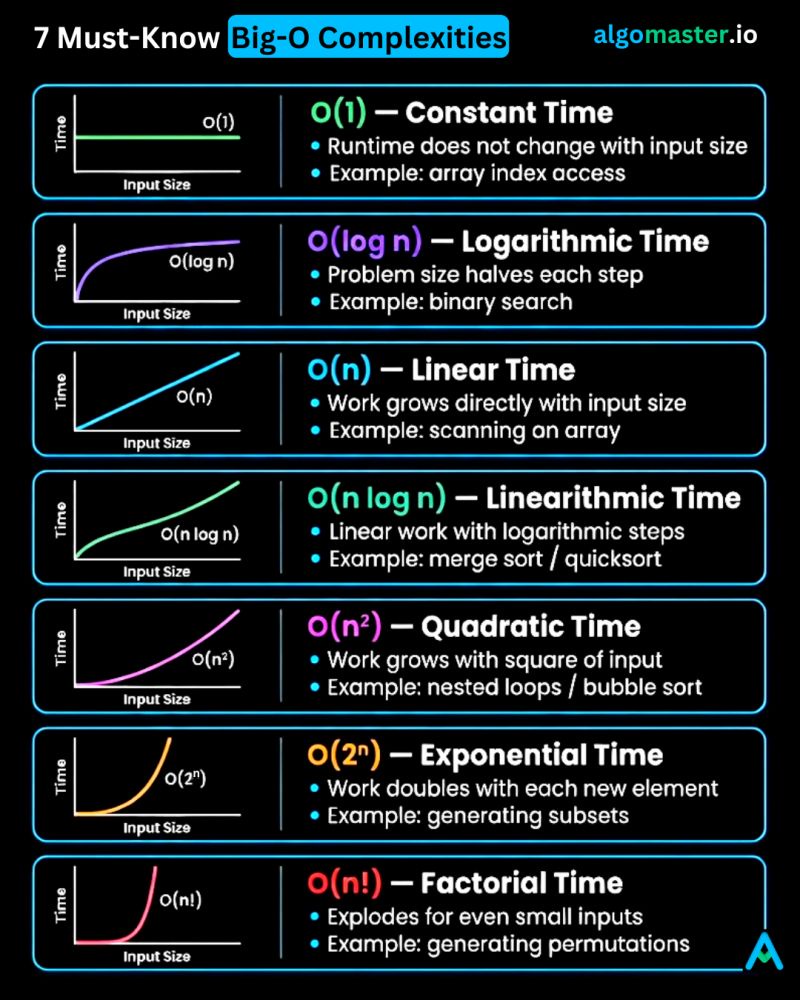
1. 𝐎(1) – 𝐂𝐨𝐧𝐬𝐭𝐚𝐧𝐭 𝐭𝐢𝐦𝐞 - The runtime doesn't change regardless of the input size. - Example: Accessing an element in an array by its index.
2. 𝐎(𝐥𝐨𝐠 𝐧) – 𝐋𝐨𝐠𝐚𝐫𝐢𝐭𝐡𝐦𝐢𝐜 𝐭𝐢𝐦𝐞 - The runtime grows slowly as the input size increases. Typically seen in algorithms that divide the problem in half with each step. - Example: Binary search in a sorted array.
3. 𝐎(𝐧) – 𝐋𝐢𝐧𝐞𝐚𝐫 𝐭𝐢𝐦𝐞 - The runtime grows linearly with the input size. - Example: Finding an element in an array by iterating through each element.
4. 𝐎(𝐧 𝐥𝐨𝐠 𝐧) – 𝐋𝐢𝐧𝐞𝐚𝐫𝐢𝐭𝐡𝐦𝐢𝐜 𝐭𝐢𝐦𝐞 - The runtime grows slightly faster than linear time. It involves a logarithmic number of operations for each element in the input. - Example: Sorting an array using quick sort or merge sort.
5. 𝐎(𝐧^2) – 𝐐𝐮𝐚𝐝𝐫𝐚𝐭𝐢𝐜 𝐭𝐢𝐦𝐞 - The runtime grows proportionally to the square of the input size. - Example: Bubble sort algorithm which compares and potentially swaps every pair of elements.
6. 𝐎(2^𝐧) – 𝐄𝐱𝐩𝐨𝐧𝐞𝐧𝐭𝐢𝐚𝐥 𝐭𝐢𝐦𝐞 - The runtime doubles with each addition to the input. These algorithms become impractical for larger input sizes. - Example: Generating all subsets of a set.
7. 𝐎(𝐧!) – 𝐅𝐚𝐜𝐭𝐨𝐫𝐢𝐚𝐥 𝐭𝐢𝐦𝐞 - Runtime is proportional to the factorial of the input size. - Example: Generating all permutations of a set.
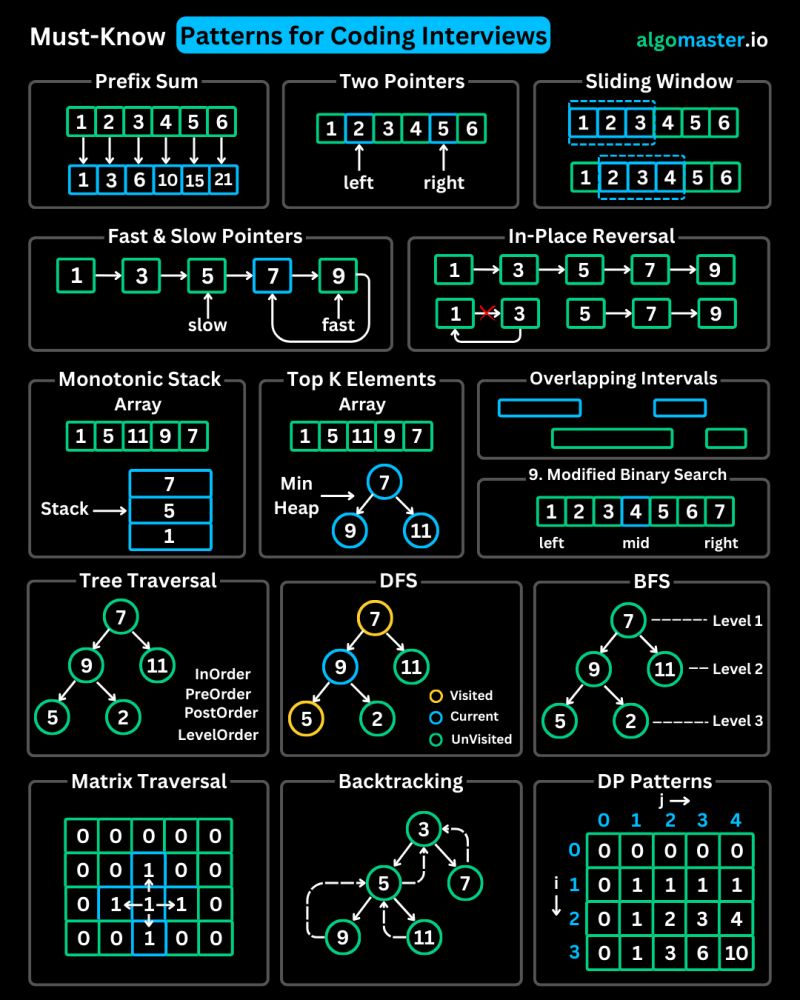
Data Structure and Algorithm Coding Patterns
Redis Use Cases
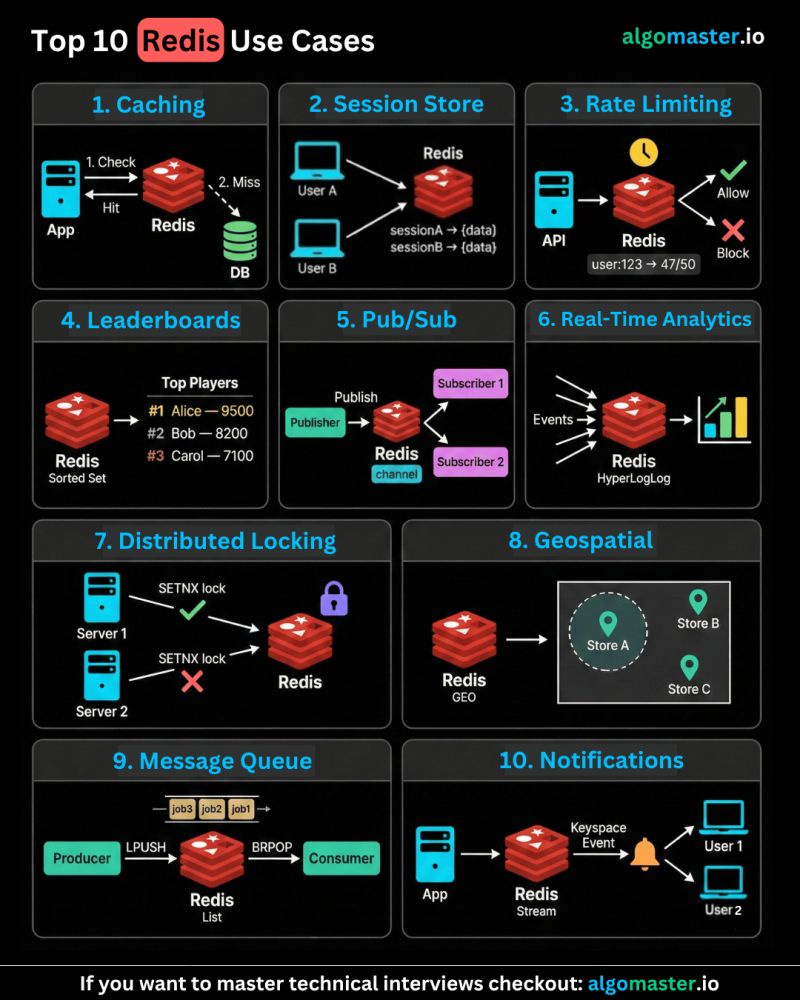
1. 𝐂𝐚𝐜𝐡𝐢𝐧𝐠 The most common use case. Your app checks Redis before hitting the database. If the key exists, return it instantly. If not, query the DB, store the result in Redis, and serve it.
2. 𝐒𝐞𝐬𝐬𝐢𝐨𝐧 𝐒𝐭𝐨𝐫𝐞 When a user logs in, store their session data (user ID, roles, preferences) in Redis. Every subsequent request just looks up the session key.
3. 𝐑𝐚𝐭𝐞 𝐋𝐢𝐦𝐢𝐭𝐢𝐧𝐠 Redis makes rate limiting trivial. Use INCR to increment a request counter and EXPIRE to reset it after a fixed window. If the count exceeds the limit, throttle or block the request.
4. 𝐋𝐞𝐚𝐝𝐞𝐫𝐛𝐨𝐚𝐫𝐝𝐬 Redis Sorted Sets keep users ranked by score in real time. You can update scores, fetch the top N users, and find a user’s rank efficiently in O(log N) operations.
5. 𝐏𝐮𝐛/𝐒𝐮𝐛 𝐌𝐞𝐬𝐬𝐚𝐠𝐢𝐧𝐠 Publishers send messages to a channel, and subscribers receive them instantly. Great for chat, live notifications, and dashboards. Trade-off: messages are fire-and-forget.
6. 𝐑𝐞𝐚𝐥-𝐓𝐢𝐦𝐞 𝐀𝐧𝐚𝐥𝐲𝐭𝐢𝐜𝐬 Use counters and HyperLogLog to track clicks, views, searches, unique visitors, and active users with very low memory usage.
7. 𝐃𝐢𝐬𝐭𝐫𝐢𝐛𝐮𝐭𝐞𝐝 𝐋𝐨𝐜𝐤𝐢𝐧𝐠 Redis SETNX (SET if Not eXists) lets you acquire a lock atomically. Set it with a TTL so locks auto-release if a process crashes. For stronger guarantees, use the Redlock algorithm.
8. 𝐆𝐞𝐨𝐬𝐩𝐚𝐭𝐢𝐚𝐥 𝐐𝐮𝐞𝐫𝐢𝐞𝐬 Redis GEO commands let you store coordinates and query nearby locations, such as restaurants within 5 km or drivers near a user. It uses sorted sets with geohash encoding under the hood.
9. 𝐌𝐞𝐬𝐬𝐚𝐠𝐞 𝐐𝐮𝐞𝐮𝐞 Redis Lists with LPUSH and BRPOP can act as a lightweight queue for simple background jobs. For more advanced use cases, Redis Streams are a better fit.
10. 𝐑𝐞𝐚𝐥-𝐓𝐢𝐦𝐞 𝐍𝐨𝐭𝐢𝐟𝐢𝐜𝐚𝐭𝐢𝐨𝐧𝐬 Redis Streams provide an append-only log with consumer groups. Keyspace Notifications let you subscribe to changes on specific keys. Useful for notifications, activity feeds, background processing, and real-time pipelines.