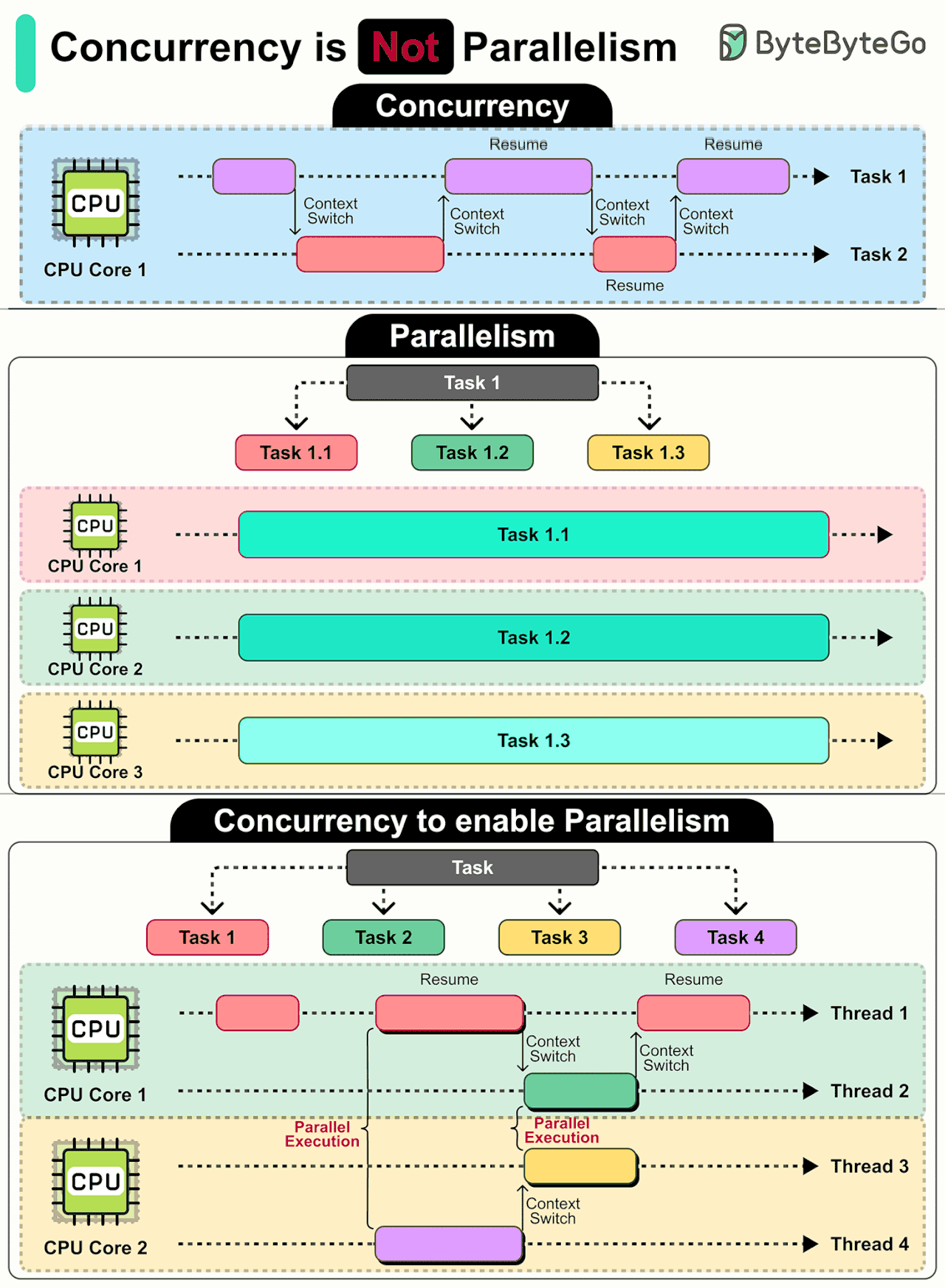
Modern Software Stack
In today’s world, building software means working across multiple layers, each with its own role, tools, and technologies. Here are 9 layers that make up most modern applications:
Presentation Layer (UI/UX): Handles how users interact with the application, focusing on visuals, layout, and usability.
Edge and Delivery (Optional): Brings content closer to users through global delivery networks, reducing latency and improving performance.
Integration Layer (API): Defines how different parts of the system communicate, enabling interoperability between components.
Messaging & Async Processing (Optional): Processes tasks and events in the background to improve scalability and responsiveness.
Business Logic Layer: Implements the core rules, workflows, and decision-making processes of the application.
Data Access Layer: Acts as a bridge between application logic and stored data, ensuring secure and efficient retrieval or updates.
Data Storage Layer: Stores, organizes, and manages the application’s structured and unstructured data.
Analytics & ML (Optional): Analyzes data to generate insights, predictions, and intelligent features.
Infrastructure Layer (Hosting / Runtime): Provides the computing environment and resources for deploying, running, and scaling the application.
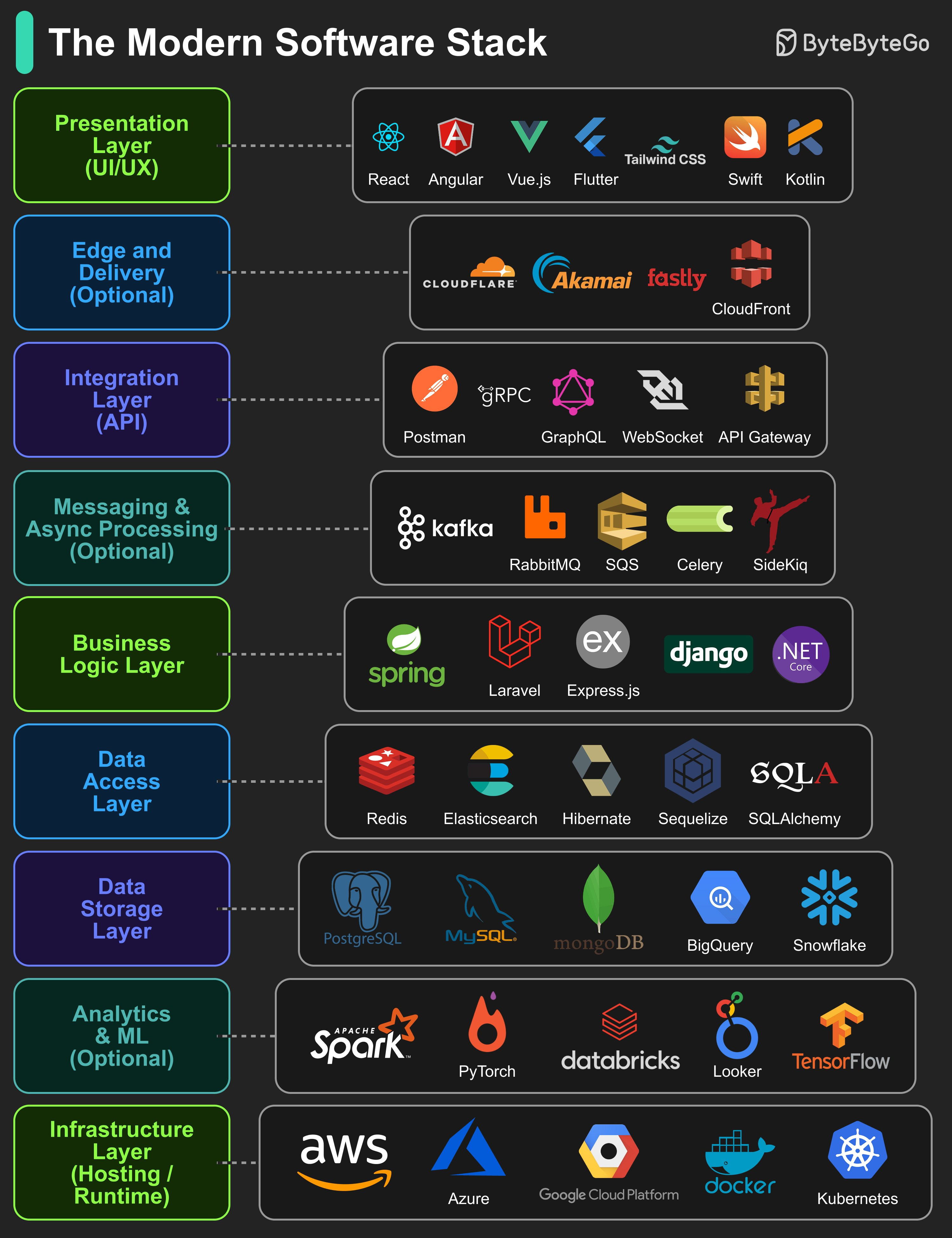
8 Data Structures which Power Databases
The answer will vary depending on your use case. Data can be indexed in memory or on disk. Similarly, data formats vary, such as numbers, strings, geographic coordinates, etc. The system might be write-heavy or read-heavy. All of these factors affect your choice of database index format.
The following are some of the most popular data structures used for indexing data:
- Skiplist: a common in-memory index type. Used in Redis
- Hash index: a very common implementation of the “Map” data structure (or “Collection”)
- SSTable: immutable on-disk “Map” implementation
- LSM tree: Skiplist + SSTable. High write throughput
- B-tree: disk-based solution. Consistent read/write performance
- Inverted index: used for document indexing. Used in Lucene
- Suffix tree: for string pattern search
- R-tree: multi-dimension search, such as finding the nearest neighbor
This is not an exhaustive list of all database index types.
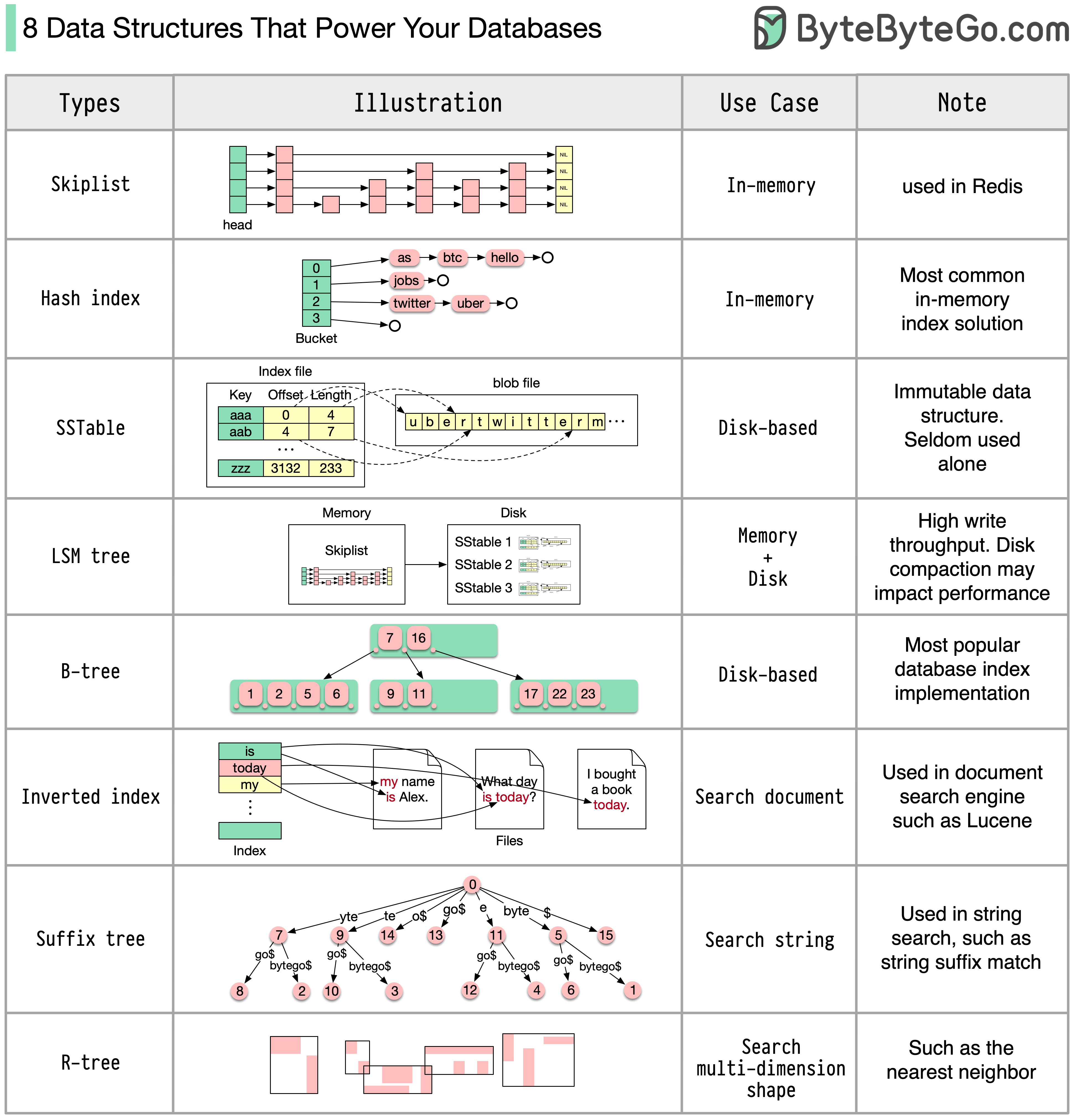
11 Steps to Go From Junior to Senior Developer
1. Collaboration Tools
Software development is a social activity. Learn to use collaboration tools like Jira, Confluence, Slack, MS Teams, Zoom, etc.
2. Programming Languages
Pick and master one or two programming languages. Choose from options like Java, Python, JavaScript, C#, Go, etc.
3. API Development
Learn the ins and outs of API Development approaches such as REST, GraphQL, and gRPC.
4. Web Servers and Hosting
Know about web servers as well as cloud platforms like AWS, Azure, GCP, and Kubernetes
5. Authentication and Testing
Learn how to secure your applications with authentication techniques such as JWTs, OAuth2, etc. Also, master testing techniques like TDD, E2E Testing, and Performance Testing
6. Databases
Learn to work with relational (Postgres, MySQL, and SQLite) and non-relational databases (MongoDB, Cassandra, and Redis).
7. CI/CD
Pick tools like GitHub Actions, Jenkins, or CircleCI to learn about continuous integration and continuous delivery.
8. Data Structures and Algorithms
Master the basics of DSA with topics like Big O Notation, Sorting, Trees, and Graphs.
9. System Design
Learn System Design concepts such as Networking, Caching, CDNs, Microservices, Messaging, Load Balancing, Replication, Distributed Systems, etc.
10. Design patterns
Master the application of design patterns such as dependency injection, factory, proxy, observers, and facade.
11. AI Tools
To future-proof your career, learn to leverage AI tools like GitHub Copilot, ChatGPT, Langchain, and Prompt Engineering.
Cookies vs Sessions vs JWT
Whether you're building an e-commerce site, a social platform, or an internal dashboard, authentication is your first line of defense. It ensures that only the right users can access the right resources.
Authentication answers a simple but critical question: “Who are you?”
Over the years, developers have used several mechanisms to implement authentication in web applications. The most common ones include Cookies, Sessions, and JSON Web Tokens (JWTs). Each has its strengths, weaknesses, and ideal use cases.
Let’s break them down one by one.
1 – Cookies and Sessions: The Traditional Duo
Here’s a view of a simple cookie-based authentication and how it works.

However, when you hear about cookie-based authentication, most of the time it refers to session-based authentication under the hood.
Here’s how it works:
- When a user logs in, the server creates a session in memory (or a database) and stores some information about the user, like user ID, role, etc.
- The server generates a unique session ID and sends it to the client in the form of a cookie.
- For every subsequent request, the client automatically sends this cookie, and the server uses it to retrieve the corresponding session data.
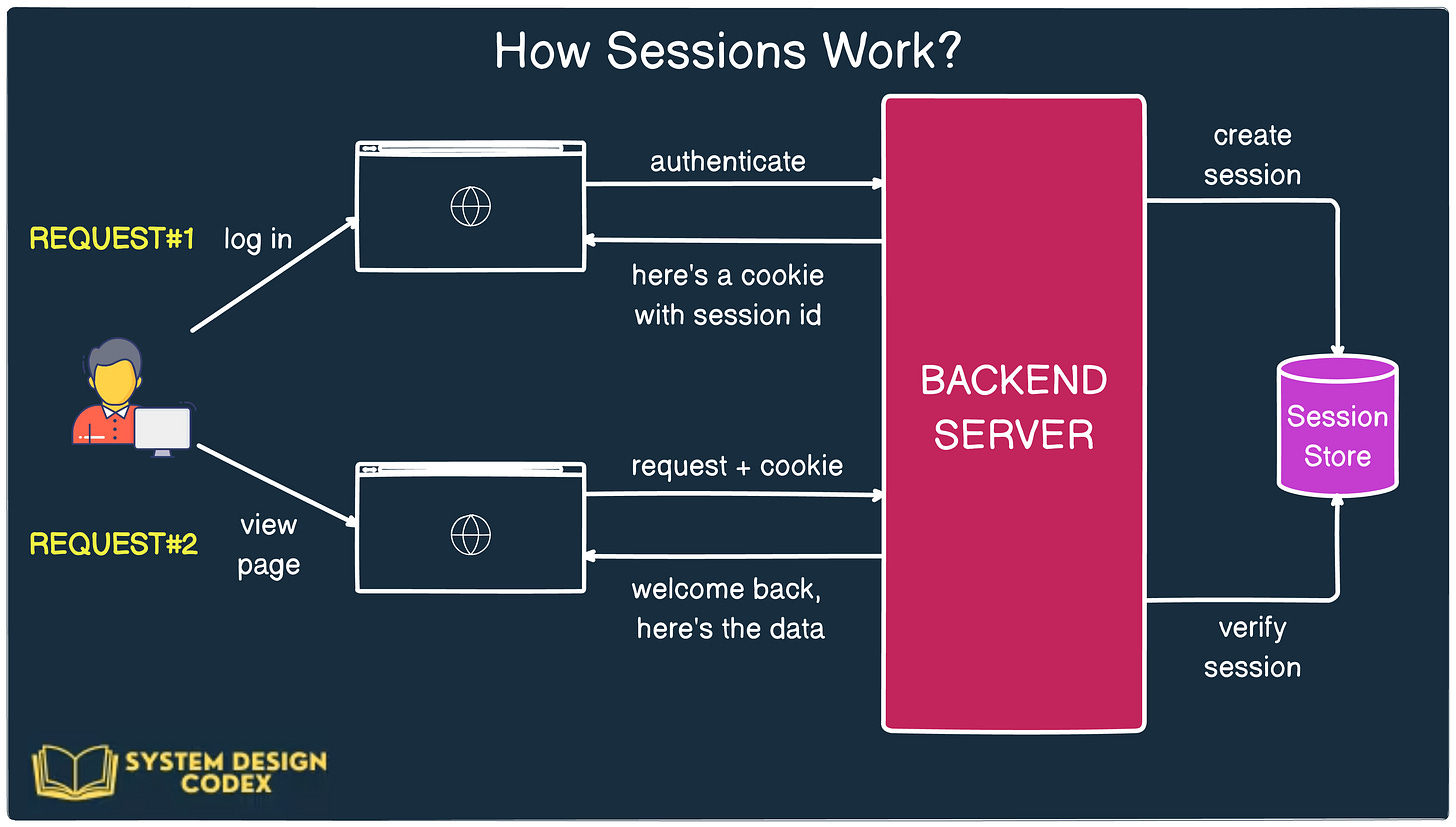
This approach keeps the actual user data on the server, ensuring that sensitive information isn’t exposed to the client.
Benefits of Cookies and Sessions: * Security: Since data is stored on the server, it’s not exposed to the client. * Control: The server can invalidate a session at any time (e.g., logout or session timeout). * Familiarity: Well-supported by most web frameworks and browsers.
Challenges: * Scalability: In a distributed system, maintaining sessions becomes tricky. You need to synchronize session data across servers or use centralized storage like Redis. * Statefulness: Sessions are inherently stateful, meaning the server needs to remember session data, which can lead to overhead at scale.
This model works well for monolithic or tightly controlled applications, especially those running on a single server or behind a load balancer with sticky sessions.
### 2 – JWT (JSON Web Token): The Stateless Way
JWT is a stateless authentication mechanism. It solves the scalability issue by pushing all the authentication data onto the client in a digitally signed token.
 Here’s how it works:
* When the user logs in, the server generates a JWT, which contains all necessary user data (like ID, email, and roles).
* This token is signed using a secret key and sent to the client (usually stored in localStorage or a cookie).
* Every future request includes the token (often in an
Here’s how it works:
* When the user logs in, the server generates a JWT, which contains all necessary user data (like ID, email, and roles).
* This token is signed using a secret key and sent to the client (usually stored in localStorage or a cookie).
* Every future request includes the token (often in an Authorization header).
* The server verifies the signature, reads the claims (payload), and processes the request.

Unlike sessions, the server does not need to store any user data—it just verifies the token on each request.
Benefits of JWTs: * Stateless and scalable: Ideal for microservices and distributed systems where central session storage is a bottleneck. * Portable: JWTs can be easily passed between services, APIs, and third-party systems. * Self-contained: All the data is within the token, including expiration and role claims.
Challenges: * Security: If a JWT is stolen, it can be reused until it expires. You cannot easily revoke it unless you implement additional checks (like a token blacklist or short expiration + refresh token model). * Token Bloat: JWTs can get large, especially with many claims. This increases network payload size. * Expiration Management: Once issued, the token is valid until it expires. You need to design a refresh mechanism to renew it securely.
JWTs are a natural fit for SPAs (Single Page Applications), mobile apps, or distributed systems where central state management is difficult.
### Best Practices for Any Authentication System
Regardless of the mechanism you choose, keep these practices in mind: * Use HTTPS to prevent token or cookie interception. * Set HttpOnly and Secure flags on cookies to reduce XSS risk. * For JWTs, keep the payload small and avoid storing sensitive information. * Use refresh tokens with short-lived access tokens. * Consider logout/invalidation strategies, especially for JWTs. * Rate limit login endpoints to prevent brute-force attacks.
Top 6 Multithreading Design Patterns
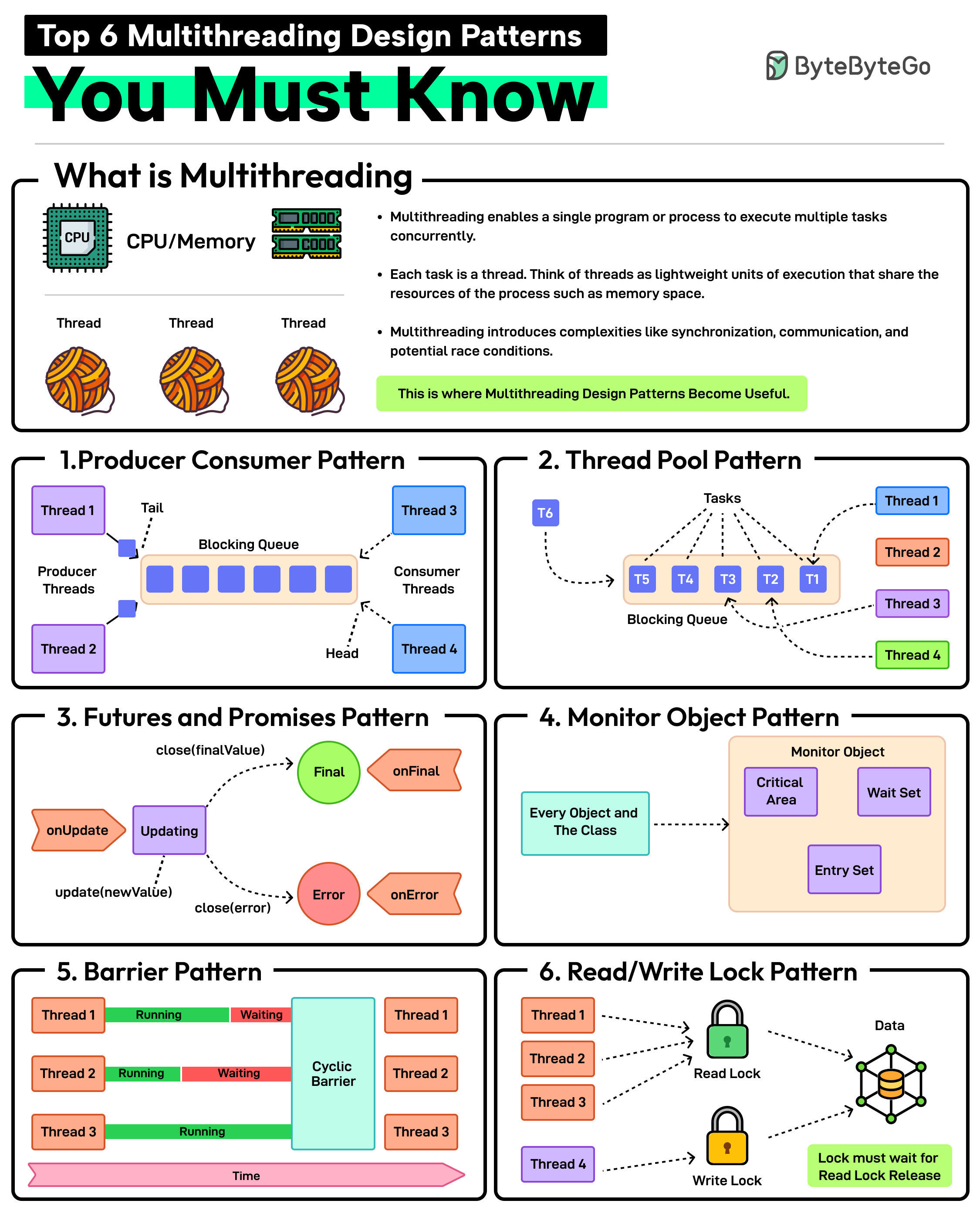
Multithreading enables a single program or process to execute multiple tasks concurrently. Each task is a thread. Think of threads as lightweight units of execution that share the resources of the process such as memory space.
However, multithreading also introduces complexities like synchronization, communication, and potential race conditions. This is where patterns help.
Producer-Consumer Pattern
This pattern involves two types of threads: producers generating data and consumers processing that data. A blocking queue acts as a buffer between the two.
Thread Pool Pattern
In this pattern, there is a pool of worker threads that can be reused for executing tasks. Using a pool removes the overhead of creating and destroying threads. Great for executing a large number of short-lived tasks.
Futures and Promises Pattern
In this pattern, the promise is an object that holds the eventual results and the future provides a way to access the result. This is great for executing long-running operations concurrently without blocking the main thread.
Monitor Object Pattern
Ensures that only one thread can access or modify a shared resource within an object at a time. This helps prevent race conditions. The pattern is required when you need to protect shared data or resources from concurrent access.
Barrier Pattern
Synchronizes a group of threads. Each thread executes until it reaches a barrier point in the code and blocks until all threads have reached the same barrier. Ideal for parallel tasks that need to reach a specific stage before starting the next stage.
Read-Write Lock Pattern
It allows multiple threads to read from a shared resource but only allows one thread to write to it at a time. Ideal for managing shared resources where reads are more frequent than writes.
8 Key Concepts in Domain-Driven-Design (DDD)
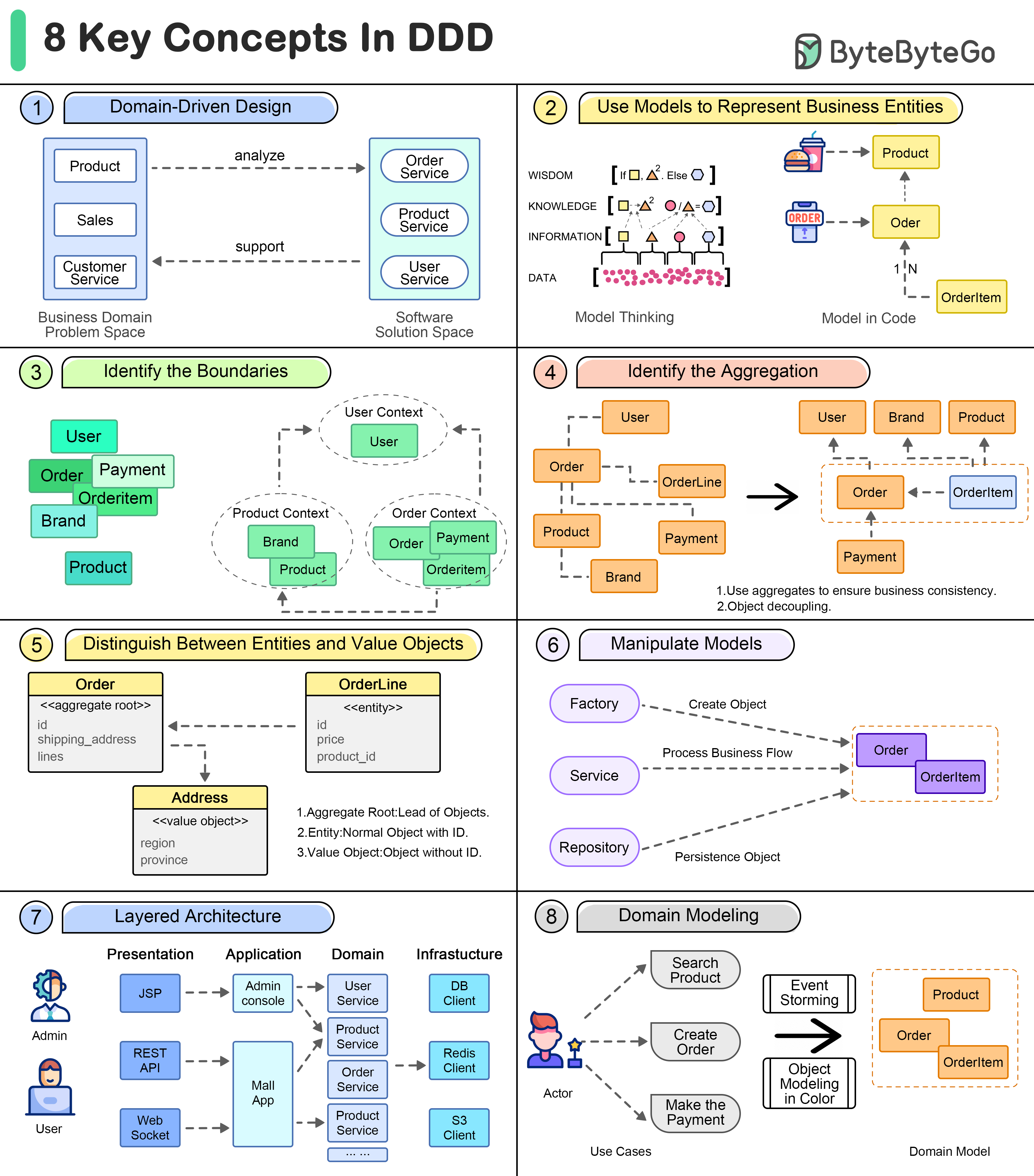
Domain-driven design advocates driving the design of software through domain modeling.
Unified language is one of the key concepts of domain-driven design. A domain model is a bridge across the business domains.
Domain Driven Design
Domain-driven design advocates driving the design of software through domain modeling.
Unified language is one of the key concepts of domain-driven design. A domain model is a bridge across the business domains.
Business Entities
The use of models can assist in expressing business concepts and knowledge and in guiding further development of software, such as databases, APIs, etc.
Model Boundaries
Loose boundaries among sets of domain models are used to model business correlations.
Aggregation
An Aggregate is a cluster of related objects (entities and value objects) that are treated as a single unit for the purpose of data changes.
Entities vs. Value Objects
In addition to aggregate roots and entities, there are some models that look like disposable, they don’t have their own ID to identify them, but are more as part of some entity that expresses a collection of several fields.
Operational Modeling
In domain-driven design, in order to manipulate these models, there are a number of objects that act as “operators”.
Layering the architecture
In order to better organize the various objects in a project, we need to simplify the complexity of complex projects by layering them like a computer network.
Build the domain model
Many methods have been invented to extract domain models from business knowledge.
Top 20 System Design Concepts You Should Know

Load Balancing: Distributes traffic across multiple servers for reliability and availability.
Caching: Stores frequently accessed data in memory for faster access.
Database Sharding: Splits databases to handle large-scale data growth.
Replication: Copies data across replicas for availability and fault tolerance.
CAP Theorem: Trade-off between consistency, availability, and partition tolerance.
Consistent Hashing: Distributes load evenly in dynamic server environments.
Message Queues: Decouples services using asynchronous event-driven architecture.
Rate Limiting: Controls request frequency to prevent system overload.
API Gateway: Centralized entry point for routing API requests.
Microservices: Breaks systems into independent, loosely coupled services.
Service Discovery: Locates services dynamically in distributed systems.
CDN: Delivers content from edge servers for speed.
Database Indexing: Speeds up queries by indexing important fields.
Data Partitioning: Divides data across nodes for scalability and performance.
Eventual Consistency: Guarantees consistency over time in distributed databases
WebSockets: Enables bi-directional communication for live updates.
Scalability: Increases capacity by upgrading or adding machines.
Fault Tolerance: Ensures system availability during hardware/software failures.
Monitoring: Tracks metrics and logs to understand system health.
Authentication & Authorization: Controls user access and verifies identity securely.
18 Key Design Patterns Every Developer Should Know
(https://stfalconcom.medium.com/software-design-patterns-every-dev-have-to-know-efb88accf446)
Patterns are reusable solutions to common design problems, resulting in a smoother, more efficient development process. They serve as blueprints for building better software structures. These are some of the most popular patterns:
- Abstract Factory: Family Creator – Makes groups of related items.
- Builder: Lego Master – Builds objects step by step, keeping creation and appearance separate.
- Prototype: Clone Maker – Creates copies of fully prepared examples.
- Singleton: One and Only – A special class with just one instance.
- Adapter: Universal Plug – Connects things with different interfaces.
- Bridge: Function Connector – Links how an object works to what it does.
- Composite: Tree Builder – Forms tree-like structures of simple and complex parts.
- Decorator: Customizer – Adds features to objects without changing their core.
- Facade: One-Stop-Shop – Represents a whole system with a single, simplified interface.
- Flyweight: Space Saver – Shares small, reusable items efficiently.
- Proxy: Stand-In Actor – Represents another object, controlling access or actions.
- Chain of Responsibility: Request Relay – Passes a request through a chain of objects until handled.
- Command: Task Wrapper – Turns a request into an object, ready for action.
- Iterator: Collection Explorer – Accesses elements in a collection one by one.
- Mediator: Communication Hub – Simplifies interactions between different classes.
- Memento: Time Capsule – Captures and restores an object’s state.
- Observer: News Broadcaster – Notifies classes about changes in other objects.
- Visitor: Skillful Guest – Adds new operations to a class without altering it
Debugging Summary
🧠 Summary of Debugging Process
1. Set breakpoints : Observe where error occurs
2. Start debugger : Launch program under observation
3. Step through code (F7, F8) : Watch variables change in real time
4. Inspect variables in context : Confirm null values before crash
5. Use stack trace + call stack view : Trace back to root cause
ChatGPT API Call:
”I would like a real Java (NullpointerException) debugging walkthrough with stack traces and step-by-step breakpoints”