Kafka
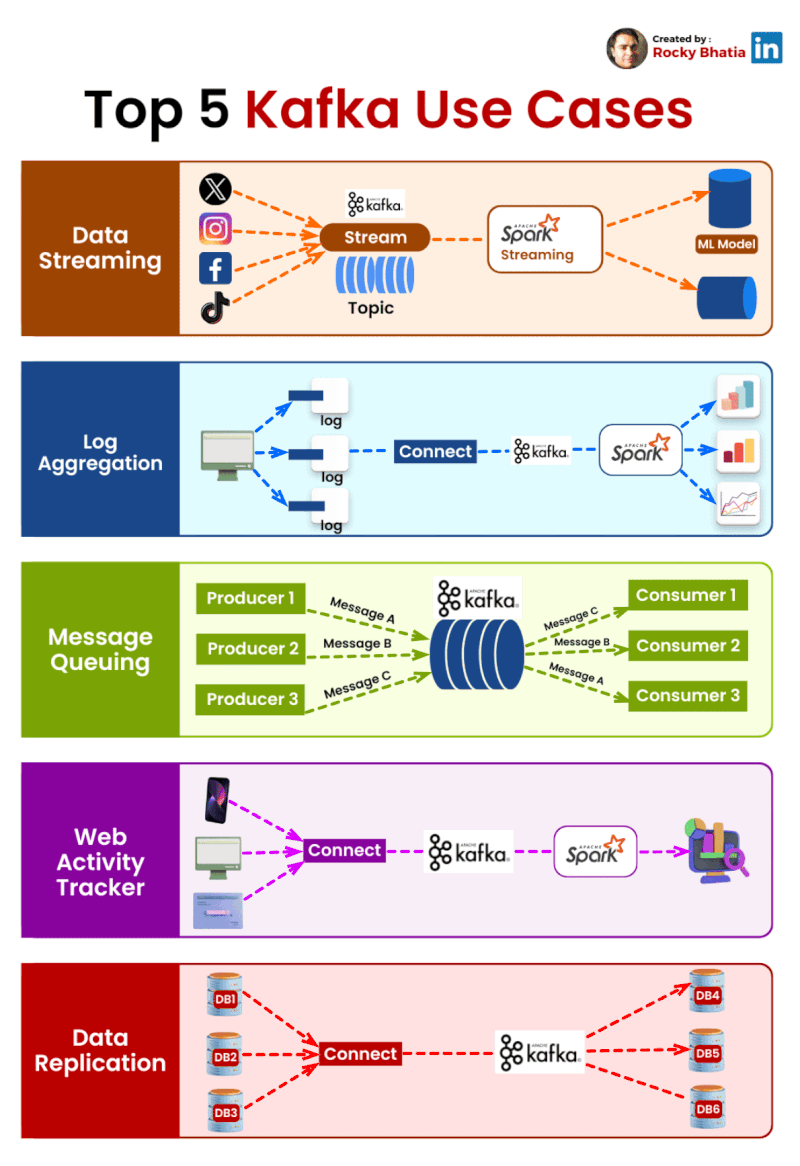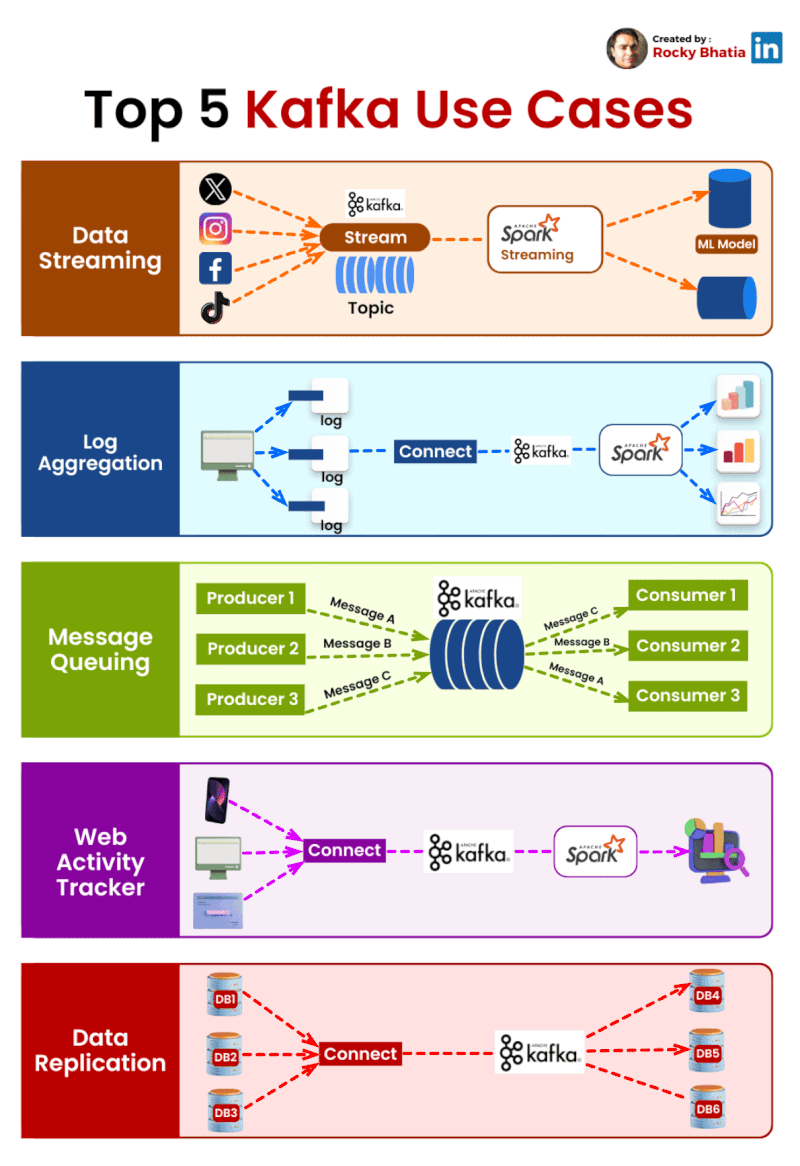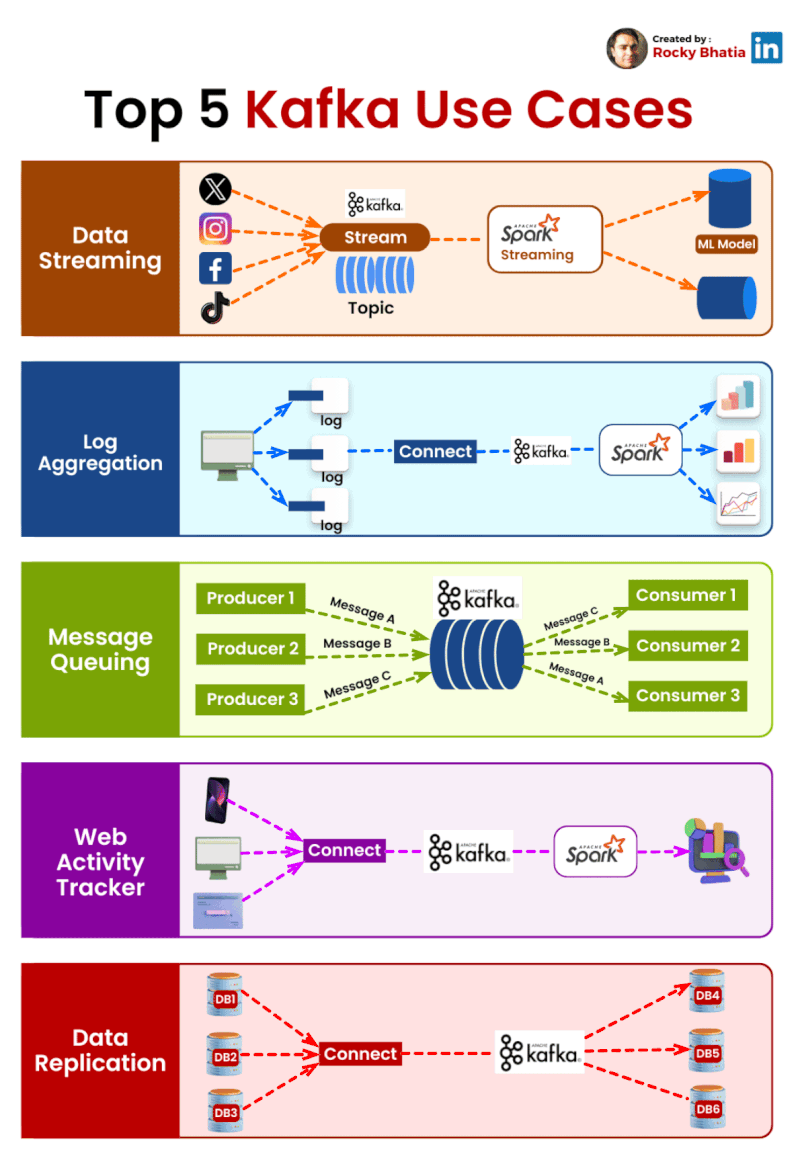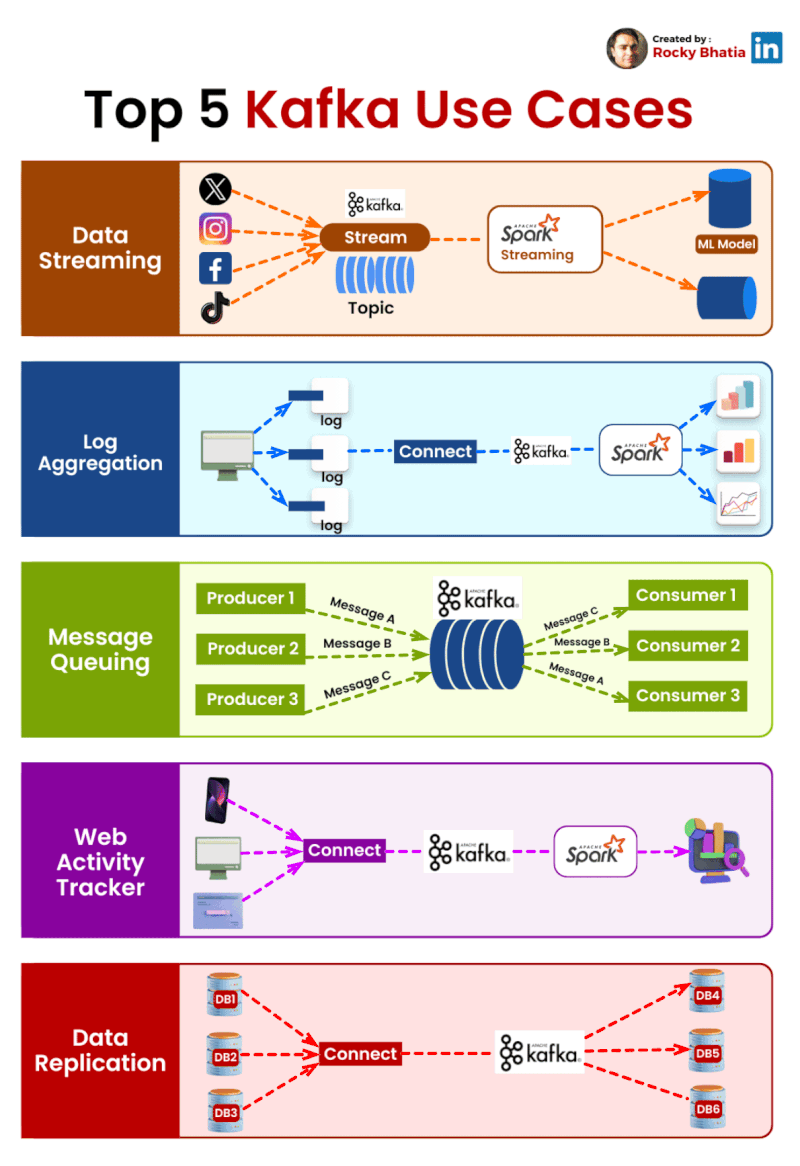
Top 5 Kafka Use Cases Transforming Industries:
Data Streaming 🌊: Monitor and act on real-time data across your organization.
Log Aggregation 📚: Manage large volumes of log data efficiently.
Message Queue 📨: Scale microservices communications with fault tolerance.
Web Activity Tracker 🕵️♂️: Customize user experiences with real-time insights.
Data Replication 🔁: Sync data seamlessly across systems.
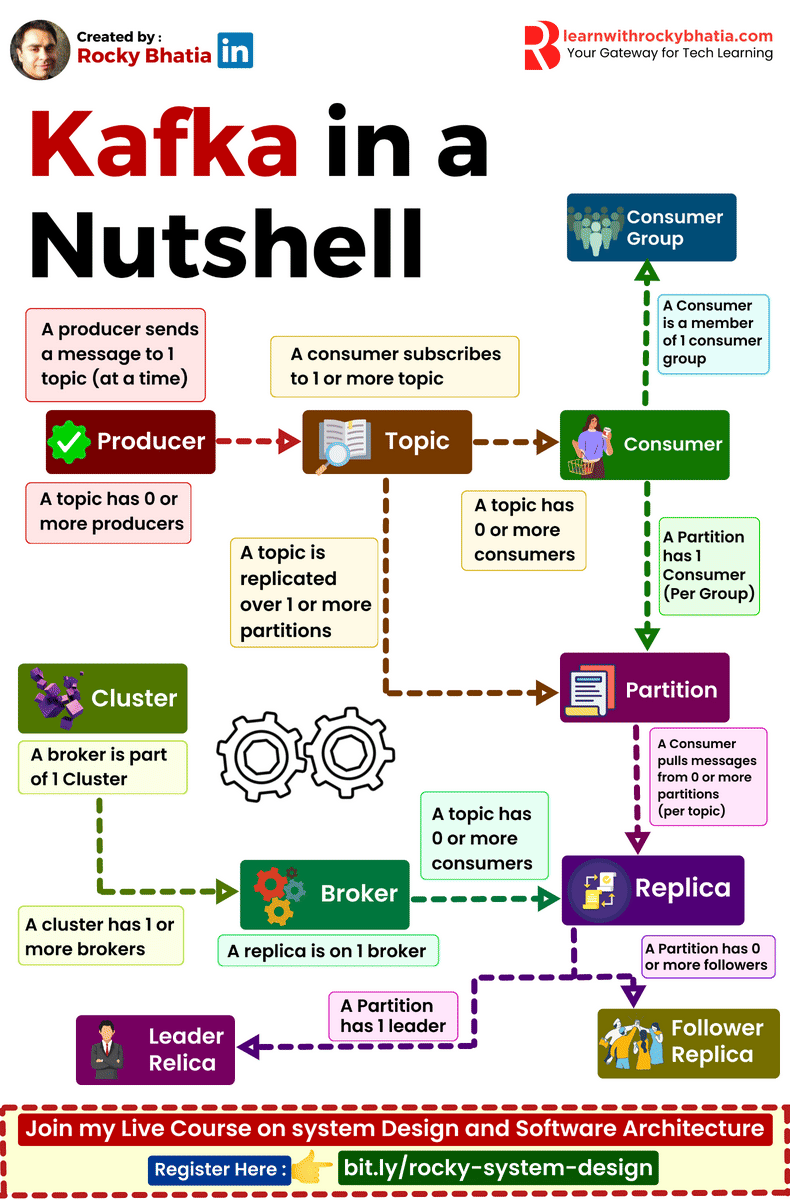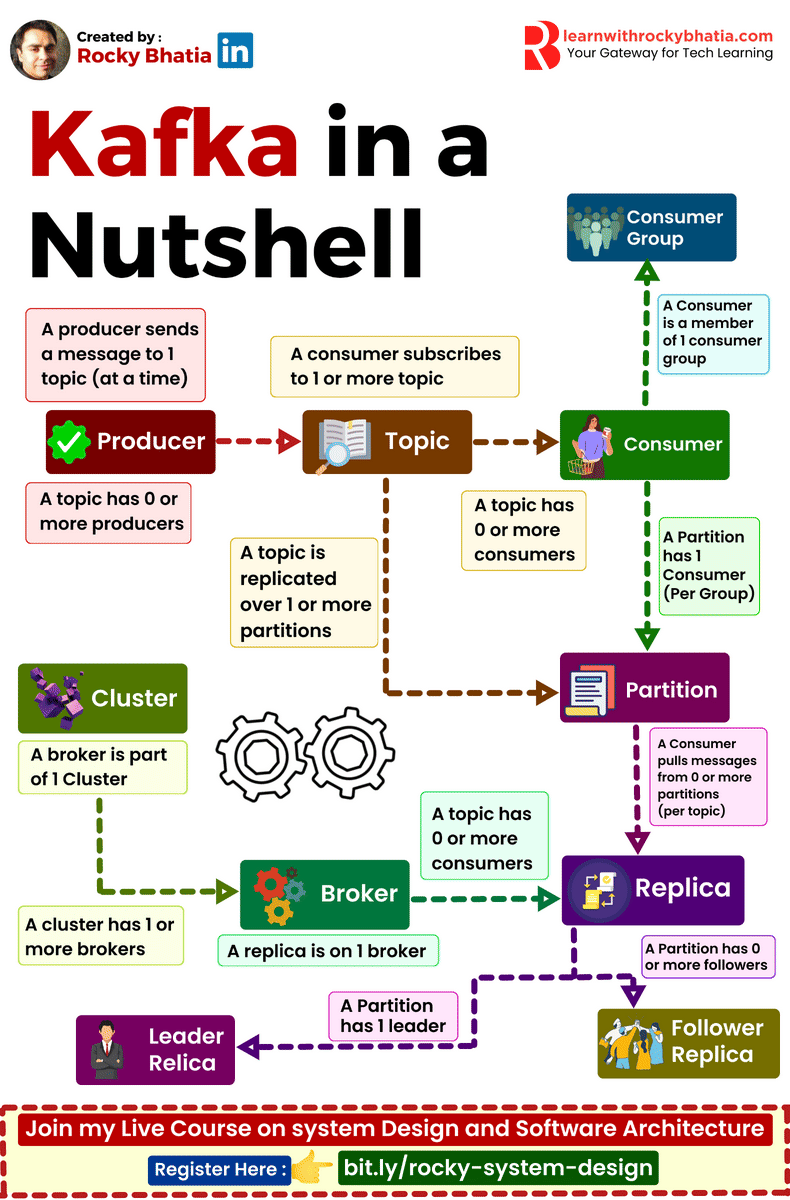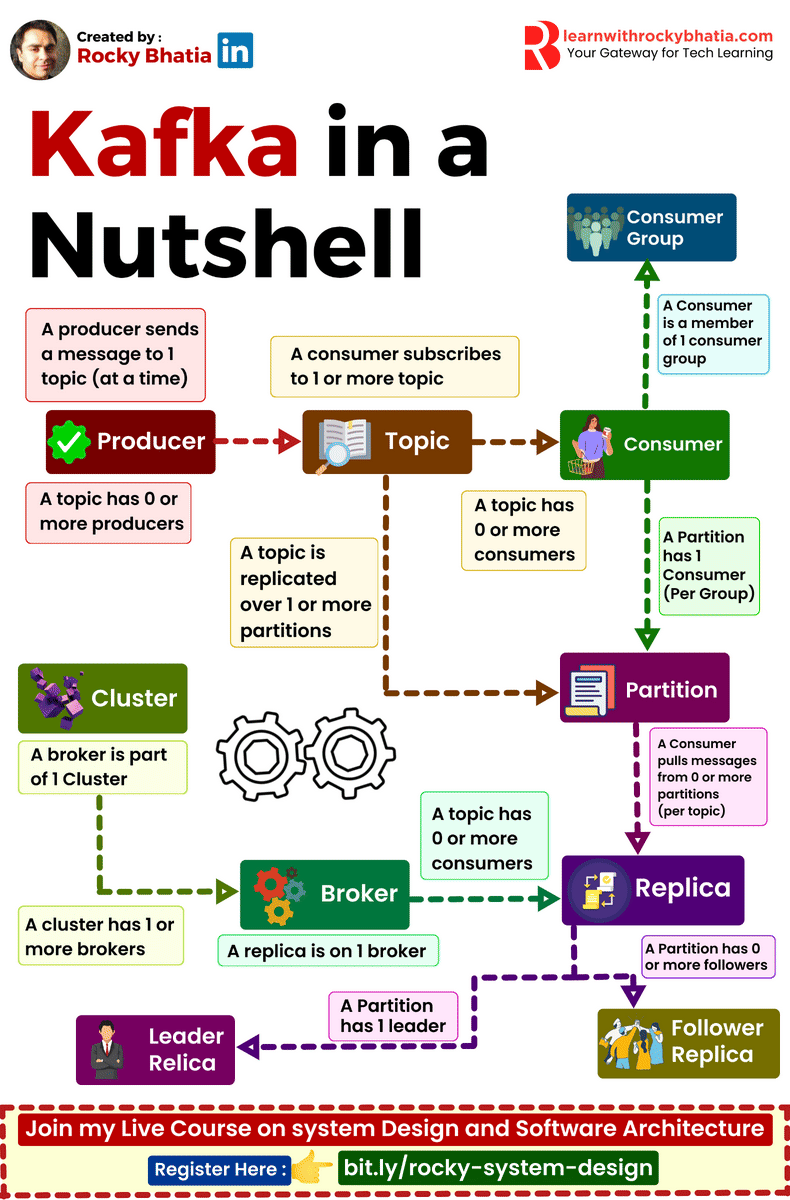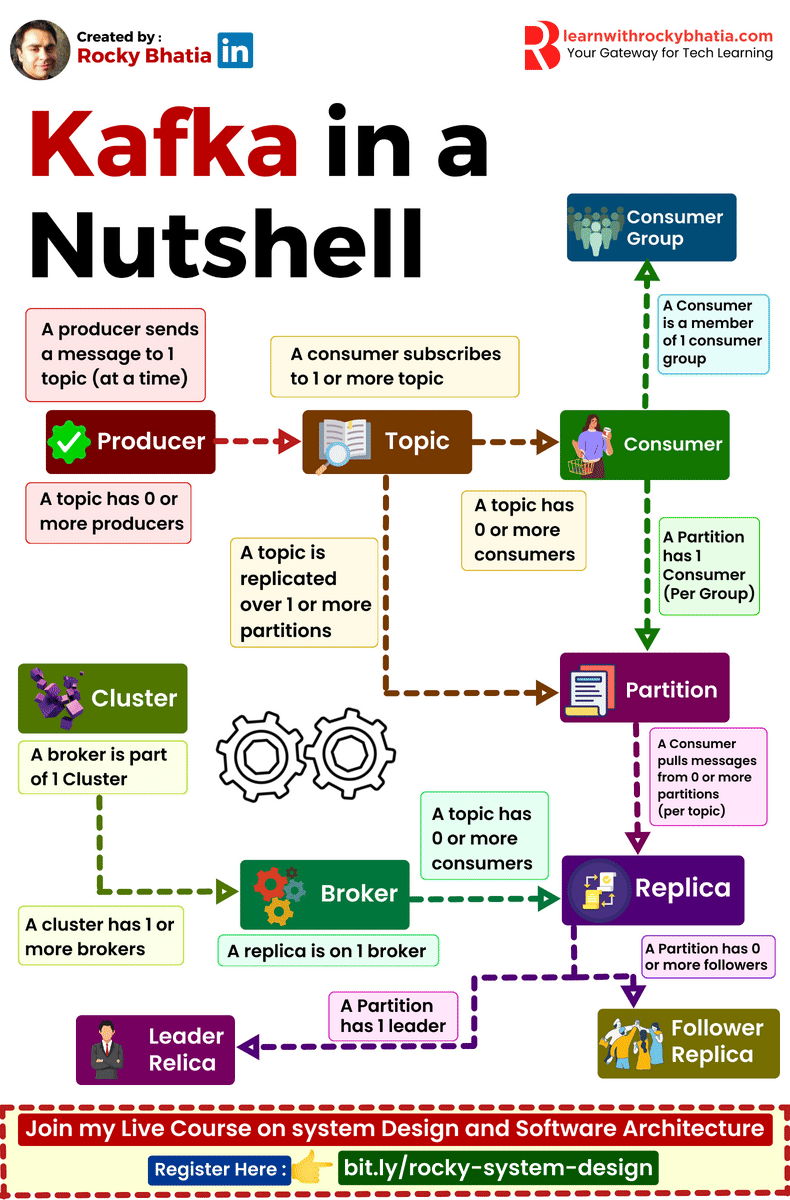
Kafka simplifies real-time data processing and ensures high availability with its robust architecture. Here’s a breakdown of its key components:
🔹 Producer: Initiates data streams, pushing records into Kafka topics for processing. 🔹 Consumer: Receives and processes data from Kafka topics, driving real-time analytics and applications. 🔹 Broker: The core unit of Kafka infrastructure, managing data storage, distribution, and replication. 🔹 Replica: Ensures fault tolerance and data durability by replicating partitions across multiple brokers. 🔹 Cluster: A collection of Kafka brokers working together to handle data streams and ensure high availability. 🔹 Topic: Logical channels for organizing and categorizing data streams in Kafka. 🔹 Partitions: Divides topics into smaller, scalable units, enabling parallel processing and load balancing. 🔹 Leader Replica: Handles read and write operations for a partition, ensuring consistency and reliability. 🔹 Follower Replica: Replicates data from leader replicas, providing redundancy and fault tolerance.
Kafka is designed to make data streaming seamless and efficient, empowering your real-time data analytics and applications.